Papers Explained 215: Swin Transformer V2

Swin Transformer v2 explores large-scale models in computer vision, addressing challenges like training stability, resolution gaps, and labeled data scarcity. It introduces techniques including residual-post-norm with cosine attention, log-spaced continuous position bias, and self-supervised pretraining (SimMIM). These methods resulted in a 3B parameter model, achieving exceptional results on image-related tasks.
Swin Transformer
The main idea of Swin Transformer is to introduce several important visual priors into the vanilla Transformer encoder, including hierarchy, locality, and translation invariance, which combines the strength of both: the basic Transformer unit has strong modeling capabilities, and the visual priors make it friendly to a variety of visual tasks.
Normalization
Swin Transformer uses a prenormalization configuration similar to the Language Transformers & ViT as it is essential for training stability.
Relative Position Bias
The original Swin Transformer employs a relative position bias term in self-attention calculations to capture spatial relationships between visual elements, using a parametric bias matrix B to adjust attention scores. This bias is crucial for tasks like object detection and can be transferred across window sizes during pre-training and fine-tuning by interpolation.
Issues in scaling up model capacity and window resolution
- An instability issue when scaling up model capacity.
- Degraded performance when transferring models across window resolutions.
Swin Transformer V2

Scaling Up Model Capacity
The original Swin Transformer and many other vision Transformers use a layer normalization at the beginning of each block. However, as the model’s capacity increases, there is a noticeable increase in activation values at deeper layers. This means that the magnitude of the intermediate activations becomes significantly larger as information flows through the network. This can lead to training instability.
Post normalization
In this approach, the output of each residual block is first normalized before being merged back into the main branch. This prevents the amplitude accumulation in the main branch as the layers go deeper.
For further stability in the largest model, an extra layer normalization is introduced on the main branch every 6 Transformer blocks.
Scaled cosine attention
In the original self-attention computation, the similarity between pixel pairs is calculated using a dot product of query and key vectors. However, in larger models, some attention maps become dominated by a few pixel pairs, leading to imbalanced attention distributions.
Hence a scaled cosine attention approach is used. It computes the attention logit of a pixel pair i and j by a scaled cosine function:

where Bij is the relative position bias between pixel i and j; τ is a learnable scalar, non-shared across heads and layers. τ is set larger than 0.01.
Scaling Up Window Resolution
Continuous relative position bias
Instead of directly optimizing the parameterized biases, The continuous relative position bias employs a small meta network, G, operating on relative coordinates, enabling bias values for different positions to be generated and transferred to various tasks, enhancing adaptability, while retaining similarity with the original parameterized bias approach during inference.
Log-spaced coordinates
To accommodate varying window sizes more effectively, log-spaced coordinates are proposed, allowing for smaller extrapolation ratios during the transfer of relative position biases across different resolutions. This log-spacing significantly reduces extrapolation ratios compared to linear-spacing, leading to enhanced performance in transferring position biases, particularly for larger window sizes.
To mitigate the data hunger of larger vision models, Swin Transformer V2 employs a self-supervised pre-training method called SimMIM, enabling successful training of a 3B model using just 1/40th (70 million) of the labeled images from JFT-3B, achieving state-of-the-art performance on four significant visual benchmarks.
Model Configurations
The stage, block, and channel settings of the original Swin Transformer are maintained for four configurations of Swin Transformer V2:
- SwinV2-T: C = 96, #. block = {2, 2, 6, 2}
- SwinV2-S/B/L: C=96/128/192, #.block={2, 2, 18, 2}
- SwinV2-H: C = 352, #. block = {2, 2, 18, 2}
- SwinV2-G: C = 512, #. block = {2, 2, 42, 4}
- with C the number of channels in the first stage.
Experiments
Image classification
ImageNet-1K V1 and V2 val are used for evaluation. ImageNet-22K which
has 14M images and 22K categories is optionally employed for pre-training. For pre-training SwinV2-G, a privately collected ImageNet22K-ext dataset with 70 million images is used after deduplication.
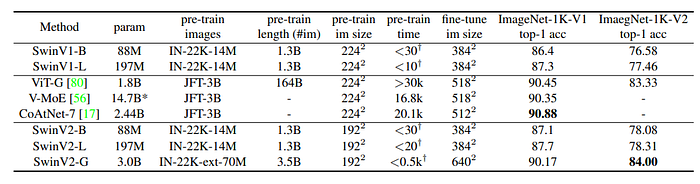
- SwinV2-G surpasses the previous best by +0.7% on ImageNet V2.
- SwinV2-B and SwinV2-L show gains of +0.8% and +0.4% compared to the original SwinV1 models, suggesting potential limits to the gains as model size increases.
Object detection
COCO is used for evaluation. For the largest model experiments, an additional detection pre-training phase is employed using the Object 365 v2 dataset, positioned between the image classification pretraining phase and the COCO fine-tuning phase.
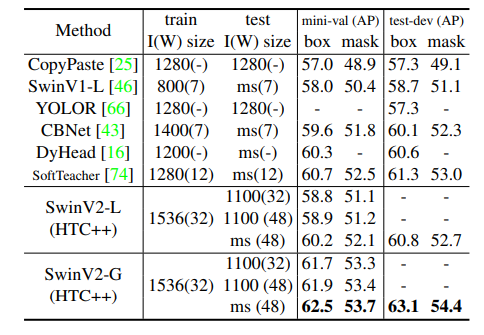
- SwinV2-G model outperforms previous best results on COCO object detection and instance segmentation by +1.8/1.4.
- Scaling up vision models is advantageous for dense vision recognition tasks like object detection.
Semantic segmentation
ADE20K is used.
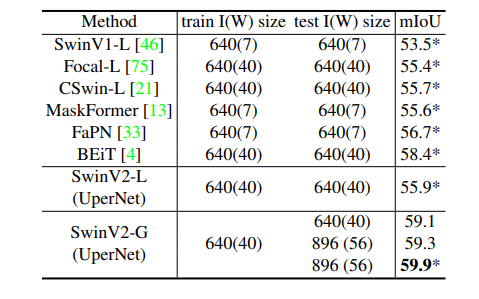
- SwinV2-G model outperforms previous best results on ADE20K semantic segmentation benchmark by 1.5 point.
- Scaling up vision models benefits pixel-level vision recognition tasks.
- Utilizing a larger window size during testing contributes to an additional +0.2 gain, likely due to the effective Log-spaced CPB approach.
Video action classification.
Kinetics-400 (K400) is used in evaluation.
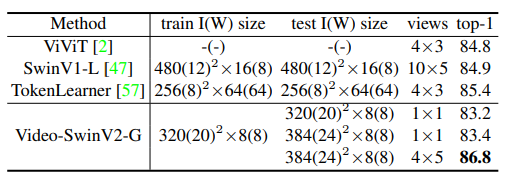
- SwinV2-G model achieves 86.8% top-1 accuracy on Kinetics-400 action classification, surpassing the previous best result by +1.4%, indicating the efficacy of scaling up vision models.
- Scaling up vision models can lead to improved performance in video recognition tasks.
- The use of a larger window size during test time can result in an additional benefit of +0.2% accuracy, likely due to the effective Log-spaced CPB approach.
Paper
Swin Transformer V2: Scaling Up Capacity and Resolution 2111.09883
Recommended Reading [Vision Transformers]
Hungry for more insights?
Don’t miss out on exploring other fascinating threads in this series. Simply click here and uncover the state-of-the-art research!
Do Subscribe for weekly updates!!
