Papers Explained 109: Aya 101

Aya 101 is a massively multilingual generative language model that follows instructions in 101 languages of which over 50% are considered as lower-resourced. It outperforms mT0 and BLOOMZ on the majority of tasks while covering double the number of languages.
The model is available at https://hf.co/CohereForAI/aya-101.
Recommended Reading [Papers Explained 108: Aya Dataset]

Data

The training data curation includes relying on extensive efforts to aggregate and prune multilingual templates and hard-to-find human annotations curated by fluent speakers of various languages. Moreover, it also extends to data augmentation strategies such as machine translation and leveraging synthetic data generation coupled with translation.

The languages are grouped in 5 distinct clusters into a rough taxonomy of lower-resourced (LR), mid-resourced (MR) and higher-resourced (HR).
Multilingual Templates
xP3x Dataset
xP3x (Cross Lingual Public Pool of Prompts eXtended) extends xP3 from 86M examples across 46 languages and 13 tasks to 680M examples across 277 languages and 16 tasks. In this work, a subset of xP3x focusing on the 101 languages that mT5 is considered for further pruning.
At least two reviewers inspect every template and recommend templates for removal if they contain
- instructions paired with very short or empty generations.
- prompt templates that are slightly edited versions of another prompt template.
- samples with grammatical or structural errors.

- 50.2% of English and 35.9% multilingual templates are removed resulting in a 19.7% decrease in the number of English instances and 18.3% decrease in the number of multilingual instances.
- After pruning, the remaining data presents a 7.0% increase in average instruction lengths for English instances and a 16.8% increase across multilingual instances.
Data Provenance Collection
The filter tools from the Data Provenance Initiative are used to select additional publicly available supervised datasets. The final collection is made up of OctoPack’s cleaned version of Open Assistant, Open Instruction Generalist, a subset of the Flan Collection and Tasksource Instruct.
Despite the potential benefits of code for natural language performance, none of the code datasets are included as the base model, mT5, has not seen any code during pre training. To amplify diversity, each dataset is sampled up to a maximum of 20,000 examples. The final collection consists of 1.6M examples out of which 550K are few-shot, and the rest are zero-shot, covering 14 languages and 161 different datasets.
Aya Collection
In addition to using existing instruction datasets such as xP3x, templates included in the Aya collection are also used in the IFT mixture.
Human Annotations
Here, the focus is on introducing new multilingual human annotations through the Aya dataset Read More
Augmentation via Automatic Translation
The Aya collection includes 19 translated datasets covering 101 languages. For model training only the languages that overlap with the 101 languages used for mt5 pre-training. In total, translated data for 93 languages across 19 translated datasets with a total of 22 instruction templates are included.
A subset of up to 3,000 instances is randomly sampled for each language for each dataset to preserve instance-level diversity.This ensures that a different random sample is translated into each language. The only exception is Dolly v2 which contains 15k examples created by Databricks. The final translated instruction mixture includes 7.5M instances from the translated data subset in the Aya Collection.
Synthetic Data Generation
ShareGPT-Command, a 6.8M synthetically generated and machine translated dataset in 93 languages is curated. It combines human annotated prompts from ShareGPT with synthetic English completions from Command (Cohere’s flagship text generation model trained to follow user instructions and be useful in practical applications). The original synthetic completions from ShareGPT are not used to comply with the terms of service of ChatGPT13 which prohibits training on their generations.
To ensure the quality of the prompts, any prompt that contains URLs, is longer than 10,000 characters, or contains non-English languages is filtered out, producing an English dataset with 61,872 samples. NLLB Is then used to translate this dataset as per the process followed for aya collection. In total, ShareGPT-Command has 6.8M examples, covering 93 languages.
Experimental Set-up
mT5 13 B, an encoder-decoder transformer pre-trained on 1 trillion tokens of natural language text covering 101 languages from mC4 using a sequence masking objective is finetuned.
All the models in this study are trained for 30,000 update steps, resulting in a training budget of 25M samples.
The combined sources consist of over 203M instances. However, a pronounced skew is observed in volume. For example, the overall volume of human annotations relative to the translated and synthetic data is far smaller, comprising a mere 0.7% of the total training budget. Hence a two-fold sampling strategy is used (Source level sampling and Dataset level sampling)
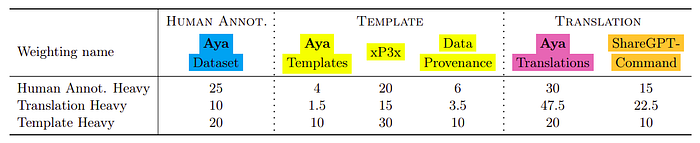
Different weighting schemes are assigned considering the number of examples, language coverage and quality of data:
- Human Annotation Heavy which upweights the Aya Dataset.
- Translation heavy which upweights the translated sources: Aya Translations and ShareGPT Command.
- Template heavy which upweights the Aya Collection, xP3x, and Data Provenance.
In addition, a safety-mitigated Aya model, referred to as “Aya Safe” is specifically trained to not engage in adversarial prompts with harmful intent.
A safety distillation training set is compiled from multilingual AdvBench (12 Aya languages) and the XSafety benchmark (9 Aya languages), both of which contain collections of prompts reflecting harmful user intent.
Both datasets are split into training and held-out test portions, yielding 1360 training prompts per language. For evaluation, the AdvBench held-out portion of 120 prompts per language is used. For the languages not covered by the original datasets, the prompts are translated with NLLB into the remaining target languages (used only for training data). Aya Safe is finetuned for 30k steps and the last checkpoint is used for evaluation.
Evaluation
Discriminative Tasks
- The study compares the Aya model against baselines such as mT0, BLOOMZ, Bactrian-X, and mT0x on unseen tasks across languages.
- Performance is measured in zero-shot scenarios for tasks on XWinograd, XNLI, XCOPA, and XStoryCloze.
- The comparison includes models covering different numbers of languages, with Aya and mT0x covering 101 languages, Bactrian-X 52, and mT0/BLOOMZ 46.
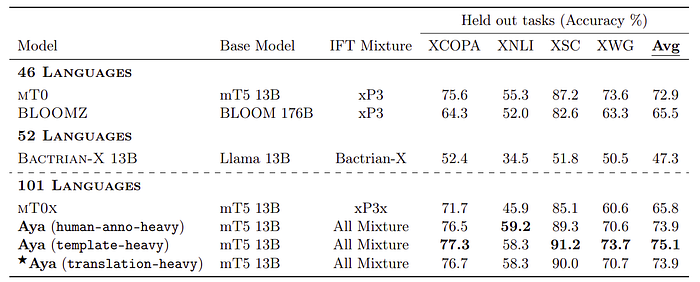
- The Aya model (template-heavy) outperforms all baselines with an average performance of 75.12%, despite covering approximately double the languages.
- mT0 scored the highest among the baselines with 72.9%, while Bactrian-X was the lowest at 47.3%.
- The Aya model’s success is attributed to a high-quality, diverse, and balanced instruction finetuning mixture, which helps offset the curse of multilinguality.
- The mT0x model, despite covering 101 languages like Aya, performed significantly worse than mT0, suggesting that the drop in performance is more related to the data used rather than model capacity.
- Downsampling dominant datasets and including a larger variety of multilingual datasets in the finetuning mixture is crucial, as demonstrated by Aya’s superior performance over mT0x by 14.8%.
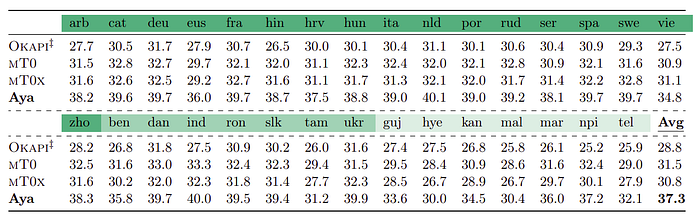
- The Aya model (translation-heavy) achieves the best overall performance across 26 languages in the multilingual MMLU task, improving average accuracy by 21.1% over mT0x, 18.4% over mT0, and 25.1% over Okapi.
- Despite Okapi’s approach of training individual models per language and preference-tuning by RLHF, Aya and other massively multilingual models outperform it.
- The study highlights the importance of finetuning with a diverse and balanced instruction mixture and the inclusion of a variety of multilingual datasets to achieve high performance in multilingual models.
Generative Tasks
- To evaluate the performance of Aya models and mT0x in machine translation, summarization, and question-answering tasks across multiple languages.
- Utilized datasets FLORES-200, XLSum, and Tydi-QA for evaluation in machine translation, summarization, and question-answering respectively.
- Compared Aya models and mT0x, focusing on language coverage and excluding validation splits from the evaluation to ensure fairness.
- Analyzed performance across 101 languages for both Aya models and mT0x.
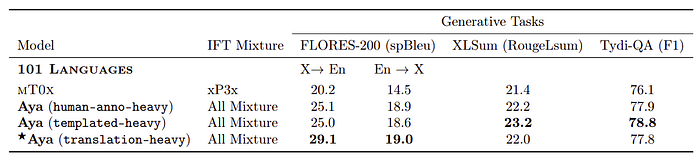
- Aya models consistently outperformed mT0x across all tasks.
- In machine translation (FLORES-200), Aya (translation-heavy) significantly improved over mT0x, with spBLUE scores of 44% for X → English and 31% for English → X.
- In summarization (XLSum) and question-answering (Tydi-QA GoldP), Aya (translation-heavy) showed modest improvements of 1.8% in RougeLsum and 2.2% in F1, respectively.
- The performance differences in XLSum and Tydi-QA were smaller, likely due to the limited language coverage of these datasets.
- Among Aya model variants, the templated-heavy variant showed higher improvements in XLSum and Tydi-QA GoldP, with 7.4% in RougeLsum score and 3.5% in F1, respectively. This suggests that the templated-heavy variant benefits from up-weighted xP3x data in tasks with limited language coverage.
- The difference in performance between Aya model variants is attributed to their different weighting schemes and the language coverage of the tasks.
Performance Comparison by Language Resourcedness
- The study aims to compare the performance of the Aya model with the mT0x model across various language groups (higher-resourced, mid-resourced, and lower-resourced) and tasks (unseen discriminative tasks, Multilingual MMLU, machine translation, XLsum, and TydiQA).
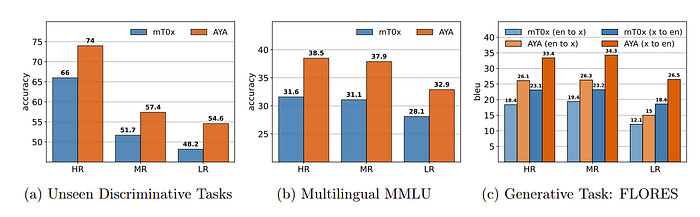
Unseen Discriminative Tasks and Multilingual MMLU (Figure 3a, 3b):
- The Aya model significantly outperforms mT0x across all language groups, with the highest difference observed in HR languages (12.1% and 21.8% improvement, respectively).
- This superior performance is attributed to better coverage and task diversity for HR languages in the benchmarks and IFT data mixture used for the Aya model.
Machine Translation with FLORES-200 (Figure 3c):
- The Aya model shows a remarkable average improvement of 40.8% over mT0x in spBLEU scores, with the most significant gains seen in LR languages (47.1%).
- Improvements are also notable in HR (36.1%) and MR (34.9%) languages, suggesting the Aya model’s finetuning mixture includes higher percentage and quality data for LR languages.
- Translation direction-wise, the Aya model achieves higher relative gains in translations into English (45.3%) compared to from English (34.9%).
XLsum and TydiQA Tasks:
- Compared to the other tasks, improvements with the Aya model are relatively lower in XLsum and TydiQA across all languages (1.8% RougeLsum and 2.2% F1, respectively).
- MR languages exhibit the most benefit in these tasks with the Aya model, achieving 2.7% and 3.7% relative gains, respectively.
The overall findings indicate that the Aya model provides substantial improvements over mT0x, especially in HR and LR languages and in generative tasks like machine translation. The lesser improvements in XLsum and TydiQA tasks for MR languages suggest a nuanced performance landscape that varies by task and language resourcedness.
Paper
Aya Model: An Instruction Finetuned Open-Access Multilingual Language Model 2402.07827
Recommended Reading [Multi Task Language Models] [Aya Series]
Hungry for more insights?
Don’t miss out on exploring other fascinating threads in this series. Simply click here and uncover the state-of-the-art research!
Do Subscribe for weekly updates!!
