Papers Explained 112: Self Instruct

Self-Instruct is a framework for improving the instruction-following capabilities of pretrained language models by bootstrapping off their own generations. It provides an almost annotation-free method for aligning pretrained language models with instructions. The code and data are available at https://github.com/yizhongw/self-instruct/.
Method

The Self-Instruct method involves several steps.
First, it generates task instructions using a pre-trained language model (LM) from a set of initial human-written instructions.

Then, it determines if the generated instructions represent classification tasks or not.

Based on the type, it generates instances using an input-first or output-first approach.
In Input-first Approach, the LM is asked to come up with the input fields first based on the instruction, and then produce the corresponding output. This generation order is similar to how models are used to respond to instruction and input.

For classification tasks, Output-first Approach where the possible class labels are generated first, and then the input generation is conditioned on each class label.

Low-quality data is filtered out and diversity is encouraged by adding new instructions only if they’re dissimilar enough from existing ones.
Finally, after generating large-scale instruction data, the original LM is fine-tuned by concatenating the instruction and instance input as a prompt and training the model to generate the instance output in a supervised way, using multiple templates to encode different formats of instructions and inputs.
Self-Instruct Data from GPT3
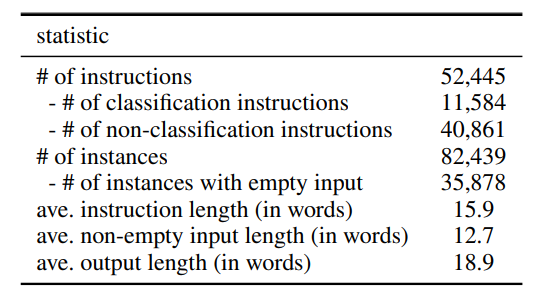
A total of over 52K instructions and more than 82K instances corresponding to these instructions are generated after filtering.
Diversity and Quality of the Generated Instructions
- Verb-noun structures are identified in generated instructions using Berkeley Neural Parser
- Closest verb to the root and its first direct noun object are extracted from parsed instructions
- 26,559 out of 52,445 instructions contain the identified structure; others contain complex clauses or framed as questions

- Top 20 most common root verbs and their top 4 direct noun objects account for 14% of the entire set
- Diversity in intents and textual formats is observed in the instructions
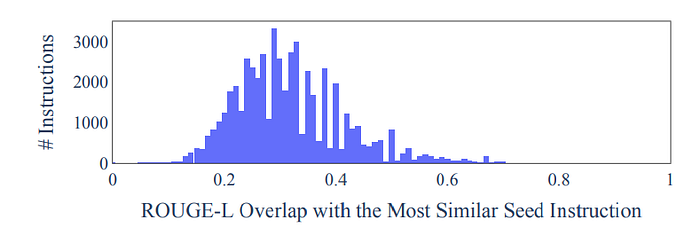
- A comparison is done between generated instructions and seed instructions using ROUGE-L overlap
- Distribution of ROUGE-L scores indicate a significant number of new instructions generated with low overlap with seeds
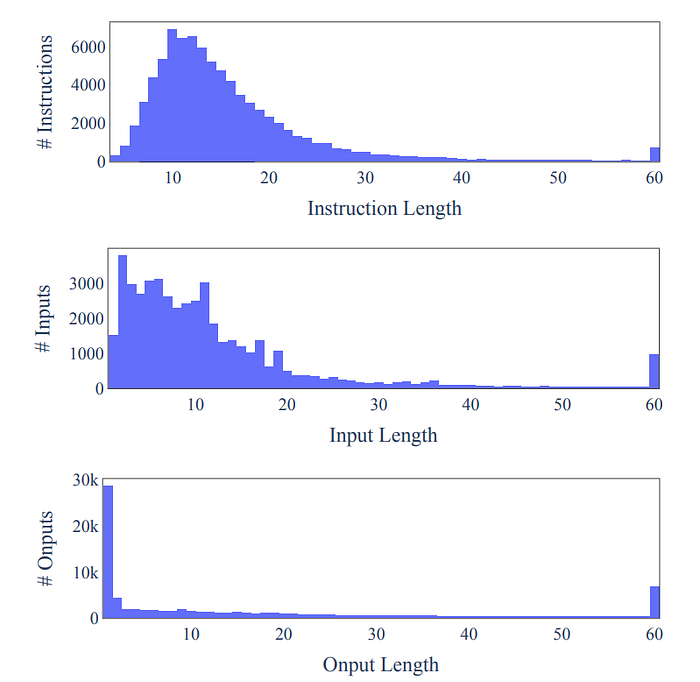
- Diversity is observed in instruction length, instance inputs, and instance outputs.
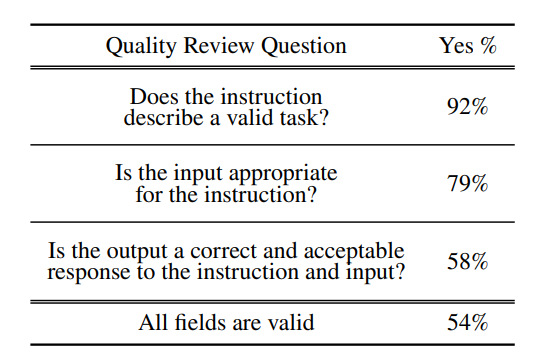
- Most generated instructions are meaningful.
- Generated instances may contain some noise but to a reasonable extent.
- Despite errors, instructions are mostly in the correct or partially correct format.
Experiments
GPT-3 is finetuned using its own instruction data (Self-Instruct Training). The performance of Self-Instruct training with publicly available instruction-tuning data, specifically from PromptSource and SuperNaturalInstructions datasets used to train the T0 and T𝑘-INSTRUCT models. This comparison involves additional fine-tuning of the GPT-3 model using these external datasets.
Zero-Shot Generalization on SUPERNI benchmark
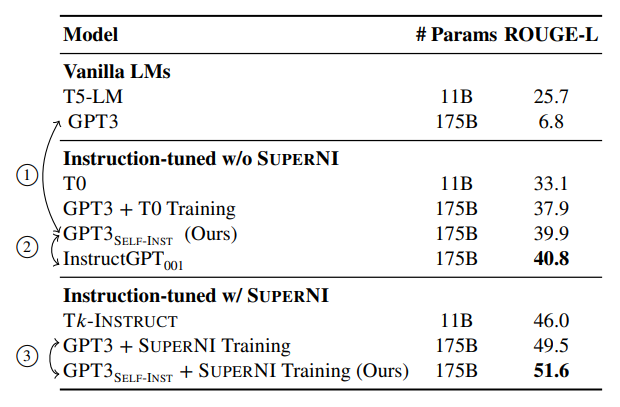
- Self-Instruct can boost GPT3 performance by a large margin (+33.1%)
- It nearly matches the performance of InstructGPT001.
- It can further improve the performance even when a large amount of labeled instruction data is present.
Generalization to User-oriented Instructions on Novel Tasks
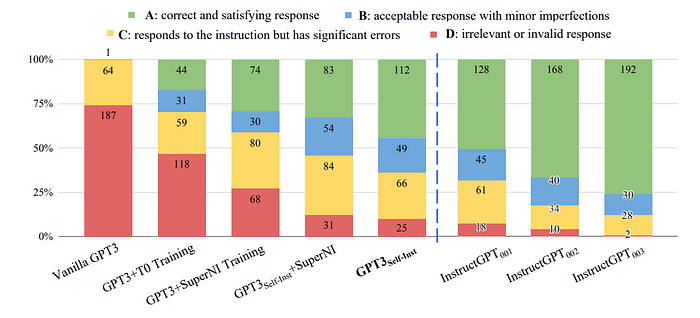
A total of 252 instructions with 1 instance per instruction are created, which serve as a testbed for evaluating how instruction-based models handle diverse and unfamiliar instructions. A four-level rating system: RATING-A to RATING-D based on accuracy and effectiveness is used.
- Vanilla GPT3 struggles with diverse instructions.
- Instruction-tuned models show higher performance.
- GPT3SELF-INST outperforms models trained on T0 or SUPERNI, demonstrating the value of generated data.
- GPT3SELF-INST closely matches InstructGPT001, especially in acceptable responses (RATING-B).
- InstructGPT002 and InstructGPT003 show impressive instruction-following ability.
Effect of Data Size and Quality
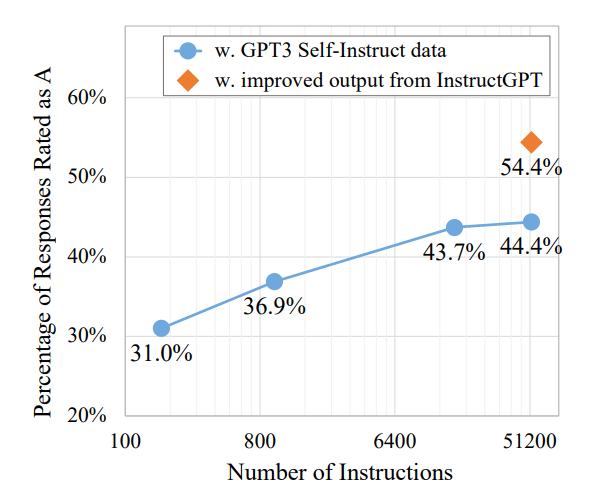
Data Size Analysis
- Sampled different sizes of instructions, fine-tuned GPT3, and evaluated performance on the 252 user-oriented instruction set.
- Consistent improvement with increasing data size, plateauing around 16K instructions.
- Contrast between performance plateauing at hundreds of instructions when evaluating on SUPERNI, suggesting the need for diverse instruction data for better task performance.
Data Quality Enhancement
- Using InstructGPT003, regenerate output given instructions and input to refine the generated data.
- Model fine-tuned with this improved data outperforms the one trained with original data by 10%.
- Indicates significant potential for enhancing data quality through the generation pipeline, either with human expertise or distillation from superior models.
Paper
Self-Instruct: Aligning Language Models with Self-Generated Instructions 2212.10560
Hungry for more insights?
Don’t miss out on exploring other fascinating threads in this series. Simply click here and uncover the state-of-the-art research!
Do Subscribe for weekly updates!!
