Papers Explained 229: Efficient ViT

Efficient Vit employs a new building block with a sandwich layout, i.e., using a single memory-bound MHSA between efficient FFN layers. This layout improves memory efficiency while enhancing channel communication. Additionally, it utilizes a cascaded group attention module to feed attention heads with different splits of the full feature. This not only saves computation costs but also improves attention diversity. Lastly, it incorporates a parameter reallocation strategy, which focuses on improving model efficiency in terms of memory, computation, and parameters, respectively.

Sandwich Layout
It applies a single self-attention layer Φ^A_i for spatial mixing, which is sandwiched between FFN layers Φ^F_i . The computation can be formulated as:

where Xi is the full input feature for the i-th block. The block transforms Xi into Xi+1 with N FFNs before and after the single self-attention layer. This design reduces the memory time consumption caused by self-attention layers in the model, and applies more FFN layers to allow communication between different feature channels efficiently. An extra token interaction layer is also applied before each FFN using a depthwise convolution. It introduces inductive bias of the local structural information to enhance model capability.
Cascaded Group Attention
Cascaded Group Attention feeds each head with different splits of the full features, thus explicitly decomposing the attention computation across heads. Formally, this attention can be formulated as:

where the j-th head computes the self-attention over Xij , which is the j-th split of the input feature Xi , i.e., Xi = [Xi1, Xi2, . . . , Xih] and 1 ≤ j ≤ h. h is the total number of heads, W^Q_ij , W^K_ij , and W^V_ij are projection layers mapping the input feature split into different subspaces, and W^P_i is a linear layer that projects the concatenated output features back to the dimension consistent with the input.
Parameter Reallocation
To improve parameter efficiency, the parameters in the network are reallocated by expanding the channel width of critical modules while shrinking the unimportant ones. Small channel dimensions are set for Q and K projections in each head for all stages. For the V projection, it is allowed to have the same dimension as the input embedding. The expansion ratio in the FFN is also reduced from 4 to 2 due to its parameter redundancy.
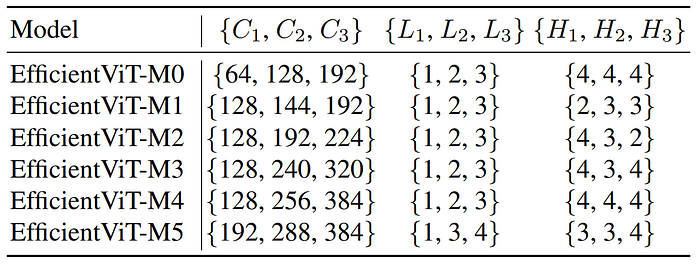
EfficientViT Network Architectures
The architecture contains three stages. Each stage stacks the proposed EfficientViT building blocks and the number of tokens is reduced by 4× at each subsampling layer (2× subsampling of the resolution).
To achieve efficient subsampling, an EfficientViT subsample block is proposed, which also has the sandwich layout, except that the self-attention layer is replaced by an inverted residual block to reduce information loss during subsampling.
BatchNorm (BN) is chosen to be adopted throughout the model instead of LayerNorm (LN), as BN can be incorporated into the preceding convolution or linear layers, providing a runtime advantage over LN.
ReLU is employed as the activation function, as the commonly used GELU or HardSwish functions are found to be significantly slower.
Evaluation
Image Classification
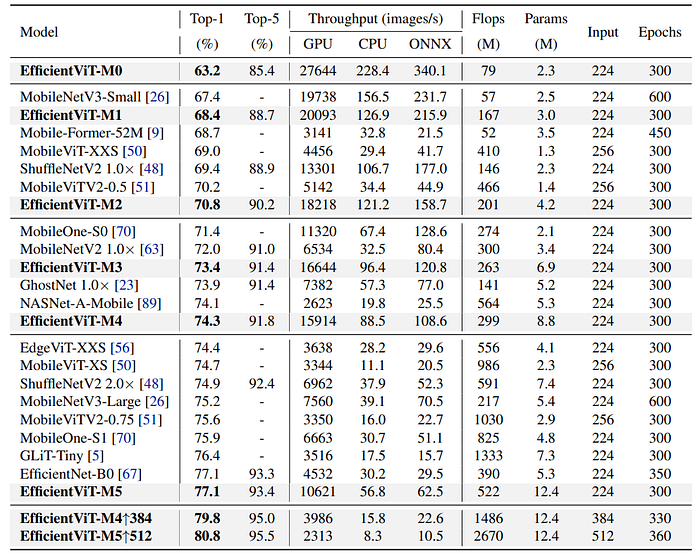
- EfficientViT outperforms both efficient CNNs and ViT models on ImageNet in terms of accuracy and speed trade-off.
- EfficientViT-M3 is 1.4% more accurate than MobileNetV2 1.0× and runs 2.5× faster on V100 GPU and 3.0× faster on Intel CPU.
- EfficientViT-M5 achieves 1.9% higher accuracy than MobileNetV3-Large and is significantly faster, particularly on GPUs and Intel CPUs.
- EfficientViT-M5 is also comparable in accuracy to EfficientNet-B0 but runs 2.3×/1.9× faster on V100 GPU/Intel CPU and 2.1× faster as ONNX models.
- Although EfficientViT uses more parameters, it reduces memory-inefficient operations, resulting in higher throughput and improved inference speed.
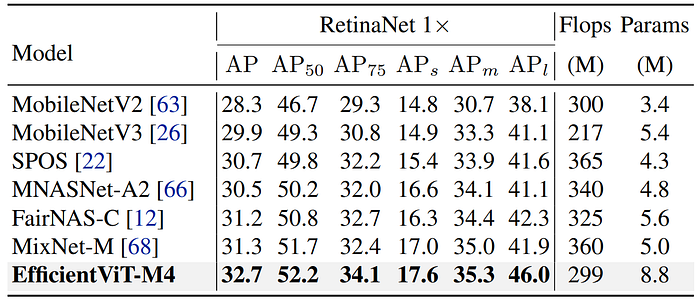
- EfficientViT-M4 outperforms MobileNetV2 by 4.4% in Average Precision (AP) while having similar computational complexity (Flops).
- Compared to SPOS, EfficientViT-M4 achieves 2.0% higher AP with 18.1% fewer Flops, indicating its versatility and effectiveness in various vision tasks.
Paper
EfficientViT: Memory Efficient Vision Transformer with Cascaded Group Attention 2305.07027
Recommended Reading [Vision Transformers]
Hungry for more insights?
Don’t miss out on exploring other fascinating threads in this series. Simply click here and uncover the state-of-the-art research!
Do Subscribe for weekly updates!!
