Nov 12, 2024
16 stories
10 saves
A shape-optimized vision transformer that achieves competitive results with models twice its size, while being pre-trained with an equivalent amount of compute.


Employs a single memory-bound MHSA between efficient FFN layers, improves memory efficiency while enhancing channel communication.


A hybrid vision transformer architecture featuring a novel token mixing operator called RepMixer, which significantly improves model efficiency.


Revisits the design principles of ViT and its variants through latency analysis and identifies inefficient designs and operators in ViT to propose a new dimension consistent design paradigm for vision transformers and a simple yet effective latency-driven slimming method to optimize for inference speed.


A successor to Swin Transformer, addressing challenges like training stability, resolution gaps, and labeled data scarcity.


Introduces multi-axis attention, allowing global-local spatial interactions on arbitrary input resolutions with only linear complexity.


Demonstrates that existing self-supervised pre-training methods can produce general-purpose visual features by training on curated data from diverse sources, and proposes a new approach that combines techniques to scale pre-training with larger models and datasets.


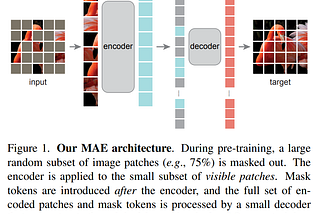
An encoder-decoder architecture that reconstructs input images by masking random patches and leveraging a high proportion of masking for self-supervision.
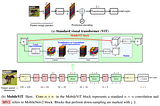
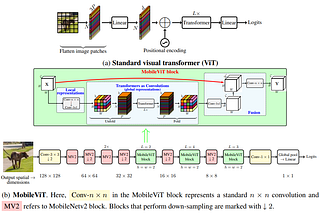
A lightweight vision transformer designed for mobile devices, effectively combining the strengths of CNNs and ViTs.
Utilizes a masked image modeling task inspired by BERT in, involving image patches and visual tokens to pretrain vision Transformers.
A hybrid neural network built upon the ViT architecture and DeiT training method, for fast inference image classification.


Investigates whether self-supervised learning provides new properties to Vision Transformer that stand out compared to convolutional networks and finds that self-supervised ViT features contain explicit information about the semantic segmentation of an image, and are also excellent k-NN classifiers.


Improves Vision Transformer (ViT) in performance and efficiency by introducing convolutions, to yield the best of both designs.


A hierarchical vision transformer that uses shifted windows to addresses the challenges of adapting the transformer model to computer vision.
A convolution-free vision transformer that uses a teacher-student strategy with attention-based distillation tokens.
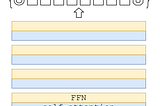
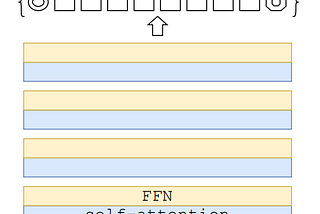
Images are segmented into patches, which are treated as tokens and a sequence of linear embeddings of these patches are input to a Transformer.