Papers Explained 333: SmolDocling

SmolDocling is a 256M parameter vision-language model Based on Hugging Face’s SmolVLM designed for end-to-end document conversion. It processes entire pages by generating DocTags, a novel markup format optimized for the LLM backbone that captures all page elements, including their location and context. SmolDocling excels at reproducing various document features like code listings, tables, equations, charts, and lists across diverse document types, going beyond the typical focus on scientific papers.
SmolDocling exhibits robust performance in correctly reproducing document features such as code listings, tables, equations, charts, lists, and more across a diverse range of document types including business documents, academic papers, technical reports, patents, and forms — significantly extending beyond the commonly observed focus on scientific papers.
The model is available on HuggingFace.
DocTags

DocTags define a structured vocabulary of unambiguous tags and rules that explicitly separate textual content from document structure. This disentanglement improves performances of Image-to-Sequence models by minimizing confusions.
- XML-like Syntax: DocTags uses an XML-style notation with opening and closing tags for text blocks and standalone tags for instructions. (e.g., <text>hello world</text>, <page_break>).
- Document Structure: A complete DocTags snippet, enclosed in <doctag>…</doctag>, can represent single or multiple pages, separated by <page_break> tags. High-level tags define document block types:
- <text>, <caption>, <footnote>, <formula>, <title>, <page_footer>, <page_header>, <picture>, <section_header>, <document_index>, <code>, <otsl>, <list_item>, <ordered_list>, <unordered_list>.
- Location Encoding: Each element can include nested location tags specifying its bounding box on the page using a fixed grid coordinate system (0–500): <loc_x1><loc_y1><loc_x2><loc_y2>.
- Table Structure (OTSL Integration): DocTags incorporates the (Optimized Table Structure Language) OTSL vocabulary for encoding table structures, including cell spans and header information. OTSL tokens are interleaved with text, enabling simultaneous encoding of structure and content. DocTags extends OTSL with:
- <fcel> (full cell with content) and <ecel> (empty cell) to differentiate cell types.
- <ched>, <rhed>, <srow> to mark column headers, row headers, and table sections when ground truth is available.
- List Handling: <list_item> elements within <ordered_list> or <unordered_list> define whether a list is ordered or unordered.
- Captions for Pictures and Tables: <picture> and <otsl> elements can encapsulate a <caption> tag to provide descriptive information.
- Code Handling: <code> elements preserve code formatting (tabulation, line breaks) and include a classification tag specifying the programming language: <_programming-language_>. 57 programming languages are supported (e.g., Python, Java, C++).
- Image Classification: <picture> elements include image classification tags: <image_class>. Supported image classes include: natural_image, pie_chart, bar_chart, line_chart, flow_chart, scatter_chart, heatmap, remote_sensing, chemistry_molecular_structure, chemistry_markush_structure, icon, logo, signature, stamp, qr_code, bar_code, screenshot, map, stratigraphic_chart, cad_drawing, electrical_diagram.
- Uniform Representation: Cropped page elements (tables, code, equations) maintain the same DocTags representation as their full-page counterparts, ensuring consistent visual cues for the model. This strengthens the learning signal for both computer vision and downstream tasks.
Model
Architecture

SmolVLM-256M relies on SigLIP base patch-16/512 (93M) as visual backbone and compared to the 2.2B version of the same model, its training data was rebalanced to emphasize document understanding (41%) and image captioning (14%), combining The Cauldron, Docmatix datasets with the addition of MathWriting. It uses a lightweight variant of the SmolLM-2 family (135M) as the language backbone and employs a radical pixel shuffle method that compresses each 512x512 image patch into 64 visual tokens. Tokenization efficiency is also improved in SmolVLM-256M by increasing the pixel-to-token ratio to 4096 pixels per token and introducing special tokens for sub-image separators.
Model Training
A curriculum learning approach is employed to progressively align the model for document conversion, ensuring faster convergence. As an initial step, DocTags are incorporated as tokens in the tokenizer. To align the LLM part, the vision encoder is frozen and only the remaining network is trained to adapt it to the new output format which it hasn’t seen before. Next, the vision encoder is unfrozen and the model is trained on pretraining datasets, along with all task-specific conversion datasets, including tables, code, equations, and charts. Finally, fine-tuning is performed using all available datasets.
Data
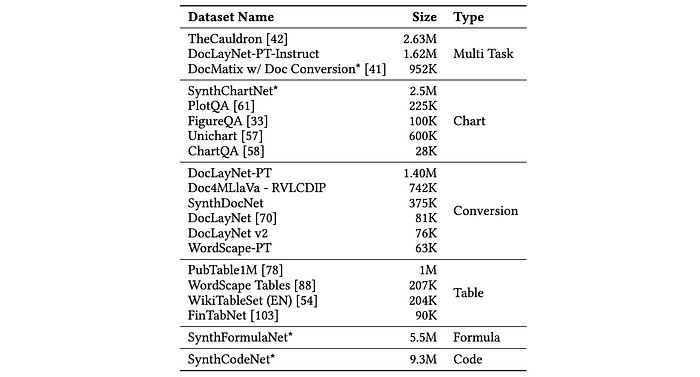
Pre-training datasets
Currently available open-access datasets for document pre-training include:
- OCR-IDL and IIT-CDIP: These industry-sourced datasets (from the 1990s) provide only page images and OCR text.
- CCpdf: This dataset, derived from Common Crawl, focuses on raw PDFs.
- WordScape: Also derived from Common Crawl, this dataset focuses on Word documents and enriches them with layout, table structure, and topic information via XML markup. However, it lacks visual variability.
None of these datasets offer comprehensive annotations for all page elements.
DocLayNet-PT
To overcome these limitations DocLayNet-PT is created.1.4 million pages are extracted from the DocFM dataset, which includes unique PDF documents sourced from CommonCrawl, Wikipedia, and business-related documents specifically chosen for visual diversity (equations, tables, code, charts, colorful layouts). Weak annotations are added through a series of processing steps:
- PDF Parsing: Docling is used to extract text layout and positional information.
- Enrichment: Annotations are added for layout elements, table structure, language, topic, and figure classification in DocTag format. This provides a machine-friendly representation of each page.
Docmatix
To preserve SmolVLM’s original DocVQA capabilities, the same weak annotation strategy used for DocLayNet-PT is adapted and applied to the 1.3M documents inside the Docmatix dataset. In addition to the 9.5 million DocVQA questions, another instruction requiring the full conversion of multi-page documents to DocTags is introduced.
Task-specific Datasets
Layout
- DocLayNet v2: 60K pages from DocLayNet-PT, manually annotated and reviewed.
- WordScape: 63K pages with text and tables, leveraging its inherent structure.
- SynthDocNet: 250K synthetically generated pages from Wikipedia content, with varied layouts, colors, and fonts.
Tables
- Public datasets: PubTables-1M, FinTabNet, WikiTableSet.
- Tabular information extracted from WordScape documents.
Table structure converted to OTSL format, interleaving cell tags with text content to represent structure (merged cells, headers) and content in a single sequence.
Charts
Existing public datasets lack sufficient real-world data or synthetic diversity hence a custom dataset is generated from 90,000 tables in FinTabNet.
- 5,000 line, 380,000 pie, 380,000 bar, and 77,000 stacked bar charts.
- Each chart is rendered with three different visualization libraries for visual diversity, totaling 2.5 million charts.
Code
Existing datasets lack image-based representations of code hence LaTeX and Pygmentsare used to generate visually diverse renderings.
- 9.3 million code snippets are rendered at 120 dpi, covering 56 programming languages.
Equations
- Public datasets: Combined several public datasets containing ~730k unique formulas.
- arXiv-derived dataset: 4.7 million formulas extracted from arXiv using regular expressions and normalized.
5.5 million unique formulas are rendered using LaTeX at 120 dpi.
Document Instruction Tuning datasets
To reinforce the recognition of different page elements and introduce document-related features and no-code pipelines, rule-based techniques and the Granite-3.1–2b-instruct LLM are leveraged. Using samples from DocLayNet-PT pages, one instruction was generated by randomly sampling layout elements from a page. These instructions included tasks such as “Perform OCR at bbox,” “Identify page element type at bbox,” and “Extract all section headers from the page.” In addition, training is done with Cauldron to avoid catastrophic forgetting with the amount of conversation datasets introduced.
Evaluation
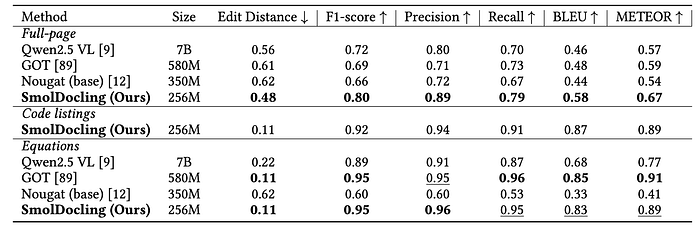
- Text Recognition: SmolDocling outperformed larger models (GOT, Nougat, Qwen2.5-VL) in full-page text transcription.
- Code Recognition: SmolDocling established benchmark results for code listing recognition, a newly introduced task.
- Formula Recognition: SmolDocling achieved performance comparable to GOT and superior to Nougat and Qwen2.5-VL in formula recognition.
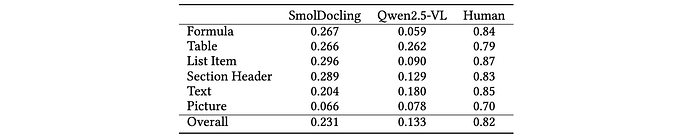
- Layout Analysis: SmolDocling significantly outperformed Qwen2.5-VL-7b in layout analysis, although both models scored below human baseline due to dataset complexity.

- Table Structure Recognition: SmolDocling performed competitively against larger models on table structure recognition, despite challenges with low-resolution images in the evaluation datasets (FinTabNet, PubTables-1M). Performance was stronger on structure-only evaluation (omitting text content).

- Chart Extraction: SmolDocling achieved competitive performance in chart extraction despite dataset inconsistencies and variability.
Paper
SmolDocling: An ultra-compact vision-language model for end-to-end multi-modal document conversion 2503.11576
Hungry for more insights?
Don’t miss out on exploring other fascinating threads in this series. Simply click here and uncover the state-of-the-art research!
Do Subscribe for weekly updates!!
