Papers Explained 81: An In-depth Look at Gemini’s Language Abilities

A third-party, objective comparison of the abilities of the OpenAI GPT and Google Gemini models with reproducible code and fully transparent results. Code and data for reproduction can be found at github.
Recommended Reading: [Papers Explained 80: Gemini 1.0]
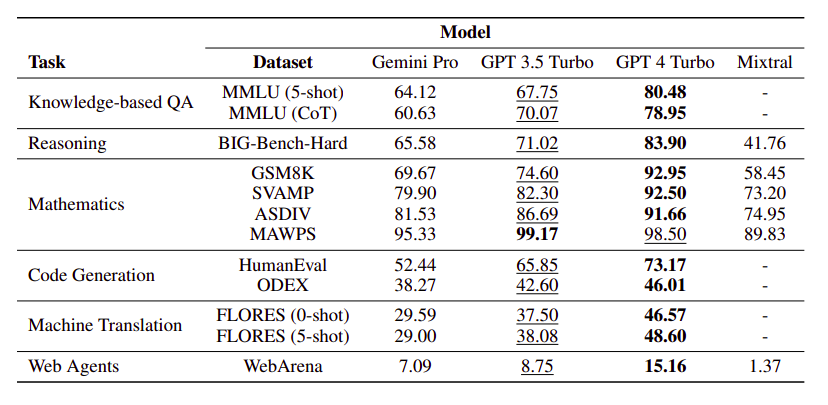
Across all tasks, as of December 19, 2023 Gemini’s Pro model achieved comparable but slightly inferior accuracy compared to the current version of OpenAI’s GPT 3.5 Turbo.
Knowledge-based QA

- Gemini Pro’s accuracy is lower than GPT 3.5 Turbo and notably lower than GPT 4 Turbo.
- Chain-of-thought prompting doesn’t significantly impact performance, suggesting limited benefits for knowledge-based tasks.

- Gemini Pro shows a biased label distribution, favoring the final choice “D” in multiple-choice questions.


- Gemini Pro underperforms on most tasks compared to GPT 3.5, particularly in social sciences, humanities, STEM, and specialized domains.
- Gemini Pro Failure to return answers in some cases (notably in moral_scenarios and human_sexuality tasks).
- Poor performance in basic mathematical reasoning tasks like formal_logic and elementary_mathematics.

- Stronger models tend to output longer responses indicating complex reasoning.
- Gemini Pro’s accuracy is less influenced by output length, outperforming GPT 3.5 with longer responses.
- Gemini Pro and GPT 3.5 Turbo rarely produce long reasoning chains compared to GPT 4 Turbo.
General-purpose Reasoning
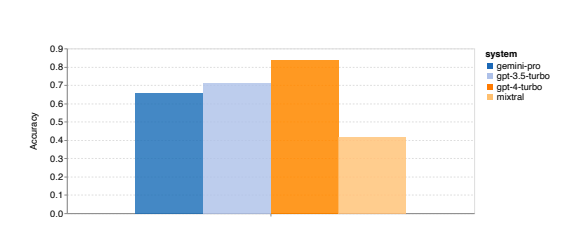
- Gemini Pro slightly underperforms compared to GPT 3.5 Turbo and significantly to GPT 4 Turbo.
- Mixtral model shows notably lower accuracy.
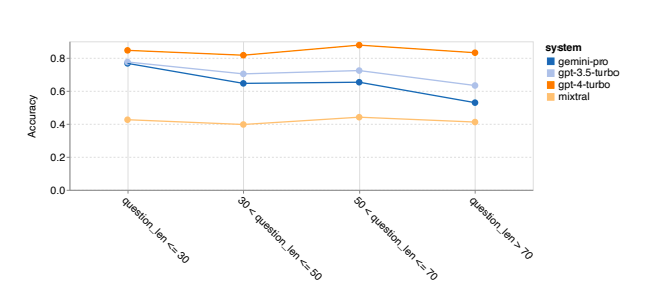
- Gemini Pro underperforms on longer, complex questions.
- GPT models, especially GPT 4 Turbo, exhibit robustness with minimal accuracy degradation on longer queries.
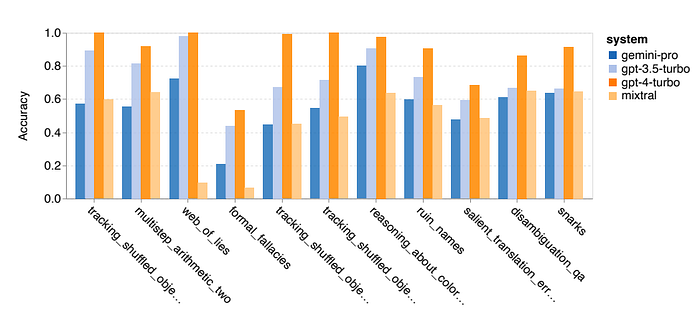
- Gemini Pro notably struggles with ‘tracking_shuffled_objects’ tasks due to difficulty in maintaining object order.
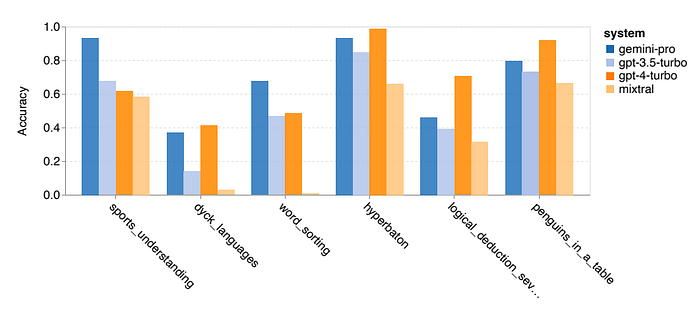
- Gemini Pro outperforms GPT 3.5 Turbo in tasks involving world knowledge, symbol manipulation, word sorting, and table parsing.

- Gemini Pro performs poorly in Valid/Invalid answers for formal fallacies tasks.
- Excels in word rearrangement and symbol order tasks but struggles with multiple-choice questions.
- No distinct trend in task performance superiority between Gemini and GPT models for general-purpose reasoning.
- Suggestion to consider both Gemini and GPT models before choosing for such tasks.
Mathematics
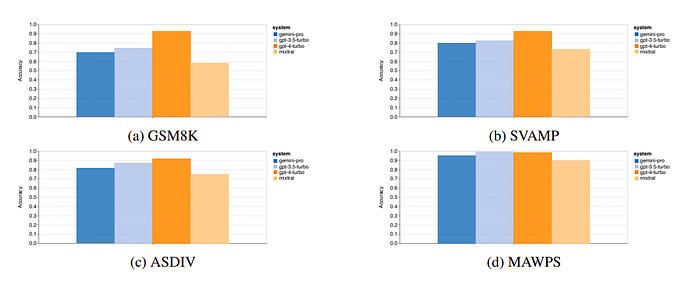
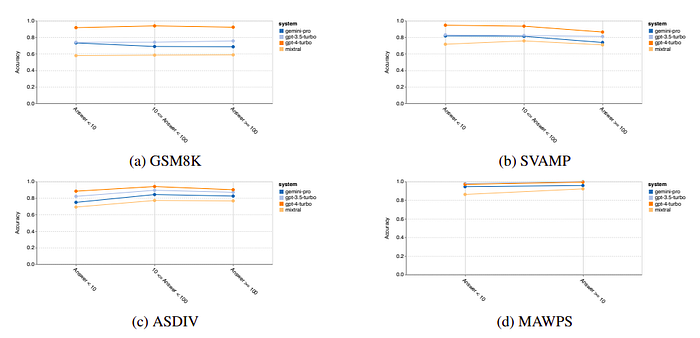
- Gemini Pro achieved slightly lower accuracy than GPT 3.5 Turbo and significantly lower accuracy than GPT 4 Turbo on benchmarks like GSM8K, SVAMP, and ASDIV, which involve diverse language patterns.
- All models performed well on the MAWPS benchmark, with over 90% accuracy, though Gemini Pro lagged slightly behind GPT models. Notably, GPT 3.5 Turbo outperformed GPT 4 Turbo on this benchmark.
- Mixtral model showed significantly lower accuracy compared to others.
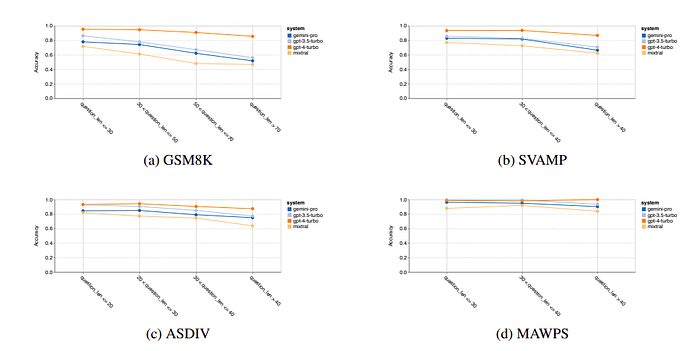
- Longer questions led to decreased accuracy for all models, similar to the trend observed in reasoning tasks on BIG-Bench Hard.
- GPT 3.5 Turbo outperformed Gemini Pro on shorter questions but dropped off more quickly. Gemini Pro showed comparable accuracy on longer questions.
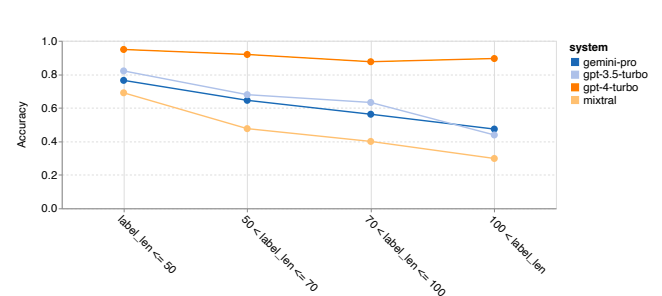
- GPT 4 Turbo demonstrated robustness even with longer chains of thought compared to GPT 3.5 Turbo, Gemini Pro, and Mixtral.
- Gemini Pro outperformed GPT 3.5 Turbo in the most complex examples with chain-of-thought lengths exceeding 100 but performed worse in shorter examples.
- Models’ performance varied concerning the number of digits in the answers.
- GPT 3.5 Turbo appeared more robust with multi-digit math problems, while Gemini Pro degraded more on problems with more digits.
Code Generation

- Gemini Pro’s Pass@1 is lower than GPT 3.5 Turbo and much lower than GPT 4 Turbo on both tasks.
- Indicates that Gemini’s code generation capabilities need improvement.
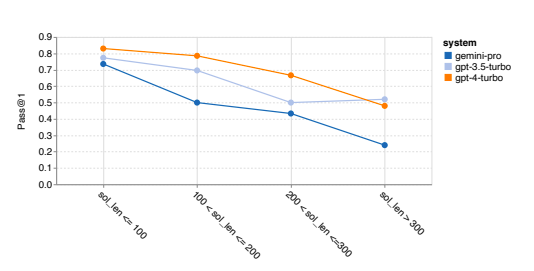
- Gemini Pro compares favourably with GPT 3.5 on easier cases (solution length below 100).
- Falls significantly behind as the solution length increases.
- Contrast to previous sections where Gemini Pro performed well with longer inputs and outputs in English language tasks.
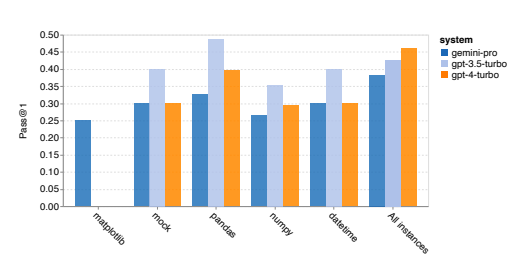
- Gemini Pro performs worse than GPT 3.5 on most library-used cases like mock, pandas, numpy, and datetime.
- Outperforms GPT 3.5 and GPT 4 on matplotlib cases, showcasing stronger capabilities in drawing visualization via code.
- Gemini Pro performs worse than GPT 3.5 in choosing functions and arguments from the Python API.
Machine Translation
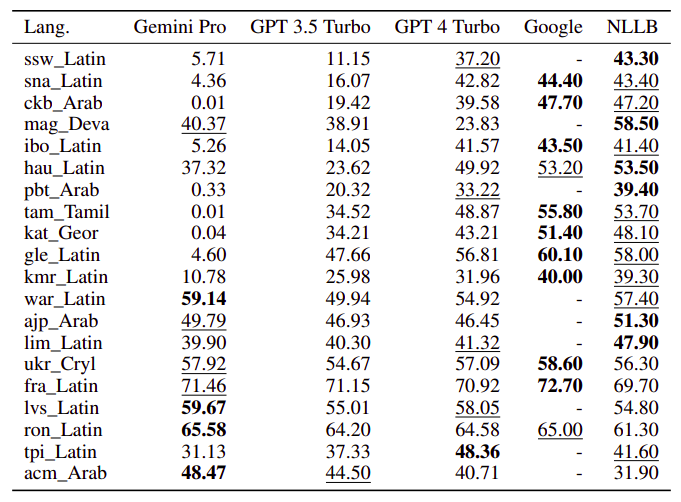
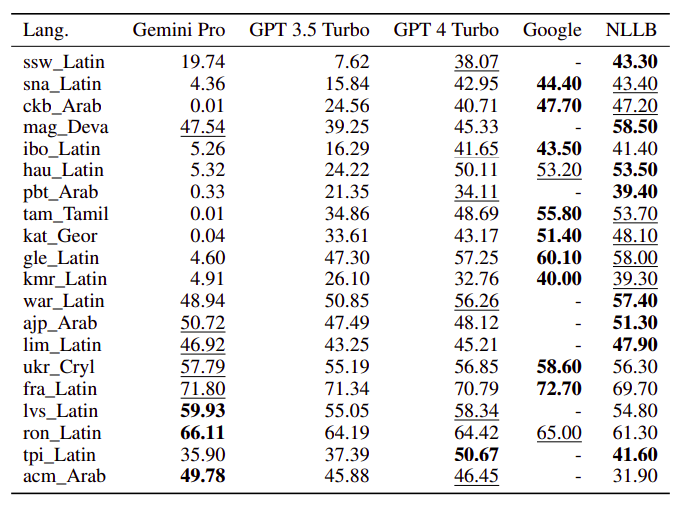
- Compared Gemini Pro, GPT 3.5 Turbo, and GPT 4 Turbo against Google Translate and NLLB-MoE.
- Google Translate generally outperformed, followed by NLLB in specific settings.
- Gemini Pro outperformed GPT 3.5 Turbo and GPT 4 Turbo in some languages but exhibited blocking tendencies.
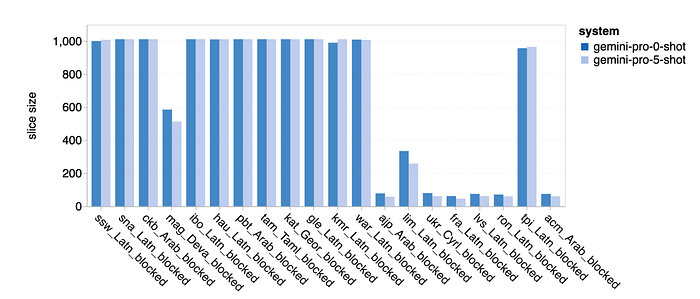
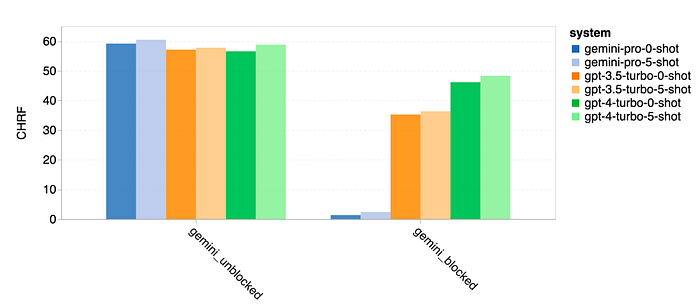
- Gemini Pro demonstrated lower performance due to a tendency to block responses in some language pairs.
- Performance outperformed GPT 3.5 Turbo and GPT 4 Turbo in unblocked samples with higher confidence.
- GPT 4 Turbo and GPT 3.5 Turbo faced challenges in translating specific samples.
- Gemini Pro’s subpar performance noted when 0-shot blocked responses, but 5-shot did not, and vice versa.
- Few-shot prompts generally led to a modest enhancement in average performance.
- Increasing variance pattern observed: GPT 4 Turbo < GPT 3.5 Turbo < Gemini Pro.
Web Agents

- Gemini-Pro performed slightly worse overall compared to GPT-3.5-Turbo.
- Outperformed GPT-3.5-Turbo on multi-site tasks but worse on gitlab and maps.
- Showed similar performance to GPT-3.5-Turbo on shopping admin and reddit tasks.
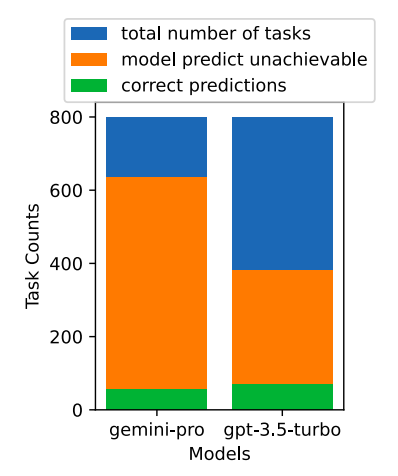
- Gemini-Pro tended to predict tasks as unachievable more often, especially when given a UA hint.
- Predicted over 80.6% of tasks as unachievable with a UA hint, compared to GPT-3.5-Turbo’s 47.7%.
- Both models significantly over-predicted unachievable tasks (4.4% actual).
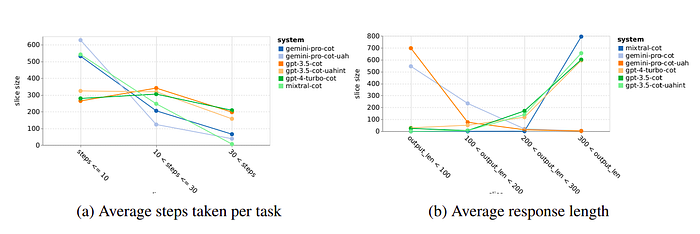
- Gemini-Pro tended to respond with shorter phrases and fewer steps to reach conclusions.
- More than half of Gemini trajectories were under ten steps, while others typically ranged between 10 and 30 steps for GPT 3.5 Turbo and GPT 4 Turbo.
- Majority of Gemini responses were less than 100 characters, whereas other models produced responses over 300 characters.
Conclusion
The Gemini Pro model, which is comparable to GPT 3.5 Turbo in model size and class, generally achieves accuracy that is comparable but somewhat inferior to GPT 3.5 Turbo, and much worse than GPT 4. It outperforms Mixtral on every task that we examined.
In particular, we find that Gemini Pro was somewhat less performant than GPT 3.5 Turbo on average, but in particular had issues of bias to response order in multiple-choice questions, mathematical reasoning with large digits, premature termination of agentive tasks, as well as failed responses due to aggressive content filtering.
On the other hand, there were bright points: Gemini performed better than GPT 3.5 Turbo on particularly long and complex reasoning tasks, and also was adept multilingually in tasks where responses were not filtered.
Paper
An In-depth Look at Gemini’s Language Abilities 2312.11444
Hungry for more insights?
Don’t miss out on exploring other fascinating threads in this series. Simply click here and uncover the state-of-the-art research!
Do Subscribe for weekly updates!!
