Papers Explained 239: SAM 2

Segment Anything Model 2 (SAM 2) is a foundation model designed to solve promptable visual segmentation in images and videos. The model is a simple transformer architecture with streaming memory for real-time video processing. SAM 2 achieves strong performance across various tasks, including:
- In video segmentation: better accuracy than prior approaches using 3× fewer interactions
- In image segmentation: more accurate and 6× faster than the original Segment Anything Model (SAM)
The project is available at GitHub.
Recommended Reading [Papers Explained 238: Segment Anything Model]
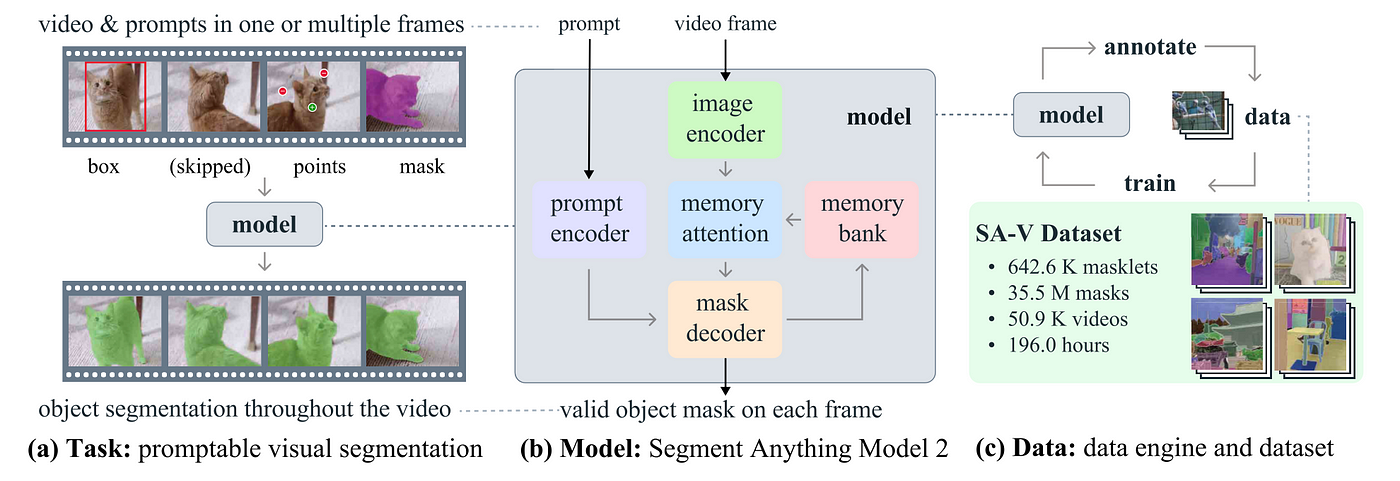
Task: promptable visual segmentation
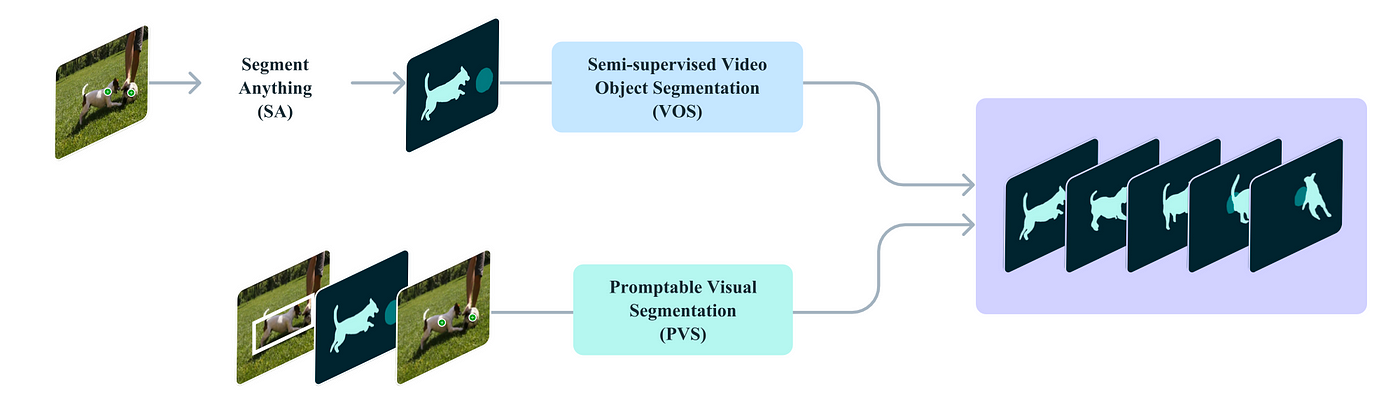
The Promptable Visual Segmentation (PVS) task allows users to provide interactive prompts on any video frame for object segmentation. These prompts can be positive/negative clicks, bounding boxes, or masks, which either define or refine the segmented object. Once a prompt is given, the model responds with an immediate segmentation mask for that frame. After initial prompts, the model propagates these to generate a segmentation mask (masklet) for the object across the entire video. Additional prompts can further refine segmentation at any frame.
PVS extends the Segment Anything (SA) task from static images to videos, allowing interactive prompting on video frames to segment and track objects across the entire video in near real-time. Like SA, PVS focuses on objects with clearly defined boundaries and excludes regions without such boundaries. PVS is similar to SA but applied to video and relates to tasks like semi-supervised and interactive video object segmentation (VOS), though it offers more flexible prompting methods (clicks, masks, boxes) for easier refinement with minimal interaction.
Model

SAM 2 is a generalization of SAM to the video (and image) domain. It supports point, box, and mask prompts on individual frames to define the spatial extent of the object to be segmented across the video. For image input, the model behaves similarly to SAM. A promptable and light-weight mask decoder accepts a frame embedding and prompts (if any) on the current frame and outputs a segmentation mask for the frame. Prompts can be iteratively added on a frame in order to refine the masks.
Unlike SAM, the frame embedding used by the SAM 2 decoder is not directly from an image encoder and is instead conditioned on memories of past predictions and prompted frames. It is possible for prompted frames to also come “from the future” relative to the current frame. Memories of frames are created by the memory encoder based on the current prediction and placed in a memory bank for use in subsequent frames. The memory attention operation takes the per-frame embedding from the image encoder and conditions it on the memory bank to produce an embedding that is then passed to the mask decoder.
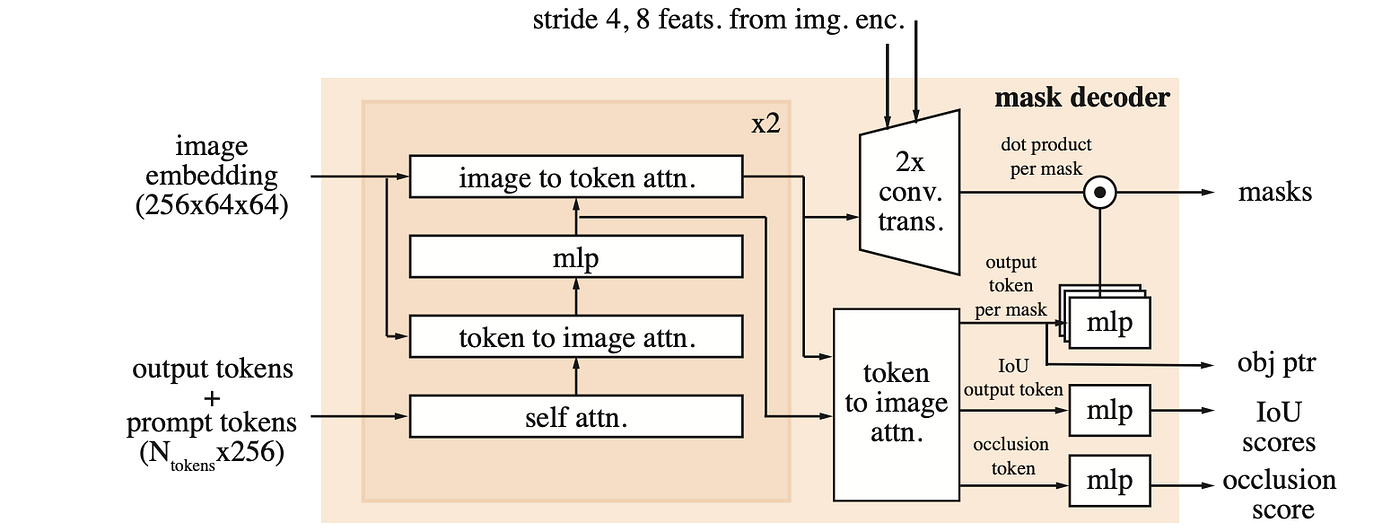
Image Encoder
The SAM2 image encoder uses a pre-trained MAE Hiera model, which is hierarchical and allows for multiscale features during decoding. The feature pyramid network fuses the stride 16 and 32 features from Stages 3 and 4 of the Hiera image encoder to produce image embeddings for each frame.
The stride 4 and 8 features from Stages 1 and 2 are not used in memory attention but are added to upsampling layers in the mask decoder, which helps produce high-resolution segmentation details.
The Hiera image encoder uses windowed absolute positional embeddings instead of relative positional encoding. The global positional embedding is interpolated across windows instead of using RPB.
The model is trained with varying image encoder sizes (T, S, B+, and L) and uses global attention in only a subset of the image encoder layers.
Memory attention
The memory attention mechanism in SAM2 conditions current frame features on past frames’ features and predictions, as well as new prompts. This process involves stacking L transformer blocks, where each block performs:
- Self-attention: processing the input (image encoding from the current frame)
- Cross-attention: attending to memories of prompted/unprompted frames and object pointers stored in a memory bank
- MLP (Multi-Layer Perceptron): applying an MLP layer after self- and cross-attention
The attention operations used are vanilla attention, which allows for benefits from recent developments in efficient attention kernels.
Additionally, SAM2 uses:
- Sinusoidal absolute positional embeddings: to capture temporal information
- 2D spatial Rotary Positional Embedding (RoPE): in self-attention and cross-attention layers, excluding object pointer tokens that lack specific spatial correspondence
By default, the memory attention uses L = 4 layers.
Prompt encoder and mask decoder
The prompt encoder is identical to SAM’s and can be prompted by clicks (positive or negative), bounding boxes, or masks. Sparse prompts are represented by positional encodings summed with learned embeddings for each prompt type, while masks are embedded using convolutions and summed with the frame embedding.
The mask decoder design largely follows SAM. It stacks “two-way” transformer blocks that update prompt and frame embeddings. For ambiguous prompts (e.g., a single click), where there may be multiple compatible target masks, the model predicts multiple masks to ensure valid outputs. In video, this means predicting multiple masks on each frame.
To handle ambiguity in videos, SAM2 predicts multiple masks at each step of the video. If further prompts do not resolve the ambiguity, the model selects the mask with the highest predicted IoU for the current frame for further propagation in the video.
SAM2 introduces an occlusion prediction head to account for the possibility that no valid object may exist on some frames (e.g., due to occlusion). This is accomplished by including an additional token along with the mask and IoU output tokens, which is then processed by an MLP head to produce a score indicating the likelihood of the object being visible in the current frame.
To incorporate high-resolution information for mask decoding, SAM2 uses skip connections from the hierarchical image encoder (bypassing the memory attention).
The mask token corresponding to the output mask is used as the object pointer token for the frame, which is placed in the memory bank.
Memory encoder and memory bank
The SAM2 Memory system consists of a Memory Encoder and a Memory Bank that work together to store and utilize information about past predictions and prompts for object segmentation in videos.
The Memory Encoder takes the output mask from the decoder and down samples it using a convolutional module. It then element-wise sums the downsampled mask with the unconditioned frame embedding from the image encoder, and applies lightweight convolutional layers to fuse the combined information.
The Memory Bank maintains two FIFO queues: Recent Frames, which stores up to N recent frames’ memories as spatial feature maps; and Prompted Frames, which stores up to M prompted frames’ memories as spatial feature maps. It also stores a list of lightweight vectors representing high-level semantic information about the object to segment, based on mask decoder output tokens.
The Memory Bank embeds temporal position information into the memories of N recent frames to represent short-term object motion. This is not applied to prompted frames due to sparser training signals and generalization challenges.
The cross-attention mechanism in the memory attention mechanism cross-attends to both spatial memory features and object pointers.
Memory features are projected to a dimension of 64, while the 256-dim object pointer is split into 4 tokens of 64-dim for cross-attention with the memory bank.
The Memory Encoder reuses the image embeddings produced by the Hiera encoder, which are fused with predicted mask information to generate memory features. This leverages the strong representations of the image encoder and allows for scaling to larger image encoder sizes.
Data
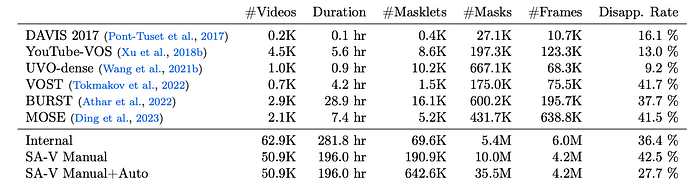
To develop the capability to “segment anything” in video, a data engine is built to collect a large and diverse video segmentation dataset.
The SA-V dataset collected with the data engine comprises 50.9K videos with 642.6K masklets.
Training Details
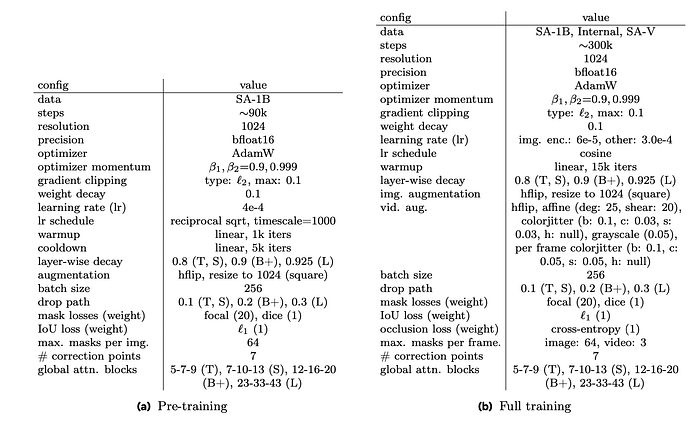
Pre-training
SAM 2 is first pre-trained on static images from the SA-1B dataset. Similar to SAM, masks covering more than 90% of the image are filtered out, and training is restricted to 64 randomly sampled masks per image.
Unlike SAM, it is found beneficial to use an l1 loss to more aggressively supervise IoU predictions and to apply a sigmoid activation to the IoU logits to restrict the output into the range between 0 and 1. For multi-mask predictions (on the first click), IoU predictions of all masks are supervised to encourage better learning of when a mask might be bad, but only the mask logits with the lowest segmentation loss (linear combination of focal and dice loss) are supervised.
During training, horizontal flip augmentation is employed, and the image is resized to a square size of 1024×1024.
Full training
After pre-training, SAM 2 is trained on introduced datasets SA-V + Internal, a 10% subset of SA-1B, and a mixture of open-source video datasets including DAVIS, MOSE, and YouTubeVOS . The released model is trained on SA-V manual + Internal and SA-1B.
SAM 2 is designed for two tasks: the PVS task (on videos) and the SA task (on images). Training is done jointly on image and video data. To optimize data usage and computational resources during training, an alternating training strategy between video data (multiple frames) and static images (one single frame) is adopted. Specifically, in each training iteration, a full batch is sampled either from the image or video dataset, with their sampling probabilities proportional to the size of each data source. This approach allows for a balanced exposure to both tasks and a different batch size for each data source to maximize compute utilization.
The training data mixture consists of approximately 15.2% SA-1B, 70% SA-V, and 14.8% Internal. The same settings are used when open-source datasets are included, with the change that the additional data is included: approximately 1.3% DAVIS, 9.4% MOSE, 9.2% YouTubeVOS, 15.5% SA-1B, 49.5% SA-V, and 15.1% Internal.
Training is done by simulating an interactive setting, sampling 8-frame sequences and randomly selecting up to 2 frames (including the first) for corrective clicks. During training, ground-truth masklets and model predictions are used to sample prompts, with initial prompts being the ground-truth mask (50% probability), a positive click from the ground-truth mask (25%), or a bounding box input (25%).
The maximum number of masklets for each sequence of 8 frames is restricted to 3 randomly chosen ones. The temporal order is reversed with a probability of 50% to help generalization to bi-directional propagation. When corrective clicks are sampled — with a small probability of 10%, they are randomly sampled from the ground truth mask, irrespective of the model prediction, to allow additional flexibility in mask refinement.
Losses and optimization The model’s predictions are supervised using a linear combination of focal and dice losses for the mask prediction, mean-absolute-error (MAE) loss for the IoU prediction, and cross-entropy loss for object prediction with a ratio of 20:1:1:1 respectively.
Evaluations
Video tasks
To evaluate and improve promptable video segmentation, a simulation was designed where a model refines its output based on user feedback (clicks). Two evaluation settings were used: offline, which involved multiple passes through a video to select frames for interaction based on model error; and online, which required a single pass through the video with frame annotation. Nine densely annotated zero-shot video datasets were utilized, with N_click set at 3 clicks per frame.
Two baselines were established: SAM+XMem++, which combined SAM with the XMem++ video object segmentation model; and SAM+Cutie, which modified the Cutie model to accept mask inputs on multiple frames.

- SAM 2 outperforms both baselines (SAM+XMem++ and SAM+Cutie) in both offline and online evaluation settings.
- SAM 2 achieves higher J & F accuracy across all 9 datasets, demonstrating its ability to generate high-quality video segmentation with fewer user interactions ( >3× fewer).
To evaluate the performance of SAM 2 in a semi-supervised video object segmentation (VOS) setting using click, box, or mask prompts on the first frame of a video, interactive sampling of 1, 3, or 5 clicks on the first frame was performed for click prompts. Additionally, comparisons were made with XMem++ and Cutie using SAM for click and box prompts, and their default settings for mask prompts.

- SAM 2 outperforms both XMem++ and Cutie on 17 datasets across various input prompts (click, box, mask).
Image tasks

- SAM 2 achieves higher accuracy (58.9 mIoU with 1 click) than SAM (58.1 mIoU with 1 click) on the 23 datasets previously used for SAM evaluation, while being 6x faster.
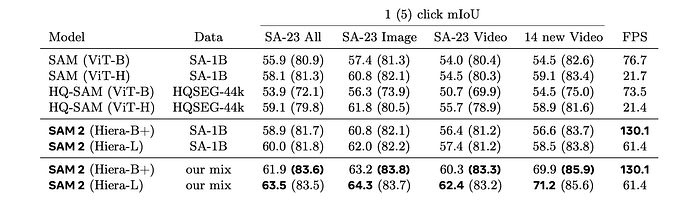
- SAM 2 (Hiera-B+) outperforms SAM (ViT-H) and HQ-SAM (ViT-H) on both 1-click and 5-click accuracy while being 6x faster.
- SAM 2 (Hiera-L) further improves 1-click accuracy but trades off speed.
- Training on the mix of image and video data boosts average accuracy to 61.4% across the 23 datasets.
- Significant improvements are observed on both SA-23 video benchmarks and the 14 newly introduced video datasets.
Comparison to state-of-the-art in semi-supervised VOS
SAM 2 is evaluated on both general and semi-supervised VOS tasks. Two versions of SAM 2 are presented, using different image encoder sizes (Hiera-B+ and Hiera-L) to balance speed and accuracy.
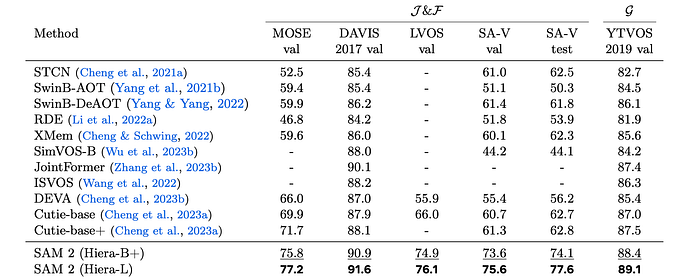
- SAM 2 achieves real-time speeds of 43.8 FPS (Hiera-B+) and 30.2 FPS (Hiera-L).
- SAM 2 outperforms existing state-of-the-art methods significantly.
- Larger image encoders lead to substantial accuracy improvements.
- SAM 2 demonstrates notable gains on the SA-V benchmark for open-world object segmentation and the LVOS benchmark for long-term video object segmentation.
Paper
SAM 2: Segment Anything in Images and Videos
Recommended Reading: [Object Detection]
Hungry for more insights?
Don’t miss out on exploring other fascinating threads in this series. Simply click here and uncover the state-of-the-art research!
Do Subscribe for weekly updates!!
