Papers Explained 83: Are Emergent Abilities of Large Language Models a Mirage?

Large language models are claimed to demonstrate certain emergent abilities which are not present at smaller scales. These emergent abilities are intriguing because of their sharpness i.e. transitioning seemingly instantaneously from not present to present, and their unpredictability i.e. appearing at seemingly unforeseeable model scales.
This paper presents an alternative explanation for emergent abilities.
Alternative Explanation for Emergent Abilities

[A] Suppose the per-token cross-entropy loss decreases monotonically with model scale, e.g., LCE scales as a power law.
[B] The per-token probability of selecting the correct token asymptotes towards 1.
[C] If the researcher scores models’ outputs using a nonlinear metric such as Accuracy (which requires a sequence of tokens to all be correct), the metric choice non-linearly scales performance, causing performance to change sharply and unpredictably in a manner that qualitatively matches published emergent abilities (inset).
[D] If the researcher instead scores models’ outputs using a discontinuous metric such as Multiple Choice Grade (akin to a step function), the metric choice discontinuously scales performance, again causing performance to change sharply and unpredictably.
[E] Changing from a nonlinear metric to a linear metric such as Token Edit Distance, scaling shows smooth, continuous and predictable improvements, ablating the emergent ability.
[F] Changing from a discontinuous metric to a continuous metric such as Brier Score again reveals smooth, continuous and predictable improvements in task performance.
Consequently, emergent abilities are created by the researcher’s choice of metrics, not fundamental changes in model family behavior on specific tasks with scale.
Analyzing InstructGPT/GPT-3’s Emergent Arithmetic Abilities
The alternative explanation makes three predictions:
1. Changing the metric from a nonlinear or discontinuous metric to a linear or continuous metric should reveal smooth, continuous, predictable performance improvement with model scale.
2. For nonlinear metrics, increasing the resolution of measured model performance by increasing the test dataset size should reveal smooth, continuous, predictable model improvements commensurate with the predictable nonlinear effect of the chosen metric.
3. Regardless of metric, increasing the target string length should predictably affect the model’s performance as a function of the length-1 target performance: approximately geometrically for accuracy and approximately quasi-linearly for token edit distance.
To test these predictions, outputs are collected from the InstructGPT/GPT-3 family on two tasks: 2-shot multiplication between two 2-digit integers and 2-shot addition between two 4-digit integers.
Emergent Abilities Disappear With Different Metrics

Top: When performance is measured by a nonlinear metric (e.g., Accuracy), the InstructGPT/GPT-3 family’s performance appears sharp and unpredictable on longer target lengths.
Bottom: When performance is instead measured by a linear metric (e.g., Token Edit Distance), the family exhibits smooth, predictable performance improvements.
This confirms the first prediction and supports the alternative explanation that the source of emergent abilities is the researcher’s choice of metric, not changes in the model family’s outputs.
Under Token Edit Distance, increasing the length of the target string from 1 to 5 predictably decreases the family’s performance in an approximately quasi-linear manner, confirming the first half of the third prediction.
Emergent Abilities Disappear With Better Statistics
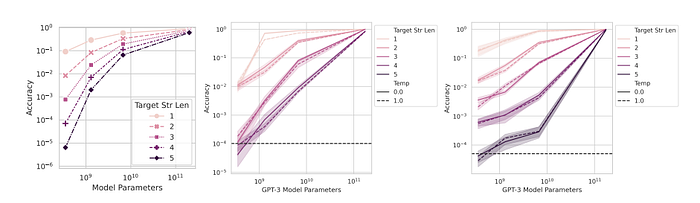
Based on the predictable effect Accuracy has on performance, measuring performance requires high resolution. Generating additional test data increases the resolution and reveals that even on Accuracy, the InstructGPT/GPT-3 family’s performance is above chance and improves in a smooth, continuous, predictable manner that qualitatively matches the mathematical model.
This confirms the second prediction. It is also observed that as the target string length increases, the accuracy falls approximately geometrically with the length of the target string, confirming the second half of the third prediction.
Meta-Analysis of Claimed Emergent Abilities
The alternative explanation makes two predictions:
1. At the “population level” of Task-Metric-Model Family triplets, emergent abilities should appear predominantly on specific metrics, not task-model family pairs, and specifically with nonlinear and/or discontinuous metrics.
2. On individual Task-Metric-Model Family triplets that display an emergent ability, changing the metric to a linear and/or continuous metric should remove the emergent ability.
To test these predictions, the claimed emergent abilities are used on BIG-Bench being pertinent and publicly available.
Emergent Abilities Should Appear with Metrics, not Task-Model Families
To test this, an analysis was conducted on which metrics emergent abilities appear. To determine whether a possible emergent ability is exhibited by a task-metric-model family triplet, Emergence Score was used. Letting yi ∈ R denote model performance at model scales xi ∈ R, sorted such that xi < xi+1, the emergence score is:

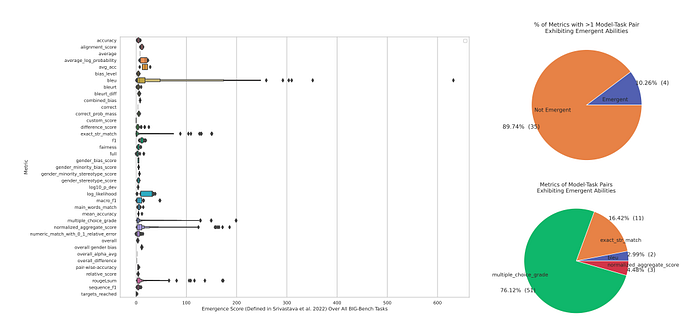
[A] Most metrics used in BIG-Bench have zero task-model family pairs that exhibit emergent abilities: of the 39 preferred metrics in BIG-Bench, at most 5 display emergence. Many of the 5 are nonlinear and/or discontinuous
Notably, because BIG-Bench often scores models on tasks using multiple metrics, the lack of emergent abilities under other metrics suggests that emergent abilities do not appear when model outputs are scored using other metrics.
[B] Hand-annotated data reveals emergent abilities appear only under 4 preferred metrics.
[C] > 92% of emergent abilities appear under one of two metrics: Multiple Choice Grade and Exact String Match.
Changing Metric Removes Emergent Abilities
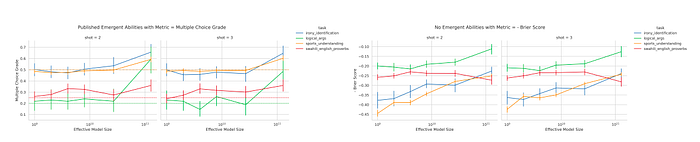
The LaMDA model family displays emergent abilities when measured under the discontinuous Multiple Choice Grade.
The LaMDA model family’s emergent abilities disappear when measured under a continuous BIG-Bench metric: Brier Score.
Inducing Emergent Abilities in Networks on Vision Tasks
To demonstrate how emergent abilities can be induced by the researcher’s choice of metric, The paper shows how to produce emergent abilities in deep networks of various architectures: fully connected, convolutional, self-attentional.
Emergent Reconstruction of CIFAR100 Natural Images by Nonlinear Autoencoders
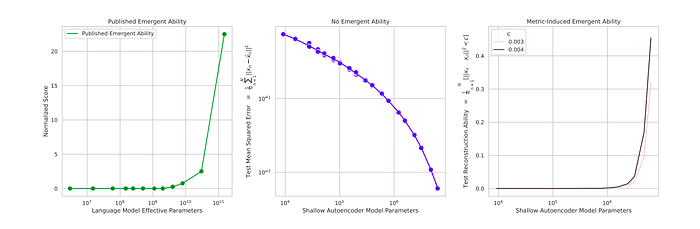
An emergent ability is induced to reconstruct images in shallow (i.e., single hidden layer) nonlinear autoencoders trained on CIFAR100 natural images to emphasize that the sharpness of the metric is responsible for emergent abilities, and to show that sharpness extends to metrics beyond Accuracy.
[A] A published emergent ability at the BIG-Bench Periodic Elements task
[B] Shallow nonlinear autoencoders trained on CIFAR100 display smoothly decreasing mean squared reconstruction error.
[C] Using a newly defined Reconstructionc metric (the average number of test data with squared reconstruction error below threshold c) induces an unpredictable change.
Emergent Classification of Omniglot Characters by Autoregressive Transformers
Emergent abilities are induced in Transformers trained to autoregressively classify Omniglot handwritten characters. Omniglot images are embedded by convolutional layers, then sequences of embedded image-image class label pairs are fed into decoder-only transformers.
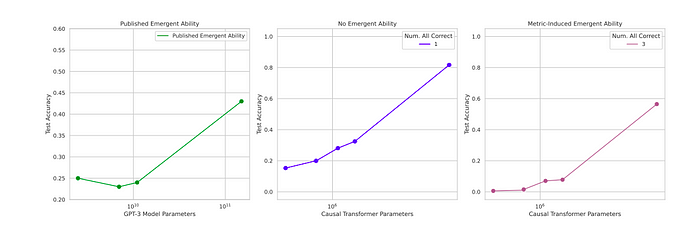
[A] A published emergent ability on the MMLU benchmark.
[B] Autoregressive transformers trained to classify Omniglot images display increasing accuracy with increasing scale.
[C] When accuracy is redefined as classifying all images correctly, a seemingly emergent ability appears.
Paper
Are Emergent Abilities of Large Language Models a Mirage? 2304.15004
Hungry for more insights?
Don’t miss out on exploring other fascinating threads in this series. Simply click here and uncover the state-of-the-art research!
Do Subscribe for weekly updates!!
