Papers Explained 336: Rethinking Compute-Optimal Test-Time Scaling

This paper focuses on two core questions:
- What is the optimal approach to scale test-time computation across different policy models, PRMs, and problem difficulty levels?
- To what extent can extended computation improve the performance of LLMs on complex tasks, and can smaller language models outperform larger ones through this approach?
Through comprehensive experiments on MATH-500 and challenging AIME24 tasks, the following observations are made:
- The compute-optimal TTS strategy is highly dependent on the choice of policy model, PRM, and problem difficulty.
- With the compute-optimal TTS strategy, extremely small policy models can outperform larger models.
Setup
Policy Models: For test-time methods, policy models from Llama 3 and Qwen2.5 families with different sizes are used. The Instruct version is used for all policy models.
Process Reward Models: The following open-source PRMs are considered for evaluation:
- Math-Shepherd: Math-Shepherd-PRM-7B is trained on Mistral-7B using PRM data generated from Mistral-7B fine-tuned on MetaMath.
- RLHFlow Series: RLHFlow includes RLHFlow-PRM-Mistral-8B and RLHFlow-PRM-Deepseek-8B, which are trained on data from Mistral-7B fine-tuned on Meta- Math and deepseek-math-7b-instruct, respectively. The base model for both PRMs is Llama-3.1–8B-Instruct.
- Skywork Series: The Skywork series comprises Skywork-PRM- 1.5B and Skywork-PRM-7B, trained on Qwen2.5-Math-1.5B-Instruct and Qwen2.5-Math-7B- Instruct, respectively. The training data is generated from Llama-2 fine-tuned on a mathematical dataset and Qwen2-Math series models.
- Qwen2.5-MathSeries: Qwen2.5-MathSeries includes Qwen2.5-Math-PRM-7B and Qwen2.5-Math-PRM-72B, trained on Qwen2.5-Math-7B-Instruct and Qwen2.5-Math-72B-Instruct, respectively. The data for training is generated using Qwen2-Math and Qwen2.5-Math series models. Among all the PRMs listed, Qwen2.5-Math-PRM-72B is the strongest open-source PRM for mathematical tasks, while Qwen2.5-Math-PRM-7B is the most capable PRM among those with 7B/8B parameters.
TTS Methods: The following TTS methods are explored:

- Best-of-N: In the BoN approach, the policy model generates 𝑁 responses, after which scoring and voting methods are applied to select the final answer.
- Generate: Generate
Nindependent completions for the input prompt using the language model. - Score: Evaluate each of the
Ncompletions using the reward model, obtaining a score for each. - Select: Choose the completion with the highest reward score.
- Beam Search: Given beam width 𝑁 and beam size 𝑀, the policy model first generates 𝑁 steps. The verifier selects the top N/M steps for subsequent search. In the next step, the policy model samples 𝑀 steps for each selected previous step. This process repeats until the maximum depth is reached or an <EOS> token is generated.
- Initialize: Start with a beam containing only the initial prompt (or an empty string).
- Expand: Generate
npossible next tokens for each sequence in the beam. - Score: Score all the extended sequences using a reward model.
- Prune: Keep only the top
mhighest-scoring sequences. - Repeat: Iterate steps 2–4 until a stopping criterion is met.
- Select: Choose the highest-scoring complete sequence from the final beam.
- Diverse Verifier Tree Search: To increase diversity, DVTS extends beam search by dividing the search process into N/M subtrees, each of which is explored independently using beam search.
- Initialize: Start with a set of beams, possibly one per input prompt.
- Expand: Generate multiple next-token candidates for each active beam, considering a lookahead window to evaluate longer sequences.
- Score & Prune: Score all expanded sequences using the PRM, pruning lower-scoring and less diverse sequences. This process prioritizes maintaining diversity in the active beams.
- Repeat: Iterate steps 2–3 until a stopping criterion is met.
- Select: Choose the best completions from the final beams, considering both quality and diversity.
Scoring and Voting Methods:
Three scoring methods are considered:
- PRM-Min scores each trajectory by the minimum reward among all steps.
- PRM-Last scores each trajectory by the reward of the last step.
- PRM-Avg scores each trajectory by the average reward among all steps.
Three voting methods are considered:
- Majority Vote selects the answer with the majority of votes.
- PRM-Max selects the answer with the highest score.
- PRM-Vote first accumulates the scores of all identical answers and then selects the answer with the highest score.
Datasets: Experiments are conducted on competition-level mathematical datasets, including MATH-500 and AIME24.
The division of steps follows the format “\n\n” as in prior works. For beam search and DVTS, the beam width is set to 4. The temperature of CoT is 0.0, while it is 0.7 for other methods. For CoT and BoN, the maximum number of new tokens is restricted to 8192. For search-based methods, the token limit is 2048 for each step and 8192 for the total response.
The following questions are answered:
- Q1: How does TTS improve with different policy models and PRMs?
- Q2: How does TTS improve for problems with different difficulty levels?
- Q3: Does PRMs have bias towards specific response lengths or sensitivity to voting methods?
- Q4: Can smaller policy models outperform larger models with the compute-optimal TTS strategy?
- Q5: How does compute-optimal TTS improve compared with CoT and majority voting?
- Q6: Is TTS more effective than long-CoT-based methods?
Q1: How does TTS improve with different policy models and PRMs?

- PRM generalization is challenging: PRM performance varies significantly across different policy models and tasks, making generalization difficult, especially for complex tasks.

- TTS improvement is moderate even with increased compute: While increasing the compute budget improves Pass@k accuracy of policy models, the corresponding improvement in TTS performance is less pronounced.

- Optimal TTS method depends on the PRM: Best-of-N (BoN) is generally superior with Math-Shepherd and RLHFlow PRMs, while search-based methods are better with Skywork and Qwen2.5-Math PRMs. This is attributed to the limited generalization of PRMs across policy models. PRMs trained on Qwen2.5-Math-7B-Instruct generalize better than those trained on Mistral and Llama.
- TTS performance correlates with PRM process supervision abilities: A positive correlation exists between TTS performance and the process supervision abilities of PRMs, approximated by the function 𝑌 = 7.66 log(𝑋) + 44.31, where 𝑌 is TTS performance and 𝑋 represents PRM process supervision abilities.

- Optimal TTS method varies with policy model size: Search-based methods are more effective for smaller policy models, while BoN is better for larger models. This is because larger models have stronger reasoning capabilities and are less reliant on step-by-step verification.
Q2: How does TTS improve for problems with different difficulty levels?
Difficulty levels are categorized into three groups based on the absolute value of Pass@1 accuracy: easy (50% ∼ 100%), medium (10% ∼ 50%), and hard (0% ∼ 10%).
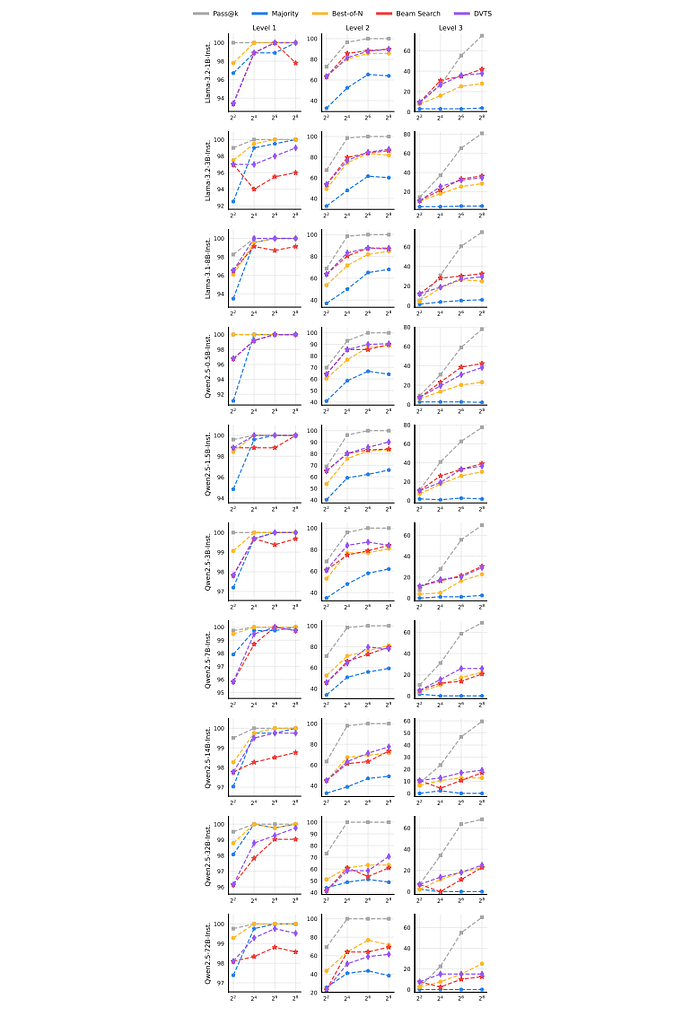
- The optimal TTS method depends on both the problem difficulty and the size of the policy model.
- For smaller policy models (<7B parameters), Best-of-N (BoN) performs better on easy problems, while beam search is superior for harder problems.
- For medium-sized policy models (7B-32B parameters), Diversity-guided Voting TTS (DVTS) is effective for easy and medium problems, while beam search is preferred for hard problems.
- For large policy models (72B parameters), BoN is the best performing method across all difficulty levels.
Q3: Does PRMs have bias towards specific response lengths or sensitivity to voting methods?
Bias towards response length

- PRMs exhibit a bias towards the length of the steps/responses observed in their training data.
- RLHFlow-PRM-Deepseek-8B consistently generates longer responses (nearly 2x the inference tokens) compared to RLHFlow-PRM-Mistral-8B, likely due to differences in the length of training data.
- Similarly, Qwen2.5-Math-7B generates more tokens than Skywork-PRM-7B for similar performance, suggesting Skywork-PRM-7B is more efficient.
Sensitivity to voting methods
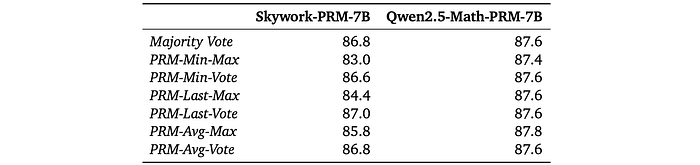
- PRMs show varying sensitivity to voting methods.
- Skywork-PRM-7B performs better with PRM-Vote than PRM-Max.
- Qwen2.5-Math-PRM-7B shows less sensitivity, likely due to its training data being processed with LLM-as-a-judge, which improves the reliability of high reward values.
- This highlights the importance of training data quality for effective error detection during search.
Q4: Can smaller policy models outperform larger models with the compute-optimal TTS strategy?
Smaller models with compute-optimal TTS significantly outperformed much larger models
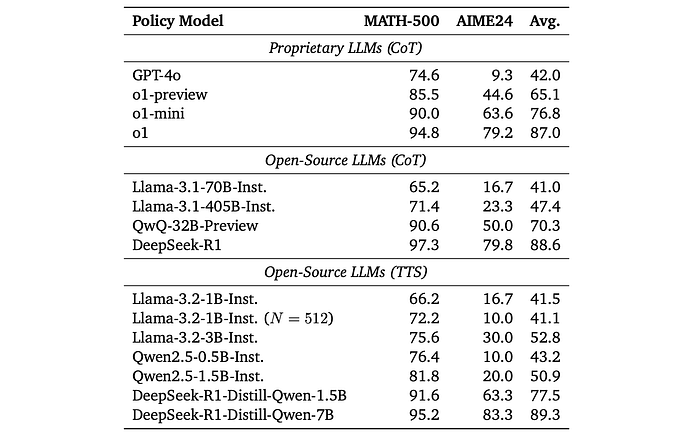
- Llama-3.2–3B-Instruct (with TTS) outperformed Llama-3.1–405B-Instruct (135x larger) on both MATH-500 and AIME24. This represents a 487% improvement over previous TTS research.
- Smaller models with TTS also outperformed GPT-4o on these tasks.
- DeepSeek-R1-Distill-Qwen-1.5B (with TTS) outperformed o1-preview and o1-mini.
- DeepSeek-R1-Distill-Qwen-7B (with TTS) outperformed o1 and DeepSeek-R1.
Compute-optimal TTS is more effective than simply increasing model size

- Small policy models with TTS achieved superior performance with 100x to 1000x fewer FLOPS compared to larger models.
Q5: How does compute-optimal TTS improve compared with CoT and majority voting?
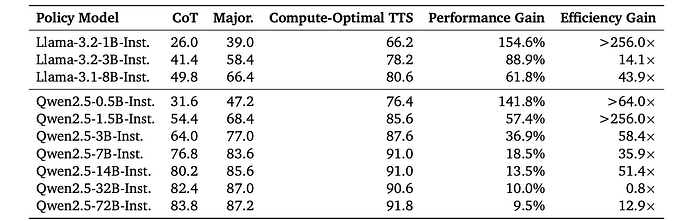
- Compute-optimal TTS can be 256 times more compute-efficient than majority voting.
- Compute-optimal TTS improves reasoning performance by 154.6% compared to CoT.
- The effectiveness of TTS is correlated with the reasoning ability of the policy model. Models with weaker reasoning abilities see greater improvement from increased test-time compute, while models with stronger reasoning abilities show limited gains.
- Increasing the number of parameters in the policy model leads to diminishing returns in TTS performance improvement.
Q6: Is TTS more effective than long-CoT-based methods?
The performance of TTS is compared against several established long-CoT methods (rStar-Math, Eurus-2, SimpleRL, Satori, and DeepSeek-R1-Distill-Qwen-7B).
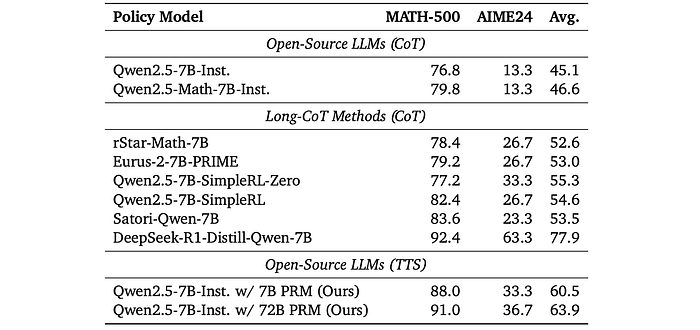
- TTS using Qwen2.5–7B-Instruct outperformed rStar-Math, Eurus-2, SimpleRL, and Satori on both MATH-500 and AIME24.
- TTS performed similarly to DeepSeek-R1-Distill-Qwen-7B on MATH-500 but significantly worse on AIME24.
- TTS is more effective than methods using direct Reinforcement Learning (RL) or Supervised Fine-Tuning (SFT) on data generated via Monte Carlo Tree Search (MCTS).
- TTS is less effective than methods that distill knowledge from stronger reasoning models.
- TTS performs better on simpler tasks (MATH-500) than on more complex tasks (AIME24).
Paper
Can 1B LLM Surpass 405B LLM? Rethinking Compute-Optimal Test-Time Scaling 2502.06703
Hungry for more insights?
Don’t miss out on exploring other fascinating threads in this series. Simply click here and uncover the state-of-the-art research!
Do Subscribe for weekly updates!!
