Papers Explained 172: E5-V

E5-V leverages Multimodal Large Language Models Via prompts to effectively bridge the modality gap between different types of inputs, demonstrating strong performance in multimodal embeddings even without fine-tuning. It proposes a single modality training approach, where the model is trained exclusively on text pairs, demonstrating significant improvements over traditional multimodal training on image-text pairs, while reducing training costs.
The project is available at Github.
Recommended Reading [Papers Explained 90: E5]
Unifying Multimodal Embeddings

To unify multimodal embeddings, a prompt-based representation method with MLLMs is used. The key idea is to explicitly instruct MLLMs to represent the multimodal inputs into words. Prompts like
<text> \n Summary of the above sentence in one word:
and
<image> \n Summary above image in one word:
to represent the text and image respectively.
These prompts directly remove the modality gap between text and image embeddings.

For the design of the prompts, it has two parts: the first part is about extracting the meaning of the multimodal inputs, and the second part is about compressing the meaning into the next token embeddings and unifying the multimodal embeddings by using ‘in one word‘
By removing the modality gap, it also allows MLLMs to represent interleaved inputs for tasks like composed image retrieval.
Single Modality Training

Since there is no longer a modality gap in the embeddings, the single modality representation capabilities can be transferred to multimodal embeddings by training on text pairs only. In this way, the model is trained without any visual or interleaved inputs and no longer relies on multimodal training data, which can be difficult to collect. E5-V trains MLLMs with contrastive learning on text pairs.
The following prompt is used to embed the sentence pairs into (h, h+ , h−).
<text> \n Summary above sentence in one word:
The training objective is following:
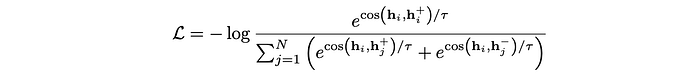
For the backbone of E5-V, LLaVA-NeXT-8B is used, which builds on LLaMA-3 8B, with a frozen CLIP ViT-L as the visual encoder. For the training data, NLI sentence pairs are used, with around 273k sentence pairs.
Evaluation
Text-Image Retrieval
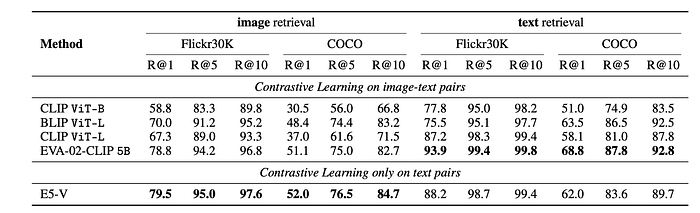
- E5-V achieves competitive performance on both Flickr30K and COCO datasets, outperforming strong baselines like CLIP ViT-L and EVA-02-CLIP.
- E5-V demonstrates superior zero-shot image retrieval performance compared to EVA-02-CLIP, despite being trained only on text pairs.
Composed Image Retrieval

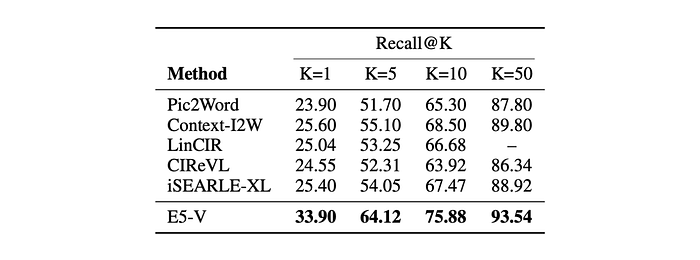
- On CIRR, E5-V outperforms the state-of-the-art iSEARLE-XL by 8.50% on Recall@1 and 10.07% on Recall@5.
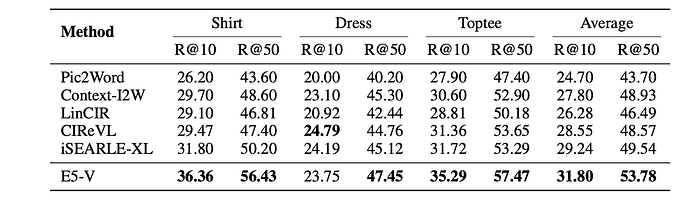
- On FashionIQ, E5-V outperforms iSEARLE-XL by 2.56% on Recall@10 and 4.24% on Recall@50.
Image-Image Retrieval
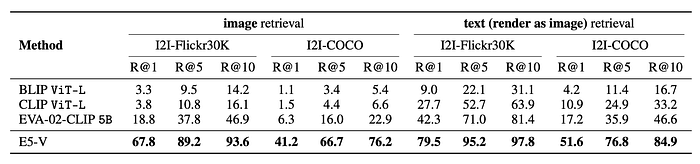
- Baselines (CLIP, BLIP, EVA-02-CLIP) show significantly lower performance on image-image retrieval compared to text-image retrieval, highlighting the difficulty of understanding text from images.
- E5-V outperforms the baselines on both I2I-Flickr30K and I2I-COCO datasets, demonstrating its strong ability to understand text through visual input and represent it accurately.
Sentence Embeddings
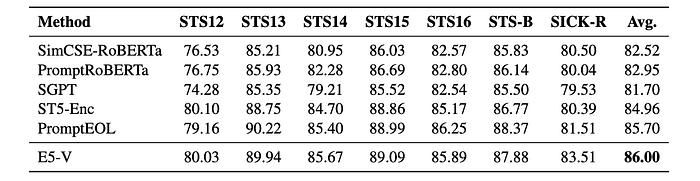
- E5-V outperforms other sentence embedding methods on the STS tasks, including SimCSE-RoBERTa, PromptRoBERTa, SGPT, ST5-Enc, and PromptEOL.
- This strong performance demonstrates E5-V’s ability to effectively represent textual inputs based on their semantic meaning.
Paper
E5-V: Universal Embeddings with Multimodal Large Language Models 2407.12580
Recommended Reading [Retrieval and Representation Learning]
Hungry for more insights?
Don’t miss out on exploring other fascinating threads in this series. Simply click here and uncover the state-of-the-art research!
Do Subscribe for weekly updates!!
