Papers Explained 201: SimCLRv2

The study proposes a semi-supervised learning framework that combines Unsupervised or self-supervised pre training (SimCLRv2) to learn general visual representations, Supervised fine-tuning on a few labeled examples to adapt the model to a specific classification task And Distillation using unlabeled data to refine and transfer the task-specific knowledge to a smaller network.
Recommended Reading [Papers Explained 200: SimCLR]
Method
The proposed semi-supervised learning framework leverages unlabeled data in both task-agnostic and task-specific ways. The first time the unlabeled data is used, it is in a task-agnostic way, for learning general (visual) representations via unsupervised pre training. The general representations are then adapted for a specific task via supervised fine-tuning. The second time the unlabeled data is used, it is in a task-specific way, for further improving predictive performance and obtaining a compact model.

Self-supervised pre training with SimCLRv2
SimCLR learns representations by maximizing agreement between differently augmented views of the same data example via a contrastive loss in the latent space. SimCLRv2 improves upon SimCLR in three major ways :
- To fully leverage the power of general pretraining, larger ResNet models are explored. Models that are deeper but less wide are trained. The largest model trained is a 152-layer ResNet with 3× wider channels and selective kernels (SK), a channel-wise attention mechanism that improves the parameter efficiency of the network.
- The capacity of the non-linear network g(·) (a.k.a. projection head) is increased by making it deeper. Instead of throwing away g(·) entirely after pretraining as in SimCLR, fine-tuning is done from a middle layer.
- The memory mechanism from MoCo is incorporated, designating a memory network (with a moving average of weights for stabilization) whose output will be buffered as negative examples.
Fine-tuning
In SimCLR, the MLP projection head g(·) is discarded entirely after pretraining, while only the ResNet encoder f(·) is used during the fine-tuning. Instead, the model is fine-tuned from a middle layer of the projection head, instead of the input layer of the projection head as in SimCLR.
Self-training / knowledge distillation via unlabeled examples
The fine-tuned network is used as a teacher to impute labels for training a student network. Specifically, the following distillation loss is minimized where no real labels are used:


Experiment Settings and Implementation Details
The LARS optimizer (with a momentum of 0.9) is used throughout for pretraining, fine-tuning, and distillation. For pretraining, the model is trained for a total of 800 epochs, utilizing a 3-layer MLP projection head on top of a ResNet encoder. The memory buffer is set to 64K, and exponential moving average (EMA) decay is set to 0.999. The same set of simple augmentations as SimCLR is used, namely random crop, color distortion, and Gaussian blur.
For fine-tuning, the model is fine-tuned from the first layer of the projection head for 1%/10% of labeled examples, but from the input of the projection head when 100% labels are present. Fine-tuning is performed for 60 epochs with 1% of labels, and 30 epochs with 10% of labels, as well as full ImageNet labels.
For distillation, only unlabeled examples are used. Two types of distillation are considered: self-distillation, where the student has the same model architecture as the teacher (excluding the projection head), and big-to-small distillation, where the student is a much smaller network. The temperature is set to 0.1 for self-distillation and 1.0 for large-to-small distillation. The models are trained for 400 epochs. Only random crop and horizontal flips of training images are applied during fine-tuning and distillation.
Empirical Study
Bigger Models Are More Label-Efficient
To investigate the effectiveness of different model architectures for both supervised and self-supervised learning, it was sought to explore the impact of model size (width and depth) and selective kernels (SK) on performance. To achieve this, ResNet models were trained with varying width, depth, and the use of SK.
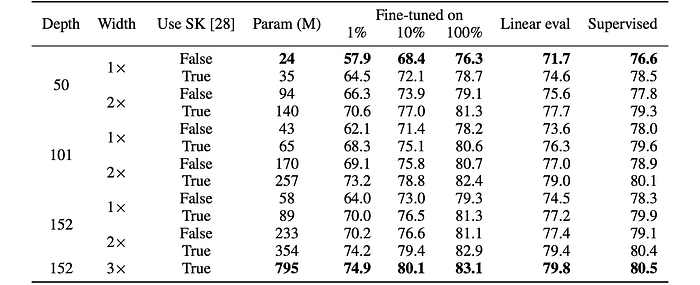
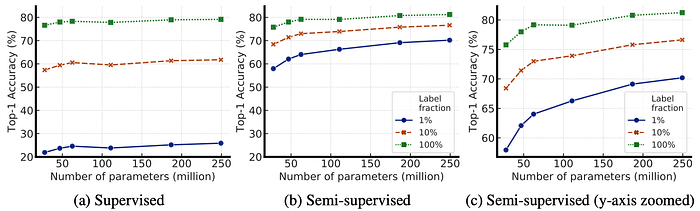
- Increasing model size (width and depth) and using SK generally improves performance.
- For supervised learning, the difference in accuracy between the smallest and largest models was modest (4%), but for self-supervised learning, the difference was more significant (up to 17% for fine-tuning on 1% of labeled images).
- Benefits of width may plateau: ResNet-152 (3×+SK) shows only marginal improvement over ResNet-152 (2×+SK) despite a significant increase in parameters.
- Parameter efficiency varies: Some models (e.g., those with SK) are more parameter-efficient than others, suggesting the importance of architectural exploration.
Bigger/Deeper Projection Heads Improve Representation Learning
To investigate the impact of projection head depth on fine-tuning performance in ResNet-50 models pre-trained with SimCLRv2, ResNet-50 was pret rained with SimCLRv2 using different numbers of projection head layers (2 to 4 fully connected layers). Fine-tuning performance was evaluated from various layers within the projection head.
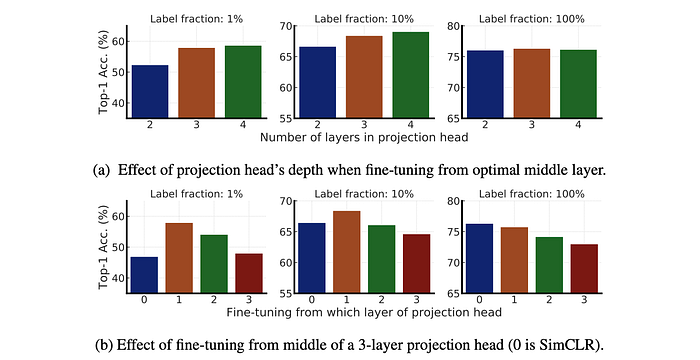
- Deeper projection heads during pretraining lead to better fine-tuning performance, especially when fine-tuning from the first layer of the projection head.
- The optimal layer for fine-tuning is often the first layer of the projection head, particularly when using fewer labeled examples.
- The benefit of a deeper projection head diminishes when using larger ResNet architectures. This could be because wider ResNets already have wider projection heads due to the width multiplier.
- Fine-tuning accuracy correlates with linear evaluation accuracy.
- Fine-tuning from the optimal middle layer of the projection head yields a stronger correlation with linear evaluation accuracy compared to fine-tuning from the projection head input.
Distillation Using Unlabeled Data Improves Semi-Supervised Learning
A distillation loss is utilized to encourage the student model to match the output distribution of a teacher model. This distillation loss is combined with a supervised cross-entropy loss on labeled data. Experiments are conducted using distillation loss alone for simplicity. Self-distillation, where a large model is distilled before being used to train smaller models, is also employed.

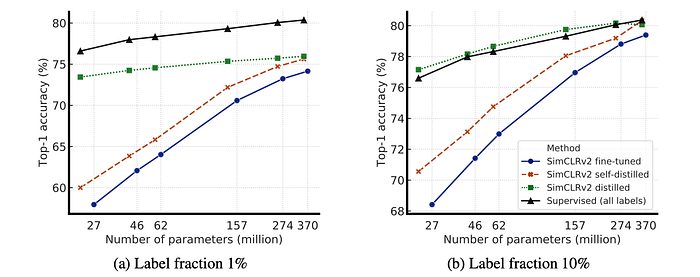
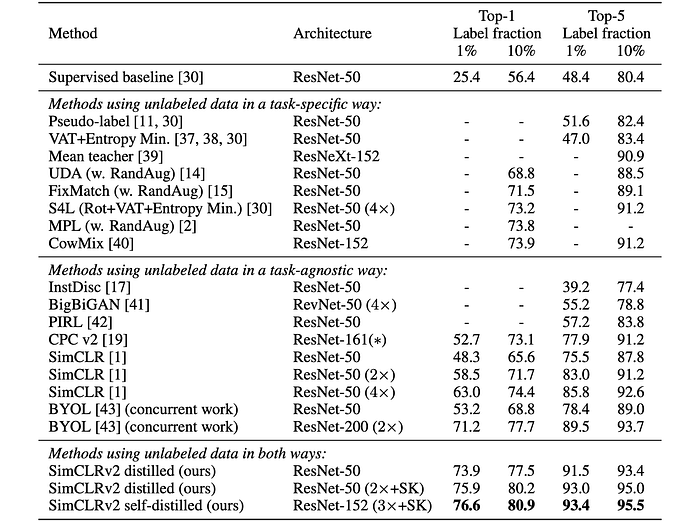
- Using unlabeled examples significantly improves performance when training with the distillation loss.
- Distillation loss alone performs almost as well as balancing distillation and label losses when the labeled fraction is small.
- Distillation improves model efficiency by transferring knowledge to smaller student models.
- Self-distillation meaningfully improves semi-supervised learning performance even when student and teacher models have the same architecture.
- The proposed approach outperforms previous state-of-the-art semi-supervised learning methods on ImageNet.
Paper
Big Self-Supervised Models are Strong Semi-Supervised Learners 2006.10029
Recommended Reading [Retrieval and Representation Learning]
Hungry for more insights?
Don’t miss out on exploring other fascinating threads in this series. Simply click here and uncover the state-of-the-art research!
Do Subscribe for weekly updates!!
