Papers Explained 200: SimCLR

SimCLR is a simple framework for contrastive learning of visual representations. The key components of the framework and findings are:
- Combining data augmentations is crucial in defining effective predictive tasks.
- Introducing a learnable non-linear transformation between the representation and the contrastive loss improves the quality of learned representations.
- Contrastive learning benefits from larger batch sizes and more training steps compared to supervised learning.
Method

SimCLR learns representations by maximizing agreement between differently augmented views of the same data example via a contrastive loss in the latent space. The framework comprises the following four major components.
- A stochastic data augmentation module transforms any given data example randomly, resulting in two correlated views of the same example, denoted ˜xi and ˜xj. This is achieved by sequentially applying three simple augmentations: random cropping followed by resize back to the original size, random color distortions, and random Gaussian blur.
- A neural network base encoder f(·) extracts representation vectors from augmented data examples. For simplicity, the commonly used ResNet-50 is adopted to obtain hi = f(˜xi) = ResNet(˜xi).
- A small neural network projection head g(·) maps representations to the space where contrastive loss is applied. An MLP with 2 layers is used to obtain 128-dimensional zi = g(hi) = W(2)σ(W(1)hi), where σ is a ReLU nonlinearity.
- A contrastive loss function defined for a contrastive prediction task.
A minibatch of N examples is randomly sampled, and the contrastive prediction task is defined on pairs of augmented examples derived from the minibatch, resulting in 2N data points. Negative examples are not sampled explicitly. Instead, given a positive pair, the other 2(N−1) augmented examples within a minibatch are treated as negative examples.
The the loss function for a positive pair of examples (i, j) is defined as

Where, sim(u, v) is the cosine similarity, 1[k!=i] ∈ {0, 1} is an indicator function evaluating to 1 and τ denotes a temperature parameter. For convenience, it is termed as NT-Xent (the normalized temperature-scaled cross entropy loss).

Training batch size N is varied from 256 to 8192. A batch size of 8192 yields 16382 negative examples per positive pair from both augmentation views. Training with large batch size may be unstable when using standard SGD/Momentum with linear learning rate scaling, hence to stabilize the training, LARS optimizer is used.
Data Augmentation for Contrastive Representation Learning

Traditionally, data augmentation has been widely used in both supervised and unsupervised learning, but not specifically to define contrastive prediction tasks. Instead of modifying the architecture to achieve this, simple random cropping and resizing can create a variety of predictive tasks without architectural changes.
The composition of data augmentation operations is crucial for learning good representations. Common augmentations include spatial/geometric transformations such as cropping, resizing, flipping, rotation, and cutout, as well as appearance transformations like color distortion, Gaussian blur, and Sobel filtering. The impact of these augmentations was studied individually and in pairs, using an asymmetric data transformation setting to isolate effects.
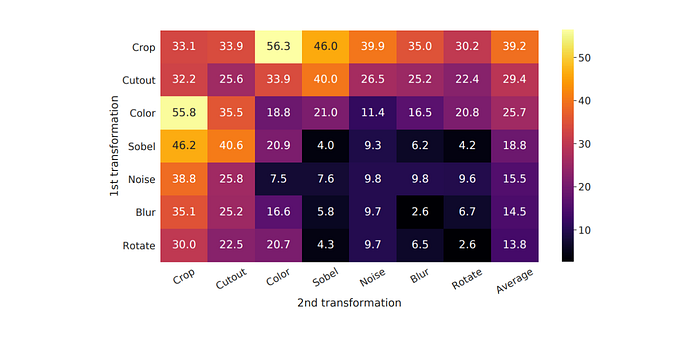
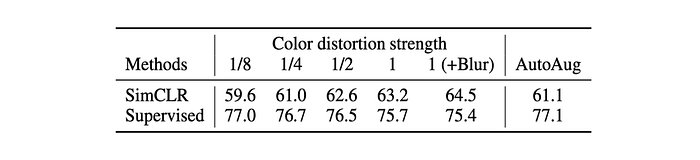
The findings show that no single transformation is sufficient for learning good representations. However, combining augmentations, especially random cropping with color distortion, improves representation quality significantly. This is because random cropping alone may allow neural networks to exploit color distribution similarities in image patches, whereas adding color distortion helps learn more generalizable features.
Architectures for Encoder and Head
Unsupervised Contrastive Learning Benefits from Bigger Models
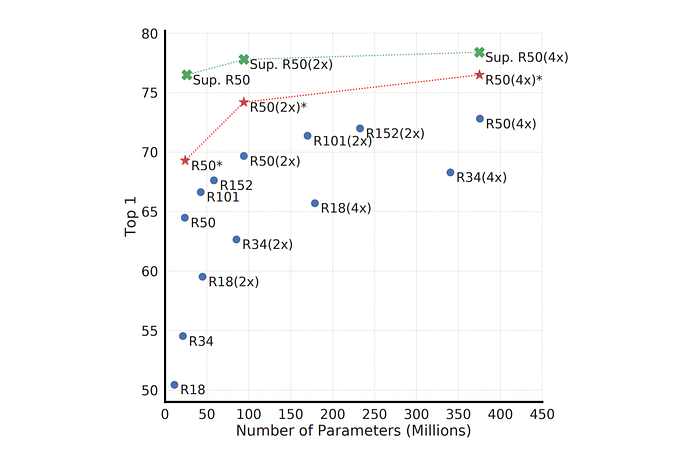
Increasing depth and width of models improves performance, similar to supervised learning. The performance gap between supervised models and linear classifiers trained on unsupervised models shrinks with larger model sizes, indicating unsupervised learning benefits more from bigger models.
Nonlinear Projection Head Improves Representation Quality
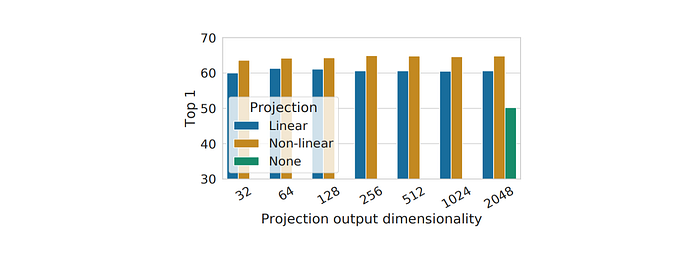
Study on the importance of a projection head (g(h)) shows that Nonlinear projection (one hidden layer with ReLU) outperforms linear projection by 3% and identity mapping by more than 10%. Regardless of output dimension, the layer before the projection head (h) is a better representation than the layer after (z = g(h)), by more than 10%.
This suggests the representation before the nonlinear projection retains more information, as the contrastive loss in z = g(h) removes useful information for downstream tasks. Experiments confirm that h retains more information about applied transformations than g(h), supporting the hypothesis that the nonlinear transformation maintains more information in h.
Loss Functions and Batch Size
Normalized cross entropy loss with adjustable temperature works better than alternatives
The NT-Xent loss is compared with other commonly used contrastive loss functions, such as logistic loss and margin loss. It is found that the NT-Xent loss, which uses normalized cross entropy with adjustable temperature, performs better because:
- The `L2 normalization (cosine similarity)` and temperature weighting in NT-Xent help the model learn from hard negatives.
- Other loss functions do not weigh negatives by their relative hardness, requiring semi-hard negative mining to improve performance.

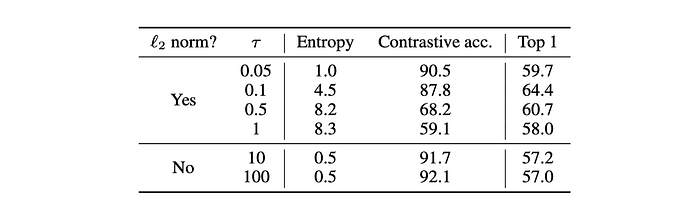
Experiments showed that even with semi-hard negative mining, NT-Xent loss still outperforms other loss functions. Additionally, the importance of `L2 normalization` and temperature scaling is highlighted, as removing these features significantly worsens performance.
Contrastive learning benefits (more) from larger batch sizes and longer training

Larger batch sizes, especially with fewer training epochs, offer a significant advantage by providing more negative examples, which aids convergence. Training for longer periods also yields more negative examples, further improving results.
Comparison with State-of-the-art
To evaluate the effectiveness of self-supervised learning for image representation learning, it was necessary to compare the performance of self-supervised models with supervised models in various downstream tasks. ResNet-50 with different hidden layer widths (1×, 2×, and 4×) was utilized as the backbone network.
The models were trained for 1000 epochs to ensure convergence. The performance of these models was then compared across three settings:
Linear evaluation, where a fixed feature extractor was used; semi-supervised learning, which involved using a small percentage of labeled data; and transfer learning, evaluating performance on various downstream tasks.
Linear Evaluation
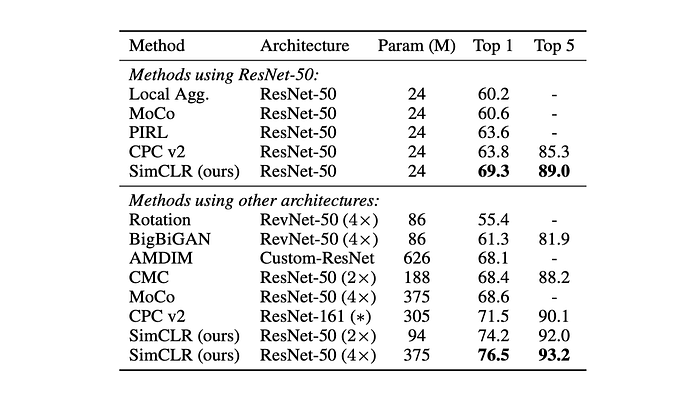
Self-supervised models achieve significantly better results compared to previous methods that relied on specifically designed architectures. The best self-supervised model (ResNet-50 4×) matches the performance of a supervised pretrained ResNet-50.
Semi-Supervised Learning
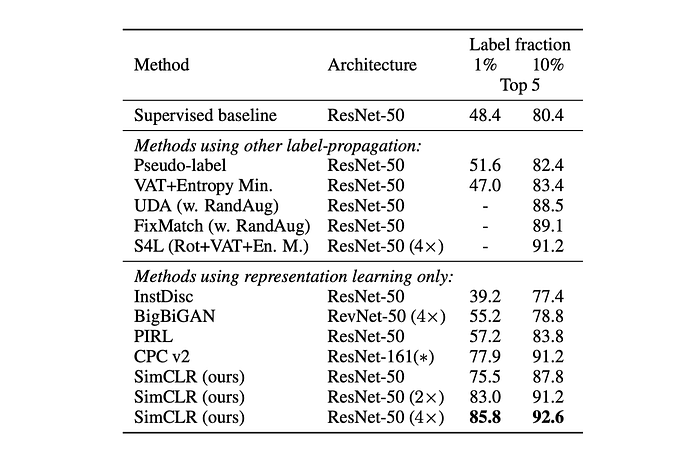
Self-supervised models outperform state-of-the-art methods with both 1% and 10% labeled data. Fine-tuning pretrained ResNet-50 (2×, 4×) on the full ImageNet dataset also outperforms training from scratch.
Transfer Learning
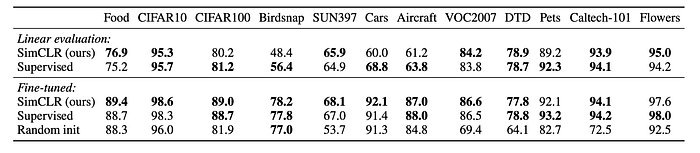
Self-supervised models significantly outperform the supervised baseline on 5 out of 12 datasets. The supervised baseline is superior on only 2 datasets, while the models are statistically tied on the remaining 5.
Paper
A Simple Framework for Contrastive Learning of Visual Representations 2002.05709
Recommended Reading [Retrieval and Representation Learning]
Hungry for more insights?
Don’t miss out on exploring other fascinating threads in this series. Simply click here and uncover the state-of-the-art research!
Do Subscribe for weekly updates!!
