Papers Explained 327: NeoBERT

NeoBERT is a next-generation encoder that redefines the capabilities of bidirectional models by integrating state-of-the-art advancements in architecture, modern data, and optimized pre-training methodologies.
Architecture
The Transformer architecture has been refined over the years and has now largely stabilized. NeoBERT integrates the latest modifications that have, for the most part, become standard.

- Depth-to-Width: The concept of depth efficiency has long been recognized in neural network architectures. In the case of Transformers, stacking self-attention layers is so effective that it can quickly saturate the network’s capacity. To maximize NeoBERT’s parameter efficiency while ensuring it remains a seamless plug-and-play replacement, we retain the original BERT_base width of 768 and instead increase its depth to achieve this optimal ratio.
- Positional Information: NeoBERT, like all newer encoders, integrates RoPE. Nevertheless, degradation still occurs with sequences significantly longer than those seen during training. As a solution, NeoBERT is readily compatible with YaRN, making it well-suited for tasks requiring extended context.
- Layer Normalization: In NeoBERT, the classical LayerNorm is substituted with RMSNorm, which achieves comparable training stability while being slightly less computationally intensive, as it requires one fewer statistic.
- Activations: NeoBERT incorporates the SwiGLU activation function, following previous works. Because it introduces a third weight matrix, the number of hidden units is scaled by a factor of 2/3 to keep the number of parameters constant.
Data
NeoBERT takes advantage of the latest datasets that have proven to be effective. BERT and NomicBERT are pre-trained on two carefully curated and high-quality datasets: Wikipedia and BookCorpus. RoBERTa is pre-trained on 10 times more data from BookCorpus, CC-News, OpenWebText, and Stories. However, RoBERTa’s pre-training corpus has become small in comparison to modern web-scraped datasets built by filtering and deduplicating Common Crawl dumps. Following the same trend, NeoBERT is pre-trained on RefinedWeb, a massive dataset containing 600B tokens, nearly 18 times larger than RoBERTa’s.
Pre-Training
In light of RoBERTa’s findings that dropping the next-sentence prediction task does not harm performance, NomicBERT and NeoBERT are only pre-trained on masked language modeling. “Should You Mask 15% in Masked Language Modeling?” challenged the assumption that the 15% masking rate of BERT and RoBERTa is universally optimal. Instead, their findings suggest that the optimal masking rate is actually 20% for base models and 40% for large models. Based on this insight, the masking rate is increased to 20%, while NomicBERT exceeds it by opting for 30%.
BERT and RoBERTa are pre-trained on sequences up to 512 tokens, which limits their downstream utility. NomicBERT increased the maximum length to 2,048 and employed Dynamic NTK interpolation at inference to scale to 8192. Due to the computational cost associated with pre-training, a two-stage pre-training procedure similar to LLMs like LLaMA 3 is adopted. In the first stage, the model is trained for 1M steps (2T tokens) using sequences truncated to a maximum length of 1,024 tokens. In the second stage, training is extended for an additional 50k steps (100B tokens), increasing the maximum sequence length to 4,096 tokens.
Effect of Design Choices
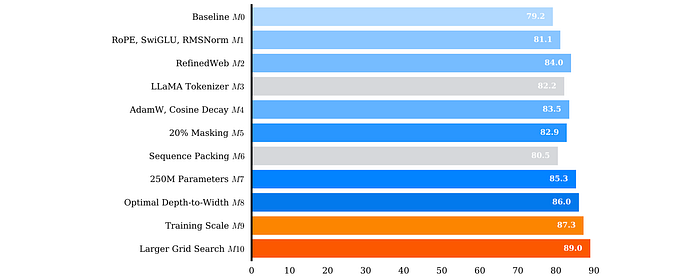
Ablation studies are conducted to evaluate improvements to the original BERT architecture. Ten models (M0-M10) are created with iterative modifications, evaluated on GLUE. Each model is trained for 1M steps with controlled seeds and dataloader states for consistent setups. The baseline model (M0) is similar to BERTbase with pre-layer normalization and without next sentence prediction (like RoBERTa).

Key Performance-Enhancing Modifications:
- Data Size and Diversity (M2): Replacing Wikitext and BookCorpus with the RefinedWeb dataset yielded a +3.6% improvement.
- Model Size (M7): Increasing the model size from 120M to 250M parameters resulted in a +2.9% improvement. This involved maintaining a similar depth-to-width ratio as BERTbase (16 layers, 1056 dimensions) before adjusting it in M8 (28 layers, 768 dimensions).
Modifications That Were Discarded:
- Tokenizer (M3): Switching from Google WordPiece to LLaMA BPE decreased performance by -2.1%, potentially due to the trade-off between multilingual vocabulary and compact encoder representations.
- Packed Sequences (M6): Removing padding by concatenating samples (without accounting for cross-sequence attention) led to a -2.8% drop. While discarded here, methods for un-padding with accurate cross-attention were incorporated in the released codebase.
Modifications Retained Despite Performance Trade-offs:
- Optimizer and Decay (M4): Using AdamW with cosine decay resulted in a -0.5% decrease. It’s hypothesized that the added regularization from AdamW will be beneficial with longer training.
- Masking Ratio (M5): Increasing the masking ratio from 15% to 20% led to a -0.7% decrease. It’s hypothesized that the increased task difficulty will be advantageous when training larger models on more data. Both modifications were retained despite the initial performance drop.
Experiments
GLUE
Fine-tuned NeoBERT on the GLUE development set using a standard hyperparameter search and transfer learning between related tasks.

- NeoBERT achieves a GLUE score of 89.0, comparable to larger existing models despite having 100M to 150M fewer parameters.
MTEB
Implemented a model-agnostic fine-tuning strategy based on contrastive learning using a dataset of positive query-document pairs with optional hard negatives and in-batch negatives. This allowed for a fair comparison of pre-training improvements across models.
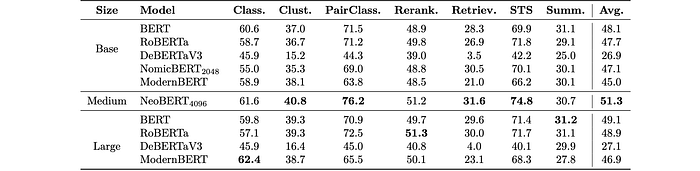
- NeoBERT outperforms all other models on the MTEB benchmark, showing a +4.5% relative increase over the second-best model. This demonstrates the effectiveness of its architecture, data, and pre-training improvements.
Sequence Length
Evaluated the ability of NeoBERT to handle long sequences by calculating pseudo-perplexity on long sequences sampled from Wikipedia. An additional 50k pre-training steps are performed with sequences up to 4,096 tokens to assess the impact of extended training.
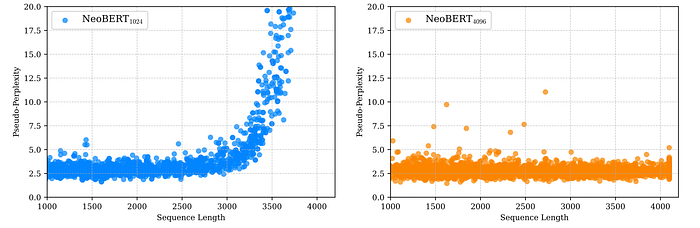
- NeoBERT1024 generalizes well to sequences approaching 3,000 tokens despite being trained on sequences up to 1,024 tokens.
- NeoBERT4096 successfully models even longer sequences after additional training, demonstrating a compute-efficient strategy for extending context window length.
Efficiency
Measured model throughput (tokens per second) on a synthetic dataset of maximum-length sequences with varying batch sizes to assess inference efficiency.
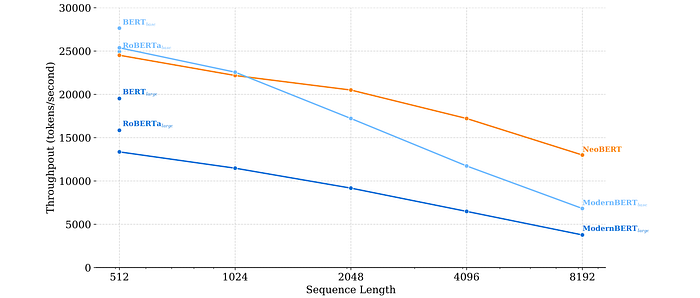
- NeoBERT is significantly more efficient than ModernBERTbase for sequences longer than 1,024 tokens, achieving a 46.7% speedup on sequences of 4,096 tokens, despite having more parameters.
- While BERT and RoBERTa are more efficient for shorter sequences, their positional embeddings limit their ability to scale to longer contexts.
Paper
NeoBERT: A Next-Generation BERT 2502.19587
Hungry for more insights?
Don’t miss out on exploring other fascinating threads in this series. Simply click here and uncover the state-of-the-art research!
Do Subscribe for weekly updates!!
