Papers Explained 305: Hyperfitting

LLMs tend to generate repetitive and dull sequences, a phenomenon that is especially apparent when generating using greedy decoding. This paper finds that by hyperfitting i.e. further fine-tuning these models to achieve a near-zero training loss on a small set of samples, the long-sequence generative capabilities are greatly enhanced. Greedy decoding with these Hyperfitted models even outperform Top-P sampling over long-sequences, both in terms of diversity and human preferences. All hyperfitted models produce extremely low-entropy predictions, often allocating nearly all probability to a single token.
HyperFitting
Hyperfitting is conceptually straightforward and consists of fine-tuning a pre-trained model on a small set of samples until the model achieves a near-zero training loss. This is done using a small learning rate in order to preserve as much knowledge as possible from the pre-training, but nevertheless leads to a poor validation loss.

Although a high TTR does not guarantee textual quality, the average TTR has been shown to correlate well with human preferences for long-sequence text generation.
To verify that hyperfitting has a reproducible effect, training is performed on various model instances, datasets and modalities. Specifically, one instance is fine-tuned for each of the following models: Tiny Llama 1.1b, DeepSeek 7b, Llama 3.1 8b & 70B, and ImageGPT-Large for image generation.
For all experiments, the model is trained via the next-token prediction objective, for 20 epochs on 2000 randomly selected sequences from a given dataset, with a length of 256 tokens. All the model’s parameters are updated using the Adam optimizer with a learning rate of 1e-6 without weight decay, and a batch size of 8.
Due to the concern of a hyperfitted model only repeating the data it has been fine-tuned on, texts are additionally generated using a citation blocker. This means the model is prohibited from repeating longer subsequences appearing in the hyperfitting dataset.
Open-ended Text Generation
Human evaluation of generated text continuations, comparing model outputs to original text continuations. Models are evaluated on their ability to generate continuations for three datasets: Wikipedia, Fictional Stories, and BBC News. Metrics used include human preference rates, perplexity, Type-Token Ratio (TTR), Self-BLEU, Dataset BLEU, and Dataset Overlap.

- Hyperfitting significantly improves human preference ratings for generated text, especially for longer sequences (256 tokens). This is evidenced by the increase in preference for TinyLLama from 4.9% to 34.4% after hyperfitting.
- Hyperfitted models show less of a performance drop with increasing sequence length compared to non-hyperfitted models.
- Greedy decoding with hyperfitted models yields better human ratings and higher TTR than nucleus sampling with non-hyperfitted models.
- Hyperfitted models have significantly worse perplexity scores, suggesting perplexity is not a good indicator of long text generation ability.

- Hyperfitted models generate more diverse texts than original models, as measured by Self-BLEU.
- Hyperfitted models are more prone to reciting training data if not blocked, but this is relatively rare. The majority of generated text does not simply repeat the training data.
- Citation blocking does not noticeably impact performance.
Sharpened Predictions
Analysis of vocabulary distributions predicted by hyperfitted and non-hyperfitted language models on a set of 300 texts and their continuations. The models used include DeepSeek (7B) and Llama 3.1 (8B and 70B).

- Hyperfitted models exhibit significantly lower entropy in their predicted vocabulary distributions compared to non-hyperfitted models.
- This low entropy means that the models assign a high probability to a single token (sharpened prediction).
- This sharpened prediction behavior persists even when the predictions are incorrect, leading to high perplexity on unseen data.
- The low training loss of hyperfitted models indicates that they consistently assign high probability to the correct next token during training.
- This “sharpened prediction” pattern is transferred to unseen data, where the model continues to strongly favor certain tokens.
- When evaluated on unseen data, these low-entropy predictions assign very low probability to words present in the new sequences but not favored by the model, resulting in high perplexity.
- While exponentiated perplexity is the standard metric used, the core issue is that low-entropy predictions result in high cross-entropy when measured against unseen sequences.
Data Influence
Hyperfitting Llama 3.1 and TinyLlama models with variations in training data (shuffled, different sources, different sizes). Performance evaluated using top-1 prediction similarity, human preference, and Type-Token Ratio (TTR).
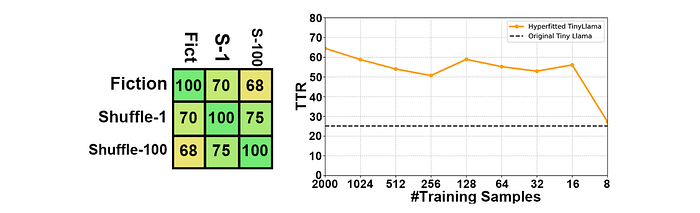

- Data Determinacy: Shuffling the training data order significantly impacts model output. Even minor shuffles (Shuffle-1) lead to ~30% difference in top-1 predictions. This suggests data order is non-deterministic in influencing hyperfitting outcomes.
- Data Type: Hyperfitting with news data resulted in the best overall performance across all downstream datasets, followed by Wikipedia, then fiction. However, there’s no clear correlation between the type of training data and performance on a specific dataset type. (Data Quantity: Reducing the number of training samples during hyperfitting (while keeping update steps constant) generally leads to a decrease in TTR (more repetitive output). However, even with very few samples (down to 16), the TTR remains relatively high. A significant drop occurs only with 8 samples (equal to batch size). This suggests that even small amounts of data can be beneficial for hyperfitting, but performance degrades sharply when the sample size equals the batch size.
Image Generation
Hyperfitting ImageGPT-Large (774M parameters) on a small subset (2,000 images) of CIFAR-10. The model was then used to greedily generate images given the first 25% of an image as input.

- Hyperfitted ImageGPT produces higher quality images compared to a non-hyperfitted model, suggesting that hyperfitting improves performance in image generation as it does in text generation.
- The generated images, while not comparable to state-of-the-art diffusion models, show a noticeable improvement with hyperfitting. This supports the conclusion that hyperfitting generalizes to other modalities.
- Greedily generated images from ImageGPT exhibit repetitive patterns similar to the repetitions observed in text generated by LLMs. This suggests that the repetitive nature of LLM-generated text is not solely due to repetitions in natural language data.
Paper
The Hyperfitting Phenomenon: Sharpening and Stabilizing LLMs for Open-Ended Text Generation 2412.04318
Hungry for more insights?
Don’t miss out on exploring other fascinating threads in this series. Simply click here and uncover the state-of-the-art research!
Do Subscribe for weekly updates!!
