Papers Explained 238: Segment Anything Model

The Segment Anything (SA) project aims to build a foundation model for segmentation by introducing three interconnected components: a promptable segmentation task, a segmentation model (SAM) that powers data annotation and enables zero-shot transfer to a range of tasks via prompt engineering, and a data engine for collecting SA-1B, a dataset of over 1 billion masks.
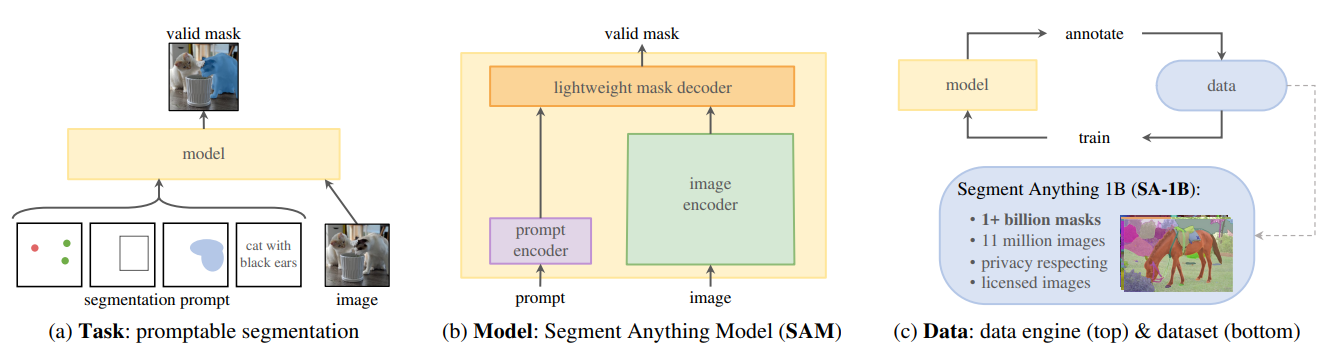
Segment Anything Task
This approach draws inspiration from NLP’s token prediction to establish a foundation for segmentation tasks. Similar to NLP prompts, here, prompts guide the segmentation process, which can encompass foreground / background points, rough boxes / masks, or textual descriptions indicating the desired segment in an image.
Task Definition: Promptable segmentation involves generating a valid segmentation mask based on a given prompt, even when the prompt is ambiguous and could refer to multiple objects.
Pre-training Algorithm: The proposed pre-training method involves simulating prompts (e.g., points, boxes, masks) during training and comparing the model’s mask predictions against ground truth. This contrasts with interactive segmentation where user input refines the mask prediction.
Zero-Shot Transfer: The pre-trained model’s ability to respond to various prompts enables zero-shot transfer to downstream tasks. Different segmentation tasks can be achieved by engineering appropriate prompts.
Segment Anything Model

SAM has three components an image encoder, a flexible prompt encoder, and a fast mask decoder.
Image Encoder
SAM employs an MAE pre-trained Vision Transformer (ViT), minimally adapted to process high resolution inputs. The image encoder runs once per image and can be applied prior to prompting the model.
Prompt Encoder
Two sets of prompts are being considered: sparse (points, boxes, text) and dense (masks). Points and boxes are represented by positional encodings, which are summed with learned embeddings for each prompt type, and free-form text is represented using an off-the-shelf text encoder from CLIP. Dense prompts (i.e., masks) are embedded using convolutions and summed element-wise with the image embedding.
Mask Decoder
The mask decoder efficiently generates masks from image and prompt embeddings, along with an output token. This design draws inspiration from Transformer decoder blocks and incorporates prompt self-attention and cross-attention in multiple directions. The output token is mapped to a dynamic linear classifier through an MLP, which computes the mask foreground probability at each image location.
Ambiguity Resolution: To handle ambiguity, SAM predicts multiple output masks for a single prompt, enhancing the model’s ability to address common cases of nested masks. During training, a confidence score is assigned to each mask to rank their quality.
Losses and Training: The model’s mask prediction is supervised using a combination of focal loss and dice loss. Training involves a mixture of geometric prompts and an interactive setup with multiple rounds of randomly sampled prompts per mask.
Segment Anything Data Engine
The Segment Anything Data Engine enabled the collection of the 1.1B mask dataset, SA-1B. The data engine has three stages: (1) a model-assisted manual annotation stage, (2) a semi-automatic stage with a mix of automatically predicted masks and model-assisted annotation, and (3) a fully automatic stage in which the model generates masks without annotator input.
Assisted-Manual Stage:
A team of professional annotators labeled masks interactively using a browser-based tool, supported by an underlying model (SAM).
The model-assisted annotation was integrated into the browser interface, allowing real-time guidance based on precomputed image embeddings.
Annotators freely labeled various objects without semantic constraints, prioritizing prominent objects.
SAM’s training began with existing public datasets, and it was retrained using newly annotated masks.
Annotation time reduced from 34 to 14 seconds per mask as SAM improved, resulting in 4.3 million masks from 120k images.
Semi-Automatic Stage:
To enhance mask diversity, confident masks were automatically detected and presented to annotators for further annotation.
Annotators focused on labeling less prominent objects using the provided masks as a starting point.
An additional 5.9 million masks were collected, bringing the total to 10.2 million masks.
Model retraining occurred periodically with the newly collected data.
Average annotation time increased to 34 seconds due to the complexity of objects.
The average number of masks per image rose to 72.
Fully Automatic Stage
The annotation process became entirely automatic through two key model improvements.
Accumulated diverse masks and an ambiguity-aware model enabled confident mask prediction even in ambiguous cases.
A 32×32 point grid initiated mask predictions, with IoU-based selection and non-maximal suppression for mask filtering.
Automatic mask generation was applied to the entire dataset of 11 million images, resulting in 1.1 billion high-quality masks.
Segment Anything Dataset
The SA-1B dataset, designed to aid the development of foundational models for computer vision, comprises 11 million high-resolution images and 1.1 billion segmentation masks. These images are licensed, diverse, and privacy-protected. To facilitate accessibility, downsampled images are released, with the shortest side set at 1500 pixels. Despite downsampling, the images remain notably higher in resolution compared to existing datasets. Notably, SA-1B includes automatically generated masks, produced by a data engine, with a focus on mask quality. Comparisons with professional annotations demonstrate that 94% of automatically generated masks exhibit over 90% Intersection over Union (IoU) with professionally corrected counterparts. The dataset’s spatial distribution of object centers is analyzed, revealing different biases compared to other datasets. In terms of scale, SA-1B stands out with significantly more images and masks than other datasets. The distribution of masks per image, relative mask sizes, and mask concavity are also explored and found to align with patterns seen in other datasets.



Experiments
Zero-Shot Single Point Valid Mask Evaluation

(a) Mean IoU of SAM and the strongest single point segmenter, RITM [92]. Due to ambiguity, a single mask may not match ground truth; circles show “oracle” results of the most relevant of SAM’s 3 predictions.
(b) Per-dataset comparison of mask quality ratings by annotators from 1 (worst) to 10 (best). All methods use the ground truth mask center as the prompt.
(c, d) mIoU with varying number of points. SAM significantly outperforms prior interactive segmenters with 1 point and is on par with more points. Low absolute mIoU at 1 point is the result of ambiguity.
Zero-Shot Edge Detection

Even though SAM was not trained for edge detection, it produces reasonable edge maps. Compared to the ground truth, SAM predicts more edges, including sensible ones that are not annotated in BSDS500.
Zero-Shot Object Proposals
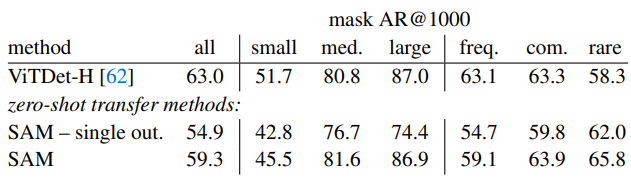
Unsurprisingly using the detections from ViTDet-H as object proposals performs the best overall. However, SAM does remarkably well on several metrics. Notably, it outperforms ViTDet-H on medium and large objects, as well as rare and common objects. An ablated ambiguity unaware version of SAM (“single out.”), is also comapred, which performs significantly worse than SAM on all AR metrics.
Zero-Shot Instance Segmentation
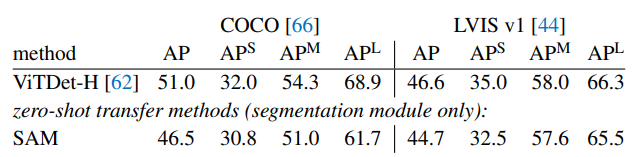
SAM is prompted with ViTDet boxes to do zero-shot segmentation. The fullysupervised ViTDet outperforms SAM, but the gap shrinks on the higher-quality LVIS masks.

Despite its lower AP, SAM has higher ratings than ViTDet, suggesting that ViTDet exploits biases in the COCO and LVIS training data.
Zero-Shot Text-to-Mask
Qualitative results are shown, SAM can segment objects based on simple text prompts like “a wheel” as well as phrases like “beaver tooth grille”. When SAM fails to pick the right object from a text prompt only, an additional point often fixes the prediction.
Paper
Segment Anything 2304.02643
Recommended Reading: [Object Detection]
Hungry for more insights?
Don’t miss out on exploring other fascinating threads in this series. Simply click here and uncover the state-of-the-art research!
Do Subscribe for weekly updates!!
