Papers Explained 128: WizardCoder

WizardCoder empowers Code LLMs (specifically StarCoder) with complex instruction fine-tuning, by adapting the Evol-Instruct method to the domain of code. It surpasses all other open-source Code LLMs by a substantial margin. It even outperforms the largest closed LLMs, Anthropic’s Claude and Google’s Bard, on HumanEval and HumanEval+.
The code, model weights, and data are public at Github.
Recommended Reading [Papers Explained 112: Self Instruct] [Papers Explained 127: WizardLM]
Approach
Following WizardLM, the Evol-Instruct method is applied to evolve Code Alpaca dataset, generated using self-instruct and the pre-trained Code LLM StarCoder is then fine tuned with the evolved data.
Evol-Instruct Prompts for Code
To adapt Evol-Instruct to the realm of code, we made the following modifications to the evolutionary prompt:
- Streamlined the evolutionary instructions by removing deepening, complicating input, and In-Breadth Evolving.
- Simplified the form of evolutionary prompts by unifying the evolutionary prompt template.
- Addressing the specific characteristics of the code domain, two evolutionary instructions are added: code debugging and code time-space complexity constraints.
The unified code evolutionary prompt template is as follows:

Here, {question} represents the current code instruction awaiting evolution, and {method} is the type of evolution. The five types used in the experiments are :

The evolved dataset consists of approximately 78k samples.
Training WizardCoder
StarCoder 15B is used as the foundation and fine-tuned using the evolved training set. The prompt format for fine-tuning is outlined as follows:

The training dataset is initialized with the 20K instruction-following dataset called Code Alpaca. The Evol-Instruct technique is iteratively applied on this dataset to produce evolved data. After each round of data evolution, the evolved data from all previous rounds is merged with the original dataset to finetune StarCoder. The pass@1 metric is observed on HumanEval. Once a decline is observed, the usage of Evol-Instruct is discontinued and the model with the highest pass@1 is selected as the ultimate model.
Evaluation
Evaluation on HumanEval, HumanEval+, and MBPP

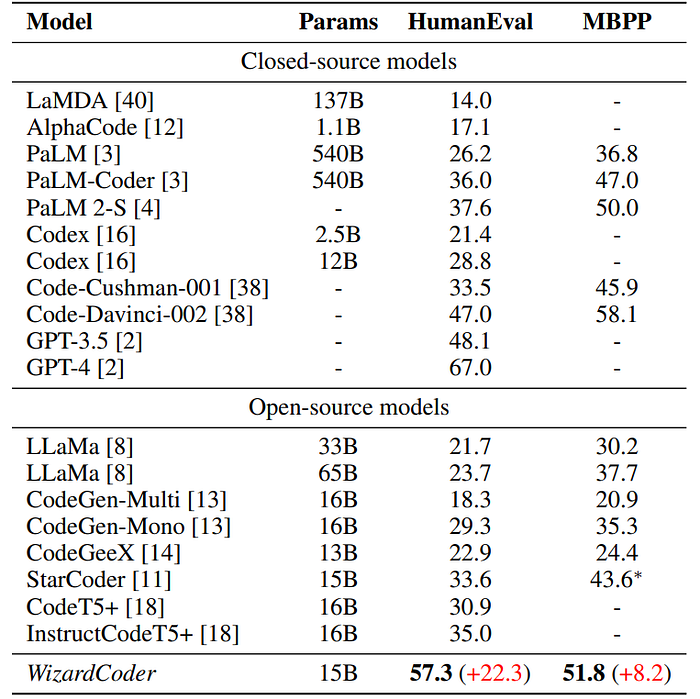
- WizardCoder outperforms the largest closed-source LLMs, including Claude, Bard, PaLM, PaLM-2, and LaMDA, despite being significantly smaller.
- WizardCoder outperforms all the open-source Code LLMs by a large margin (+22.3 on HumanEval), including StarCoder, CodeGen, CodeGee, and CodeT5+.
- WizardCoder significantly outperforms all the open-source Code LLMs with instructions fine-tuning, including InstructCodeT5+, StarCoder-GPTeacher, and Instruct-Codegen-16B.
Evaluation on DS-1000
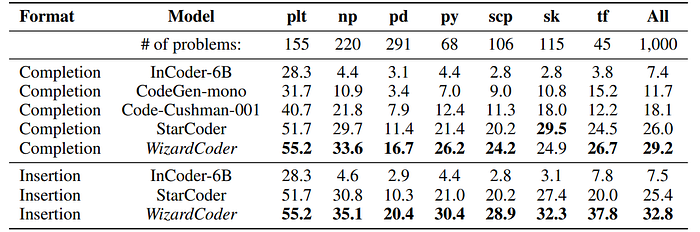
- WizardCoder demonstrates a significant superiority over all other models when tackling data science problems on the DS-1000 benchmark.
- This observation holds true across nearly all data science libraries.
Paper
WizardCoder: Empowering Code Large Language Models with Evol-Instruct 2306.08568
Recommended Reading [Wizard Models]
Hungry for more insights?
Don’t miss out on exploring other fascinating threads in this series. Simply click here and uncover the state-of-the-art research!
Do Subscribe for weekly updates!!
