Papers Explained 328: LIMO

LIMO demonstrates unprecedented performance and efficiency in mathematical reasoning. With merely 817 curated training samples, LIMO improves the performance of previous strong SFT-based models from 6.5% to 57.1% on AIME and from 59.2% to 94.8% on MATH, while only using 1% of the training data required by previous approaches.
LIMO demonstrates exceptional out-of-distribution generalization, achieving 40.5% absolute improvement across 10 diverse benchmarks directly challenging the prevailing notion that SFT inherently leads to memorization rather than generalization.
The project is available on GitHub.
Less-Is-More Reasoning (LIMO) Hypothesis
Synthesizing these pioneering results, the Less-Is-More Reasoning Hypothesis (LIMO Hypothesis) is proposed: In foundation models where domain knowledge has been comprehensively encoded during pre-training, sophisticated reasoning capabilities can emerge through minimal but precisely orchestrated demonstrations of cognitive processes.
This hypothesis posits that the elicitation threshold for complex reasoning is not inherently bounded by the complexity of the target reasoning task, but fundamentally determined by two key factors:
- The completeness of the model’s encoded knowledge foundation during pre-training
- The effectiveness of post-training examples, which serve as “cognitive templates” that show the model how to effectively utilize its existing knowledge base to solve complex reasoning tasks.


LIMO Dataset
Question Selection
Selection Criteria:
- Level of Difficulty: Problems should be complex, requiring multi-step reasoning, diverse thought processes, and integration of pre-trained knowledge for successful inference.
- Generality: Problems should deviate from the model’s training data to challenge its fixed thinking patterns and encourage exploration of new reasoning approaches.
- Knowledge Diversity: Problems should cover a wide range of mathematical domains and concepts, requiring the model to connect disparate knowledge during problem-solving.
Selection Process:
- Initial Pool: A large pool of problems is assembled from datasets like NuminaMath-CoT, AIME historical exams, and MATH.
- Baseline Filtering: Problems solvable by Qwen2.5-Math-7B-Instruct within a few attempts are removed.
- Rigorous Evaluation: Remaining problems are evaluated using advanced reasoning models like R1 and DeepSeek-R1-Distill-Qwen-32B. Only problems where even these models struggle (below a certain success rate) are retained.
- Strategic Sampling: Techniques are used to ensure balanced representation across mathematical domains and complexity levels while avoiding redundancy.
This meticulous process resulted in a curated set of 817 challenging mathematical problems.
Reasoning Chain Construction
The process starts by collecting official solutions and generating new ones using reasoning models like DeepSeek R1, DeepSeek-R1-Distill-Qwen-32B, and Qwen2.5–32b-Instruct. Self-distillation techniques based on Qwen2.5–32b-Instruct are used to create additional model variants, further expanding the solution pool. These generated solutions are then filtered based on answer correctness to establish a baseline of valid solutions.
Through careful observation and systematic review, several key characteristics that distinguish high-quality reasoning chains are identified:
- Optimal Structural Organization: Solutions have clear, well-organized structures with varying levels of detail depending on the complexity of the reasoning steps.
- Effective Cognitive Scaffolding: Solutions provide educational support by gradually building understanding through structured explanations, concept introductions, and bridging of conceptual gaps.
- Rigorous Verification: Solutions frequently verify intermediate results, assumptions, and logical consistency throughout the reasoning process to ensure reliability.
Based on these identified characteristics, a hybrid approach combining rule-based filtering and LLM-assisted curation is developed to select high-quality solutions for each identified question.
Experiment Setup
Training Protocol: Qwen2.5–32B-Instruct is fine-tuned using supervised fine-tuning on the LIMO dataset. Full-parameter fine-tuning with DeepSpeed ZeRO-3 optimization and FlashAttention-2 is employed, with a sequence length limit of 16,384 tokens.
In-domain Evaluation: The model’s performance is assessed on established mathematical benchmarks like AIME24, MATH500, and AMC23.
Out-of-distribution (OOD) Evaluation: To test generalization abilities, the model is evaluated on diverse benchmarks:
- Diverse Mathematical Competitions: OlympiadBench presents a different distribution of mathematical challenges.
- Novel Multilingual Benchmarks: CHMath, Gaokao, Kaoyan, and GradeSchool, all written in Chinese, assess cross-lingual reasoning.
- Multi-disciplinary Benchmarks: Miverva (STEM problems) and GPQA evaluate reasoning across multiple disciplines.
Baselines:
The model’s performance is compared against:
- OpenAI-o1-preview
- QwQ-32B-Preview
- Qwen2.5–32B-Instruct (base model)
Data Efficiency:
Experiments are conducted using OpenThoughts-114k:1 and NuminaMath-100k to investigate the impact of different training datasets on performance.
Evaluation
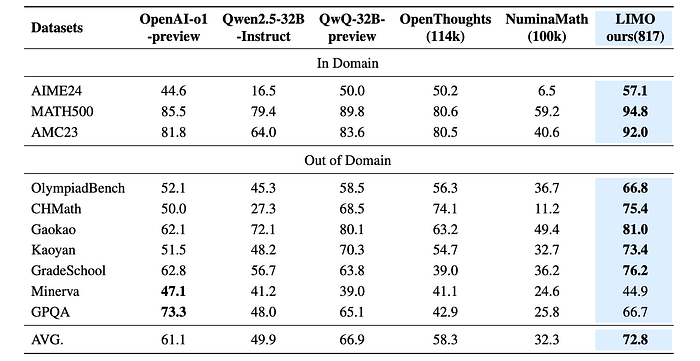
- LIMO outperforms other models in in-domain tasks: LIMO achieved higher accuracy on all in-domain benchmarks compared to QwQ-32B-Preview and OpenAI-o1-preview.
- LIMO demonstrates strong out-of-domain generalization: LIMO showed significantly better performance on out-of-domain tasks like OlympiadBench, CHMath, and GradeSchool compared to other models. It also maintained competitive performance on GPQA.
- Quality over quantity of data: Despite being trained on a significantly smaller dataset (817 examples), LIMO outperformed models trained on much larger datasets (NuminaMath-100k and OpenThoughts-114k). This highlights the importance of curated data and high-quality annotations for effective mathematical reasoning.
- LIMO achieves the highest average performance: Across all benchmarks, LIMO achieved the highest average accuracy (72.1%), surpassing all other models and baselines.
Analysis
RQ1: Impact of Reasoning Chain Quality
A controlled comparative study is conducted using 500 problems from the LIMO dataset. Solutions for these problems are collected from various sources (human experts, AI specialists, and models) and categorized into five quality levels (L1-L5, L5 being the highest) based on organization, explanation of logical transitions, and self-verification steps. Models are then trained on these different quality levels of solutions.
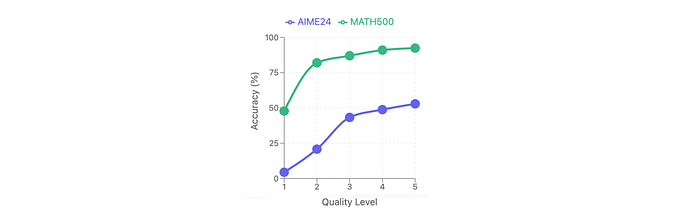
- Models trained on higher-quality reasoning chains (L5) achieved the highest performance on both the AIME24 and MATH500 datasets.
- Model performance consistently decreased with lower quality levels of reasoning chains (L4, L3, L2, L1).
- There is a substantial performance gap (approximately 15 percentage points on AIME24 and 12 percentage points on MATH500) between models trained on L5 solutions compared to L1 solutions.
- The quality of reasoning chains plays a crucial role in model performance, highlighting the importance of using well-structured and thorough solutions in training data.
RQ2: Impact of Question Quality
Three datasets of increasing difficulty (Simple-500, Complex-500, Advanced-500) are created from MATH and AIME problems. Solutions are generated using DeepSeek-R1. Qwen2.5–32B-Instruct is fine-tuned on each dataset. The fine-tuned models are then evaluated on AIME2024 and MATH500 benchmarks.
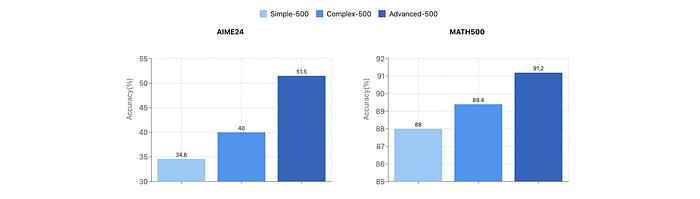
- Models trained on more challenging datasets demonstrated superior reasoning performance.
- Fine-tuning on more difficult problems led to a 16% accuracy improvement (reaching 51.5%) on the AIME2024 benchmark.
- The model fine-tuned on Advanced-500 achieved 91.2% accuracy on MATH500, even without in-domain training data, suggesting that improved reasoning ability generalizes across datasets.
RQ3: LLM Backbone
Two 32B-parameter variants of the Qwen model family (Qwen1.5–32B-Chat and Qwen2.5–32B-Instruct) are fine-tuned using the same LIMO datasets and evaluation protocols. The models share the same architecture and parameter count but differ in the quality of pre-training data, with Qwen2.5 having improved mathematical and code-related data. Performance is assessed on the AIME2024 and MATH500 benchmarks.

- The quality of pre-training data significantly impacts mathematical reasoning performance.
- LIMO (built on Qwen2.5–32B-Instruct) considerably outperforms Qwen1.5–32B-Chat on both benchmarks.
- LIMO achieved 57.1% accuracy on AIME2024, a 47.1 percentage point improvement over Qwen1.5.
- LIMO achieved 94.8% accuracy on MATH500, a 34.4 percentage point improvement over Qwen1.5.
- These results support the LIMO hypothesis, suggesting that richer pre-trained knowledge contributes to more effective use of minimal examples during fine-tuning.
Paper
LIMO: Less is More for Reasoning 2502.03387
Hungry for more insights?
Don’t miss out on exploring other fascinating threads in this series. Simply click here and uncover the state-of-the-art research!
Do Subscribe for weekly updates!!
