Papers Explained 79: DETR

DEtection TRansformer or DETR streamlines the detection pipeline, effectively removing the need for many hand-designed components like a non-maximum suppression procedure or anchor generation that explicitly encode the prior knowledge about the task using a set-based global loss that forces unique predictions via bipartite matching, and a transformer encoder-decoder architecture.

Object detection set prediction loss
DETR infers a fixed-size set of N predictions, in a single pass. This causes difficulties in training to score the predicted objects wrt. to the ground truth. Hence a bipartite matching between predicted and ground truth objects is required before loss optimization.
Ground Truth and Predictions:
y: The ground truth set of objects in an image.ˆy: The set of N predictions made by the model.- It’s important to note that
Nis assumed to be larger than the actual number of objects in the image.yis also considered as a set of size N but padded with empty objects (∅) for objects that are not present.
Finding Bipartite Matching:
- The next step is to find a matching (correspondence) between the ground truth objects and the model’s predictions. This is done by searching for a permutation
σof N elements that minimizes a certain cost function. - The cost function
Lmatch(yi, yˆσ(i))quantifies the similarity between a ground truth objectyiand a prediction with indexσ(i). This cost function takes into account both the class prediction and the similarity of the predicted and ground truth bounding boxes. - The optimal assignment (
ˆσ) is computed efficiently using the Hungarian algorithm.

Matching Cost Function:
Lmatch(yi, yˆσ(i)):

- If
ci(target class label) is not empty (∅), the cost includes the negative log-likelihood of the predicted class (ˆpσ(i)(ci)) and a box loss term (Lbox(bi, ˆbσ(i))). - The function
1{ci6=∅}is an indicator function that equals 1 whenciis not empty and 0 otherwise. - The goal is to encourage the model to predict the correct class and bounding box when the ground truth object is not empty.
Loss Calculation:
- Once the optimal assignment (
ˆσ) is found, the loss functionLHungarian(y, yˆ)is computed. This loss is defined as a sum over all matched pairs: - It includes a negative log-likelihood term for class prediction and a box loss term.
- The log-probability term is down-weighted when
ciis empty (∅) to account for class imbalance. - The matching cost between an object and an empty prediction (∅) is considered constant.
- The log-probabilities are used instead of log-probabilities because it improves empirical performance.
Bounding Box Loss (Lbox):
- The second part of the matching cost and the Hungarian loss is a box loss (
Lbox(bi, ˆbσ(i))) that scores the predicted bounding boxes. - Instead of predicting bounding box offsets (∆) relative to initial guesses, this approach directly predicts bounding box coordinates.
- To address scaling issues in the loss, a combination of
L1loss and generalized Intersection over Union (IoU) loss is used. The IoU loss is scale-invariant. - The hyperparameters
λiouandλL1are used to control the contributions of these loss components. - Both the class prediction loss and box loss are normalized by the number of objects inside the batch.
DETR architecture
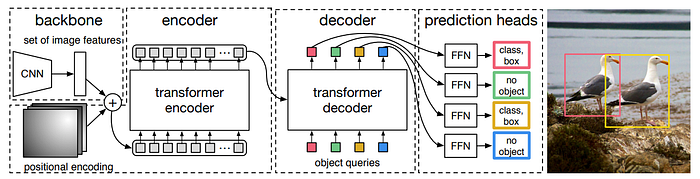
DETR contains three main components. a CNN backbone to extract a compact feature representation, an encoder-decoder transformer, and a simple feed forward network (FFN) that makes the final detection prediction.
Backbone
Starting from the initial image x, a conventional CNN backbone generates a lower-resolution activation map f. Typically, C = 2048, H, W = H0/32, W0/32.
Transformer encoder
First, a 1x1 convolution reduces the channel dimension of the high-level activation map f from C to a smaller dimension d. creating a new feature map z0. The encoder expects a sequence as input, hence we collapse the spatial dimensions of z0 into one dimension, resulting in a d×HW feature map. Since the transformer architecture is permutation-invariant, it is supplemented with fixed positional encodings that are added to the input of each attention layer.
Transformer decoder
The decoder follows the standard architecture of the transformer, transforming N embeddings of size d using multi-headed self- and encoder-decoder attention mechanisms. Unlike the original transformer this model decodes the N objects in parallel at each decoder layer.
Since the decoder is also permutation-invariant, the N input embeddings must be different to produce different results. These input embeddings are learnt positional encodings that are referred to as object queries, and similarly to the encoder, are added to the input of each attention layer.
The N object queries are transformed into an output embedding by the decoder. They are then independently decoded into box coordinates and class labels by a feed forward network resulting in N final predictions.
Prediction feed-forward networks (FFNs)
The final prediction is computed by a 3-layer perceptron with ReLU activation function and hidden dimension d, and a linear projection layer. The FFN predicts the normalized center coordinates, height and width of the box w.r.t. the input image, and the linear layer predicts the class label using a softmax function.
Evaluation
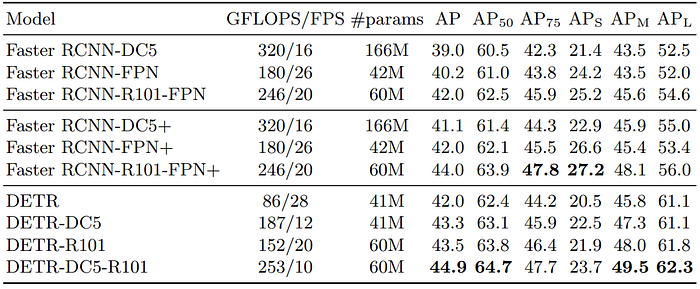
- The experiments are conducted on COCO 2017 detection and panoptic segmentation datasets, which contain 118k training images and 5k validation images with bounding box and panoptic segmentation annotations.
- Results are reported using two different backbones, ResNet50 and ResNet-101, with variations that involve increasing feature resolution with dilation and removing stride.
- Scale augmentation and random crop augmentations are applied during training to improve the model’s performance.
- DETR achieves competitive results compared to Faster R-CNN in quantitative evaluation on the COCO dataset.
- DETR is noted to improve the Average Precision for Large (APL) while lagging behind in Average Precision for Small (APS) compared to Faster R-CNN. ResNet-101 backbones in both DETR and Faster R-CNN show comparable results.
Paper
End-to-End Object Detection with Transformers 2005.12872
Hungry for more insights?
Don’t miss out on exploring other fascinating threads in this series. Simply click here and uncover the state-of-the-art research!
Do Subscribe for weekly updates!!
