Papers Explained 87: DocLLM

DocLLM is a lightweight extension to traditional large language models (LLMs) for reasoning over visual documents, taking into account only textual semantics and spatial layout, avoiding expensive image encoders. The cross-alignment between text and spatial modalities is captured by decomposing the attention mechanism in classical transformers to a set of disentangled matrices. Furthermore, the paper devises a pre-training objective that learns to infill text segments.
Recommended Reading [Papers Explained 42: UDOP]
DocLLM Architecture

DocLLM is built upon the foundation of decoder-only transformer language models. In contrast to standard language models accepting only a sequence of text tokens as input, DocLLM integrates lightweight visual information by utilizing the spatial positions and dimensions of text tokens. Separate vectors are used to represent these two modalities and extend the self-attention mechanism of the transformer architecture to compute their interdependencies in a disentangled manner.
Furthermore, instead of the traditional left-to-right next token prediction during self-supervised training, DocLLM employs a text infilling objective that better leverages contextual information.
Disentangled Spatial Attention
In classical transformers, using a learned embedding matrix based on the text vocabulary and a learned set of parameters for the token position in the sequence, the input tokens are first encoded into hidden vectors H. A self-attention head then computes the attention scores between tokens i and j as:

where Wq and Wk are projection matrices, and the superscript t indicates the text modality. The attention scores A along with another projection matrix Wv are further used to compute the hidden vectors H′, which are in turn used as inputs for a subsequent layer:

In DocLLM, the input is represented as x = {(xi, bi)}. To capture the spatial information, the bounding boxes are encoded into hidden vectors represented by S. Then the attention matrix computation is decomposed into four different scores, namely text-to-text, text-to-spatial, spatial-to-text and spatial-to-spatial. Formally, the new attention mechanism is calculated as:

where Ws,q and Ws,k are newly introduced projection matrices corresponding to the spatial modality, and λs are hyperparameters that control the relative importance of each score. The input hidden vectors for the next layer H′ are computed exactly as before.
Note that the hidden vectors S are reused across different layers, while each layer retains the flexibility to employ different projection matrices.
Model Setup and Training Details
Using pre-trained weights as the backbone for the text modality, the Falcon-1B and Llama2–7B models are extended by adding the disentangled attention and block infilling objective.

The maximum sequence length, or context length, is consistently set to 1,024 for both versions during the entire training process.
Pretraining
DocLLM is pre-trained in an autoregressive fashion on a large number of unlabeled documents. Since visual documents are often sparse and irregular, featuring isolated and disconnected text fragments, it is preferable to consider coarse segments of related tokens during pre-training rather than focusing on individual tokens.
Furthermore, learning to infill text, where the prediction is conditioned on both prefix and suffix tokens rather than only preceding tokens, can be beneficial. The infilling objectives enable contextually relevant completions, provide robustness to OCR noise or misaligned tokens, and can better handle relationships between various document fields. Hence the standard pre-training objective is modified to predict blocks of text given preceding and following text blocks.
Formally, let c = {c1, …, cK} be a set of text blocks that partitions an input sequence x into non-overlapping contiguous tokens. Let z = {zm} be M ≪K different text blocks randomly sampled from c, where each block zm = (zm,1, …, zm,Nm ) contains a consecutive series of tokens. Further, let ˜x be a corrupted version of x where the contiguous tokens corresponding to a sampled text block are replaced with a special mask token [M].To facilitate the identification of the block to be filled during text generation, each input block is augmented with a special start token [S] while the output block includes an end token [E]. For instance, a block with tokens (x4, x5) becomes [M] in ˜x, ([S], x4, x5) when conditioned upon, and is expected to generate (x4, x5, [E]) as output autoregressively.
The following cross-entropy loss is then minimized for the infilling objective.
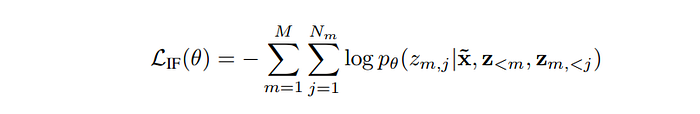
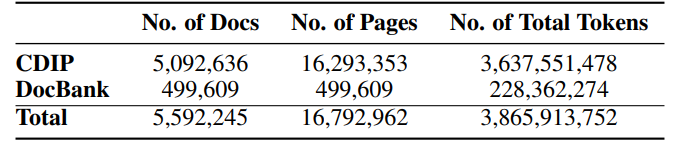
The data for pre training is gathered from two primary sources: (1) IIT-CDIP Test Collection 1.0 and (2) DocBank.
Instruction Tuning
DocLLM is instruction-tuned on 16 datasets, spanning four DocAI tasks:
- Visual Question Answering (VQA): DocVQA, WikiTableQuestions (WTQ),VisualMRC, DUDE, BizDocs.
- Natural Language Inference (NLI): TabFact.
- Key Information Extraction (KIE): Kleister Charity (KLC), CORD, FUNSD, DeepForm, PWC, SROIE, VRDU ad-buy, BizDocs.
- Document Classification (CLS): RVL-CDIP, BizDocs.

The following instruction templates are used based on what end users would generally ask about documents

Evaluation
Experimental Settings:
- SDDS (Same Datasets, Different Splits): Evaluates DocLLM on unseen test/dev splits of 16 datasets to assess performance when tasks/domains remain constant.
- STDD (Same Tasks, Different Datasets): Assesses DocLLM on held-out datasets from instruction-tuning, focusing on unchanged tasks but varying domains/layouts.
Baselines:
Benchmark:
- DocLLM against similarly sized SOTA LLMs using ZeroShot prompts.
- Exclude models needing task-specific fine-tuning or dataset-specific prompts, focusing on LLMs with out-of-the-box instruction following.
Metrics Used:
- ANLS for most VQA datasets
- CIDEr for VisualMRC
- Accuracy for WTQ and CLS/NLI datasets
- F1 score for KIE datasets
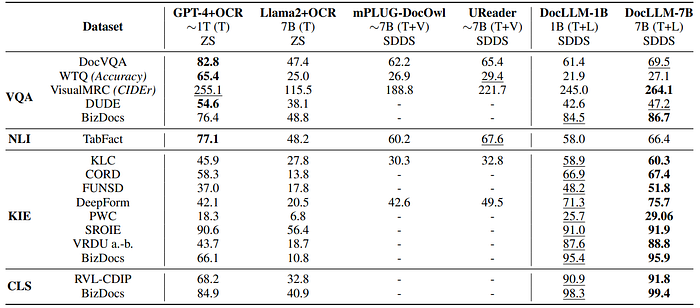
Results (SDDS Setting):
- DocLLM-7B outperforms in 12 out of 16 datasets compared to GPT4 and other models like Llama2, mPLUG-DocOwl, and UReader.
- Demonstrates superior performance in layout-intensive tasks like KIE and CLS; competitive performance in VQA and NLI, slightly underperforming against GPT-4 in VQA.
- DocLLM-1B shows performance close to the larger model, indicating significant benefits from the DocLLM architecture for smaller models.
Results (STDD Setting):
- Outperforms Llama2 in four out of five datasets, excelling notably in KIE tasks.
- Surpasses mPLUG-DocOwl and UReader on DocVQA and KLC despite their instruction-tuning on these datasets.
- However, classification accuracy is notably lower in DocLLM, potentially due to limited training on only one classification dataset.
Paper
DocLLM: A layout-aware generative language model for multimodal document understanding 2401.00908
Recommended Reading: [Document Information Processing]
Hungry for more insights?
Don’t miss out on exploring other fascinating threads in this series. Simply click here and uncover the state-of-the-art research!
Do Subscribe for weekly updates!!
