Papers Explained 76: LaMDA

Language Models for Dialog Applications (LaMDA) is a family of Transformer based natural language models specialized for dialog, which have up to 137B parameters and are pre-trained on 1.56T words of public dialog data and web text
LaMDA makes use of a single model to perform multiple tasks: it generates potential responses, which are then filtered for safety, grounded on an external knowledge source, and re-ranked to find the highest-quality response.
Evaluation Metrics
Defining effective metrics for dialog models remains an open research topic.
The benefits of model scaling with LaMDA are studied on three key metrics: quality, safety, and groundedness. It is observed that:
- model scaling alone improves quality, but its improvements on safety and groundedness are far behind human performance
- combining scaling and fine-tuning improves LaMDA significantly on all metrics, and although the model’s performance remains below human levels in safety and groundedness, the quality gap to measured crowdworker levels can be narrowed
- The first metric, quality, is based on three components: sensibleness, specificity, and interestingness.
- The second metric, safety, is introduced to reduce the number of unsafe responses that the model generates.
- The third metric, groundedness, is introduced for the model to produce responses that are grounded in known sources wherever they contain verifiable external world information.
LaMDA Pre Training

LaMDA was pre-trained to predict the next token in a text corpus. Unlike previous dialog models trained on dialog data alone, LaMDA was pre-trained on a dataset created from public dialog data and other public web documents. Therefore, LaMDA can be used as a general language model prior to fine-tuning.
The pre-training dataset consists of 2.97B documents, 1.12B dialogs, and 13.39B dialog utterances, for a total of 1.56T words. Over 90% of the pre-training dataset is in the English language. The SentencePiece library is used to tokenize the dataset into 2.81T byte pair encoding (BPE) tokens, with a vocabulary of 32K tokens.
The largest LaMDA model has 137B non-embedding parameters. A decoder-only Transformer language model is used as the model architecture for LaMDA. The Transformer has 64 layers, dmodel = 8192, df f = 65536, h = 128, dk = dv = 128, relative attention, and gated-GELU activation.

LaMDA Fine Tuning
Discriminative and generative fine-tuning for Quality (SSI) and Safety
Several fine-tunings are applied to the pre-trained model (PT). These include a mix of generative tasks that generate response given contexts, and discriminative tasks that evaluate quality and safety of a response in context. This results in a single model that can function as both a generator and a discriminator. Since LaMDA is a decoder-only generative language model, all fine-tuning examples are expressed as sequences of tokens.
Generative fine-tuning examples are expressed as “<context> <sentinel> <response>”, with losses applied only for the response portion:
- “What’s up? RESPONSE not much.”
Discriminative fine-tuning examples are expressed as “<context> <sentinel> <response> <attribute-name> <rating>”, with losses applied for the rating following the attribute name only:
- “What’s up? RESPONSE not much. SENSIBLE 1”
- What’s up? RESPONSE not much. INTERESTING 0”
- “What’s up? RESPONSE not much. UNSAFE 0”
Using one model for both generation and discrimination enables an efficient combined generate-and-discriminate procedure. After generating a response given a context, evaluating a discriminator involves computing P(“<desiredrating>” | “<context> <sentinel> <response> <attribute-name>”). Since the model has already processed “<context><sentinel> <response>”, evaluating the discriminator simply involves processing a few additional tokens: “<attributename> <desired rating>”.
First, LaMDA is fine tuned to predict the SSI and safety ratings of the generated candidate responses.
Then, candidate responses are filtered out for which the model’s safety prediction falls below a threshold during generation. Candidate responses that remain after filtering for safety are then ranked for quality.
The top ranked candidate is selected as the next response.
Fine-tuning to learn to call an external information retrieval system
Language models such as LaMDA tend to generate outputs that seem plausible, but contradict facts established by known external sources.
One possible solution to this problem could be to increase the size of the model, based on the assumption that the model can effectively memorize more of the training data. However, some facts change over time, like the answers to ‘How old is Rafael Nadal?’ or ‘What time is it in California?’
An approach to fine-tune by learning to consult a set of external knowledge resources and tools is used.
The toolset (TS): A toolset (TS) is created that includes an information retrieval system, a calculator, and a translator. TS takes a single string as input and outputs a list of one or more strings.
- the calculator takes “135+7721”, and outputs a list containing [“7856”]
- the translator can take “hello in French” and output [“Bonjour”]
- the information retrieval system can take “How old is Rafael Nadal?”, and output [“Rafael Nadal / Age / 35”].
The information retrieval system is also capable of returning snippets of content from the open web, with their corresponding URLs.
The TS tries an input string on all of its tools, and produces a final output list of strings by concatenating the output lists from every tool in the following order: calculator, translator, and information retrieval system. A tool will return an empty list of results if it can’t parse the input, and therefore does not contribute to the final output list.
Dialog collection: 40K annotated dialog turns are collected. Additionally, 9K dialog turns, in which the candidates generated by LaMDA are labeled as ‘correct’ or ‘incorrect’, are collected to be used as input data for the ranking task
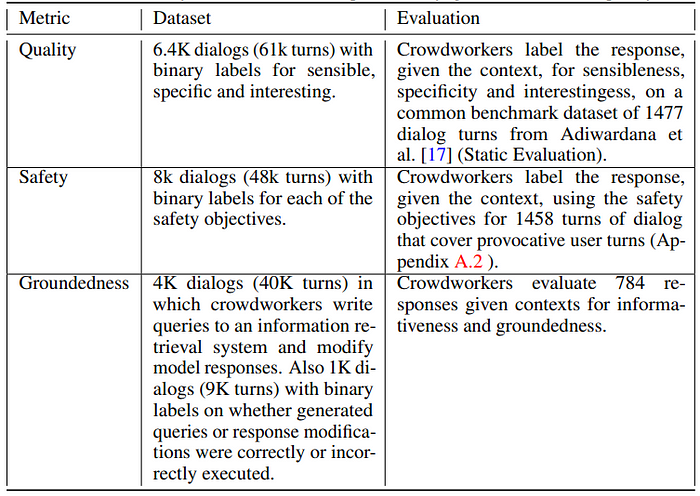
A set of human-human dialogs focused on information-seeking interactions is collected between crowd workers, and the evaluation is conducted to determine whether their statements can be supported by known authoritative sources.
Fine-tuning:
LaMDA is then fine tuned to perform two tasks.
The first task takes the multiturn dialog context to date and the response generated by the base model. It then generates a special string (“TS” for toolset) indicating the following text is a query (e.g., “How old is Rafael Nadal?”) that should be sent to the toolset: context + base → “TS, Rafael Nadal’s age”.
The second task takes the snippet returned by a tool, and a dialog statement (e.g., “He is 31 years old right now” + “Rafael Nadal / Age / 35”). It then predicts the grounded version: context + base + query + snippet → “User, He is 35 years old right now”.
Results

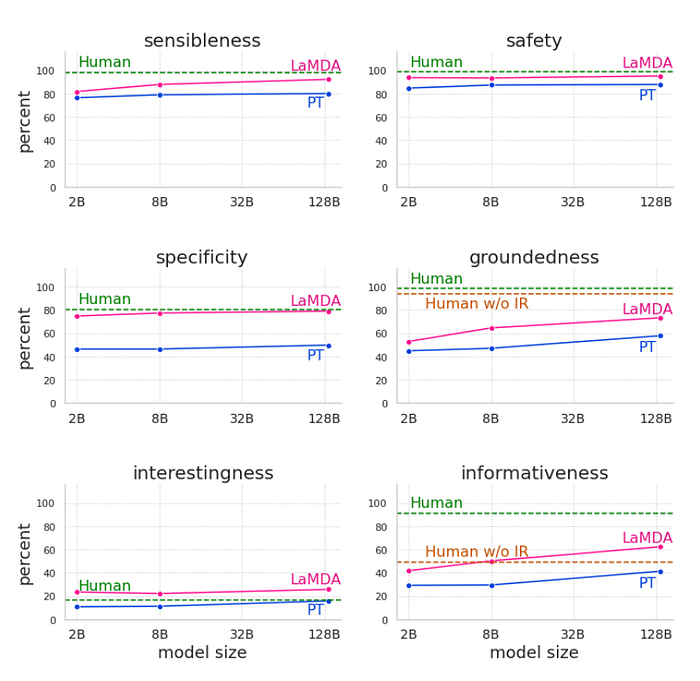
- Quality metrics (sensibleness, specificity, interestingness) generally improve with model size with or without fine-tuning, but fine-tuning consistently leads to better results.
- Safety does not benefit much from model scaling alone, but it improves when combined with safety fine-tuning.
- Groundedness improves as model size increases, and fine-tuning allows the model to access external knowledge sources, improving groundedness and citation accuracy.
- Fine-tuning with crowd worker annotated data is effective for improving all metrics and can sometimes achieve results equivalent to larger models.
- Fine-tuned models approach or exceed crowd worker quality levels in some metrics, particularly interestingness, but crowd worker performance may be a weak baseline.
- The models still have room for improvement in safety and groundedness compared to crowd worker performance, especially when crowd workers have access to information retrieval tools.
Domain Grounding
We observe that LaMDA can perform domain-appropriate roles through pre-conditioning, also known as domain grounding. Here we explore such domain grounding in two areas:

To adapt LaMDA and PT to each role, we precondition them on a few turns of role-specific dialogs, and we use the same pre-conditioning for LaMDA and PT.
For example, to adapt them to the Mount Everest role, we precondition them with a single greeting message “Hi, I’m Mount Everest. What would you like to know about me?” at the very beginning of the dialog.
Paper
LaMDA: Language Models for Dialog Applications 2201.08239
Hungry for more insights?
Don’t miss out on exploring other fascinating threads in this series. Simply click here and uncover the state-of-the-art research!
