Papers Explained 46: FLAN

This paper explores a simple method for improving the zero-shot learning abilities of language models, and shows that instruction tuning (finetuning language models on a collection of datasets described via instructions) substantially improves zero-shot performance on unseen tasks.
A 137B parameter pretrained language model is instruction tuned on over 60 NLP datasets verbalized via natural language instruction templates. This instruction-tuned model called FLAN, is then evaluated on unseen task types.

Instruction Fine Tuning

The motivation for instruction tuning is to improve the ability of language models to respond to NLP instructions. The idea is that by using supervision to teach an LM to perform tasks described via instructions, the LM will learn to follow instructions and do so even for unseen tasks. To evaluate performance on unseen tasks, we group datasets into clusters by task type and hold out each task cluster for evaluation while instruction tuning on all remaining clusters.
Task and Templates
We aggregate 62 text datasets that are publicly available, including both language understanding and language generation tasks, into a single mixture. Each dataset is categorized into one of twelve task clusters, for which datasets in a given cluster are of the same task type.

For each dataset, we manually compose ten unique templates that use natural language instructions to describe the task for that dataset. While most of the ten templates describe the original task, to increase diversity, for each dataset we also include up to three templates that “turned the task around”.

Evaluation Splits
We use a more conservative definition that leverages the task clusters. In this work, we only consider dataset D unseen at evaluation time if no datasets from any task clusters that D belongs to were seen during instruction tuning. For instance, if D is an entailment task, then no entailment datasets appeared in instruction tuning, and we instruction-tuned on all other clusters.1 Hence, to evaluate zero-shot FLAN on c task clusters, we instruction tune c models, where each model holds out a different task cluster for evaluation.
Training Details
Model architecture and pretraining
In our experiments, we use LaMDA-PT, a dense left-to-right, decoder-only transformer language model of 137B parameters. This model is pretrained on a collection of web documents (including those with computer code), dialog data, and Wikipedia tokenized into 2.49T BPE tokens with a 32k vocabulary using the SentencePiece. Around 10% of the pretraining data were non-English.
Instruction tuning procedure
Our instruction tuning pipeline mixes all datasets and randomly samples from each dataset. To balance the different sizes of datasets, we limit the number of training examples per dataset to 30k and follow the examples-proportional mixing scheme with a mixing rate maximum of 3k. The input and target sequence lengths used in finetuning are 1024 and 256, respectively.
Results
We evaluate FLAN on natural language inference, reading comprehension, closed-book QA, translation, commonsense reasoning, coreference resolution, and struct-to-text.
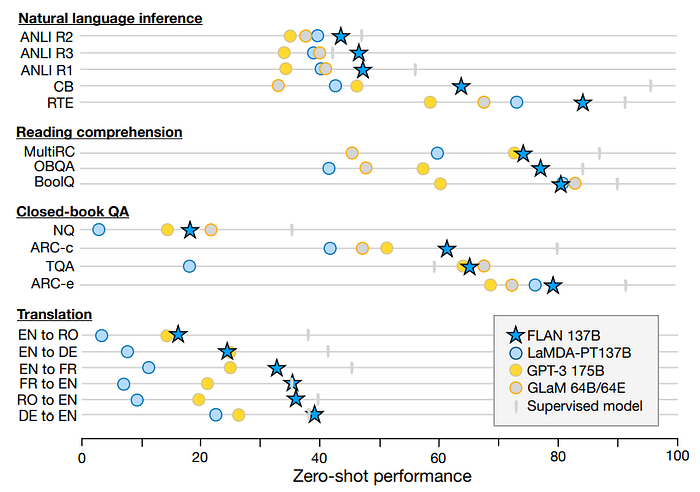
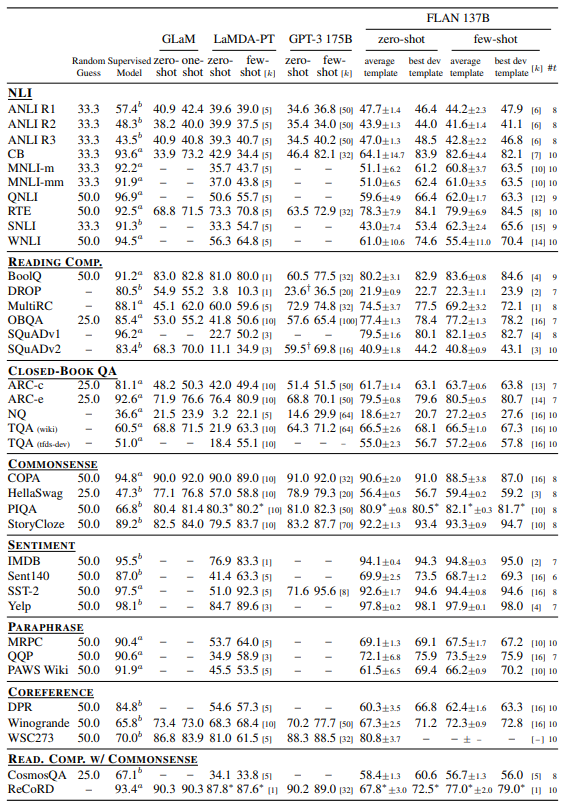
- Natural language inference (NLI) On five NLI datasets, where a model must determine whether a hypothesis is true given some premise, FLAN outperforms all baselines by a large margin. For FLAN, we phrase NLI as the more natural question “Does mean that ?”, achieving much higher performance.
- Reading comprehension On reading comprehension, where models are asked to answer a question about a provided passage, FLAN outperforms baselines for MultiRC and OBQA. On BoolQ, FLAN outperforms GPT-3 by a large margin, though LaMDA-PT already achieves high performance on BoolQ.
- Closed-book QA For closed-book QA, which asks models to answer questions about the world without access to specific information containing the answer, FLAN outperforms GPT-3 on all four datasets. Compared to GLaM, FLAN has better performance on ARC-e and ARC-c, and slightly lower performance on NQ and TQA.
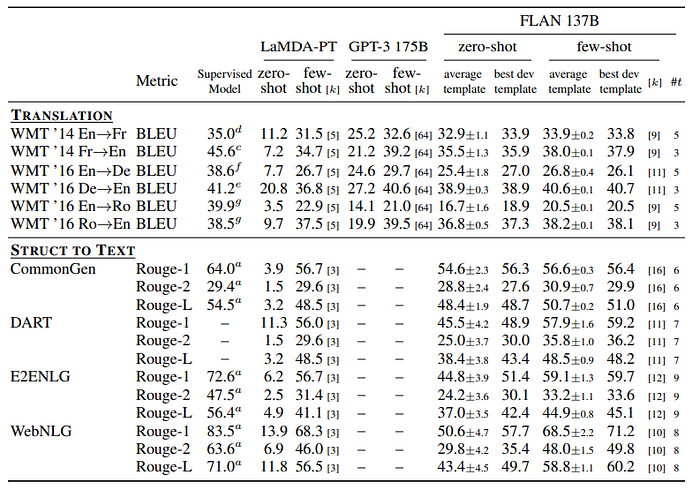
- Translation Similar to GPT-3, the training data for LaMDA-PT is around 90% English and includes some text in other languages that were not specifically used to train the model to perform machine translation. We also evaluate FLAN’s performance on machine translation for the three datasets evaluated in the GPT-3 paper: French-English from WMT’14, and German-English and Romanian-English from WMT’16. Compared with GPT-3, FLAN outperforms zero-shot GPT-3 for all six evaluations, though it underperforms few-shot GPT-3 in most cases. Similar to GPT-3, FLAN shows strong results for translating into English and compares favorably against supervised translation baselines. Translating from English into other languages, however, was relatively weaker, as might be expected given that FLAN uses an English sentencepiece tokenizer and that the majority of pretraining data is in English.
- Additional tasks Although we see strong results for the above task clusters, one limitation with instruction tuning is that it does not improve performance for many language modeling tasks (e.g., commonsense reasoning or coreference resolution tasks formulated as sentence completions). For seven commonsense reasoning and coreference resolution tasks, FLAN only outperforms LaMDA-PT on three of the seven tasks. This negative result indicates that when the downstream task is the same as the original language modeling pre-training objective, instruction tuning is not useful.
Paper
Fine-tuned Language Models Are Zero-Shot Learners 2109.01652
Hungry for more insights?
Don’t miss out on exploring other fascinating threads in this series. Simply click here and uncover the state-of-the-art research!
Do Subscribe for weekly updates!!