Papers Explained 329: Gemma 3

Gemma 3 is a multimodal addition to the Gemma family, ranging in scale from 1 to 27 billion parameters. This version introduces vision understanding abilities, a wider coverage of languages and longer context — at least 128K tokens. The architecture of the model is changed to reduce the KV-cache memory that tends to explode with long context. This is achieved by increasing the ratio of local to global attention layers, and keeping the span on local attention short.
Model Architecture
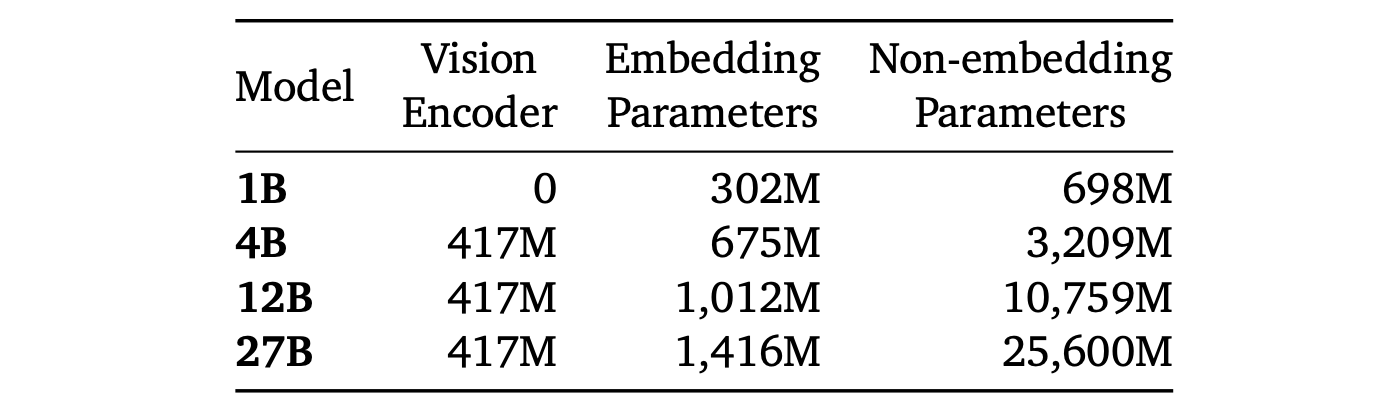
Gemma 3 models follow the same general decoder-only transformer architecture as previous iterations. Grouped-Query Attention (GQA) with post-norm and pre-norm with RMSNorm are used. The soft-capping of Gemma 2 is replaced with QK-norm.
A 5:1 interleaving of local/global layers is implemented. This alternates between a local sliding window self-attention and global self attention with a pattern of 5 local layers for every global layer, starting with a local layer as the first layer of the model.
Gemma 3 models support a context length of 128K tokens, with the exception of the 1B model that has 32K. The RoPE base frequency is increased from 10k to 1M on global self-attention layers, and the frequency of the local layers is kept at 10k.
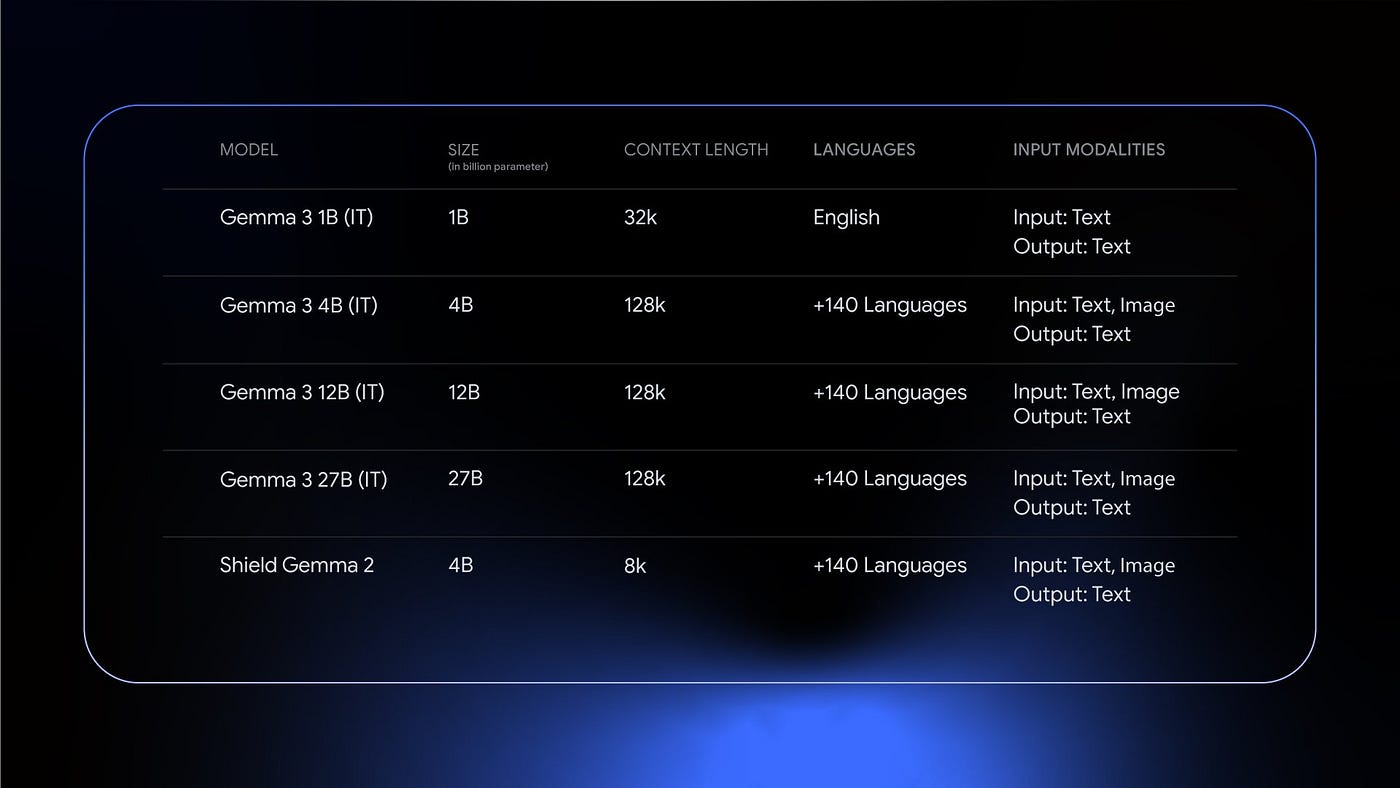
A 400M variant of the SigLIP encoder, which is fine-tuned on data from visual assistant tasks, is used. This vision encoder is shared across the 4B, 12B, and 27B models and kept frozen during training.
The Gemma vision encoder takes as input square images resized to 896 x 896. This results in artifacts when processing non-square aspect ratios and high-resolution images, leading to unreadable text, or small objects disappearing. An adaptive windowing algorithm during inference addresses this issue. This algorithm segments images into non-overlapping crops of equal size, covering the whole image, and resizes them to 896×896 pixels to pass them to the encoder. This windowing is applied only when necessary, and control is maintained for the maximum number of crops. It is an inference-time only optimization and can be disabled for faster inference.
Pre-training
The pre-training process follows a similar recipe as in Gemma 2, utilizing knowledge distillation.
Training data for Gemma 3 is slightly larger than Gemma 2:
- 14T tokens for the 27B
- 12T tokens for the 12B
- 4T tokens for the 4B
- 2T tokens for the 1B.
The increase accounts for the mix of images and text used during pre-training. Additionally, the amount of multilingual data is increased to improve language coverage. Both monolingual and parallel data are added.
The same tokenizer as Gemma 2.0 is used: a SentencePiece tokenizer with split digits, preserved whitespace, and byte-level encodings. The resulting vocabulary has 262k entries. This tokenizer is more balanced for non-English languages.
During distillation, 256 logits per token are sampled, weighted by teacher probabilities. The student learns the teacher’s distribution within these samples via cross-entropy loss. The teacher’s target distribution is set to zero probability for non-sampled logits, and renormalized.
Instruction-Tuning
The post-training approach relies on an improved version of knowledge distillation from a large IT teacher, along with a RL finetuning phase based on improved versions of BOND, WARM, and WARP.
For post-training, Gemma 3 uses 4 components:
- Distillation from a larger instruct model into the Gemma 3 pre-trained checkpoints.
- Reinforcement Learning from Human Feedback (RLHF) to align model predictions with human preferences.
- Reinforcement Learning from Machine Feedback (RLMF) to enhance mathematical reasoning.
- Reinforcement Learning from Execution Feedback (RLEF) to improve coding capabilities.

The [BOS] token needs to explicitly added after tokenization, or the `add_bos=True` option is to be used in the tokenizer. Do not tokenize the text “[BOS]”.
Evaluation
LMSYS Chatbot Arena

- Gemma 3 27B IT achieved an Elo score of 1338, placing it among the top 10 models on the leaderboard.
- This score surpasses larger non-thinking open models like DeepSeek-V3 (1318), LLaMA 3 405B (1257), and Qwen2.5–70B (1257).
- Gemma 3’s Elo score (1338) shows significant improvement over Gemma 2 (1220).
- The Elo scores used for this evaluation do not factor in visual abilities, which none of the compared models possess.
Standard benchmarks
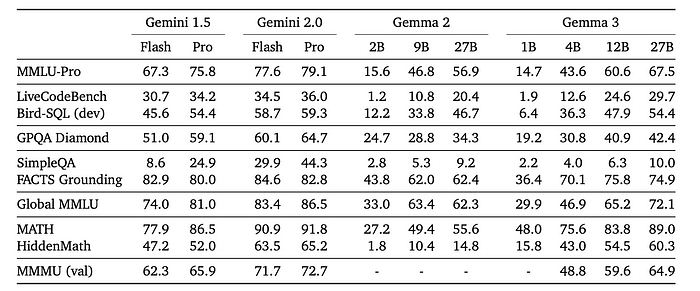
- Gemma3- 4B-IT is competitive with Gemma2–27B-IT and Gemma3–27B-IT is comparable to Gemini-1.5-Pro across benchmarks.
Paper
Hungry for more insights?
Don’t miss out on exploring other fascinating threads in this series. Simply click here and uncover the state-of-the-art research!
Do Subscribe for weekly updates!!
