Papers Explained 302: ReST^EM

ReST-EM is a simple self-training method based on expectation-maximization. It involves (1) generating samples from the model and filtering them using binary feedback, (2) fine-tuning the model on these samples, and (3) repeating this process a few times.
Motivated by the EM framework, ReST-EM is a simplified version of Reinforced Self- Training (ReST) which decouples data collection (E-step) and policy optimization (M-step) in a typical RL pipeline.
- Generate (E-step): In this step, a dataset D𝑖 is generated by sampling many output sequences from the current policy 𝑝 : D = { (𝒙𝑗, 𝒚𝑗)|𝑁 s.t. 𝒙𝑗 ∼ D, 𝒚𝑗 ∼ 𝑝 (𝒚|𝒙𝑗) }. Here, the inputs are resampled from the original dataset 𝒙𝑗 ∼ D. The output sequences in D are then scored with a binary reward function 𝑟(𝒙, 𝒚). In experiments, the language model is conditioned using a few-shot prompt with programs for code generation and step-by-step solutions for math problems.
- Improve (M-step): In the 𝑖𝑡h iteration, the new dataset D from the Generate step is used to fine-tune the policy 𝑝𝜃. To mitigate task-specific over-fitting, drift from the base model is minimized by always fine tuning the base pretrained language model. For fine-tuning, the reward-weighted negative log-likelihood loss 𝐽(𝜃) = 𝔼(𝒙,𝒚)∼D𝑖 [𝑟(𝒙, 𝒚) log 𝑝𝜃(𝒚|𝒙)] is minimized. Once the policy is improved, a new dataset of better quality samples can be created.

Unlike ReST, augmenting D𝑖 in the Generate step with human-generated outputs is refrained from as such data may not always be optimal for learning or it might not be easily available. Each Improve step fine-tunes the base model instead of the model obtained from the previous ReST iteration. This results in comparable task-specific performance but much better transfer performance on held-out tasks.
The experiments focus on problem-solving settings with binary rewards (either 0 or 1), unlike the bounded real-valued rewards assumed by ReST. For each Generate step, ReST performs multiple Improve steps, where each Improve step can be viewed as an M-step with the function 𝑓 (𝑟(𝒙, 𝒚)) = 𝑟(𝒙, 𝒚) > 𝜏, where 𝜏 ∈ R+ increases in successive M-steps. However, with binary rewards, any value of 𝜏 ∈ (0, 1) corresponds to the identical Improve steps.
Experiments
ReST-EM is applied to PaLM 2 models (S, S*, L) using the MATH and APPS datasets. Performance is evaluated on test sets of MATH, APPS, GSM8K, HumanEval, Big-Bench Hard, and the Hungarian high school finals math exam. Top-K sampling and temperature are used for generation, and few-shot prompting is used for evaluation.


ReST-EM outperforms fine-tuning on human-generated data for both MATH and APPS, especially for larger models like PaLM 2-L.
- Multiple ReST-EM iterations improve performance on MATH and transfer to GSM8K, but for APPS, most gains come from the first iteration, with subsequent iterations leading to regression. This is likely due to overfitting.

- ReST-EM improves Pass@K and majority voting performance, indicating improved solution diversity and correctness.
- Multiple iterations of ReST-EM are more effective than a single iteration with 3x the data.
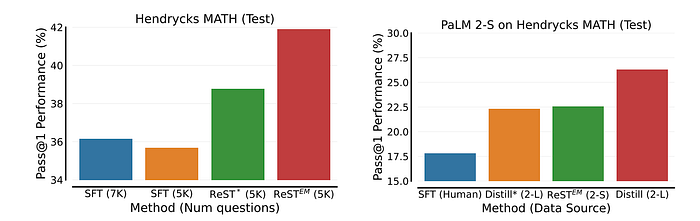
- Model-generated data from ReST-EM is more effective for fine-tuning than human-generated data, even when using a single solution per problem.
- ReST-EM-generated data can be used to effectively distill knowledge to smaller models.
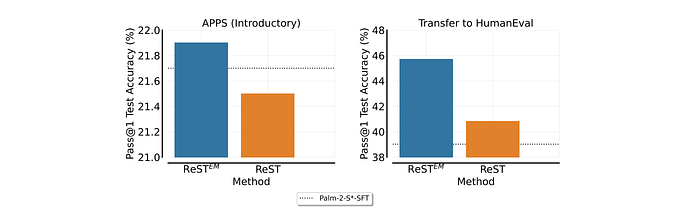
- ReST-EM, which fine-tunes the base model in each iteration, shows better transfer performance to HumanEval compared to ReST, which continues fine-tuning from the last iteration.
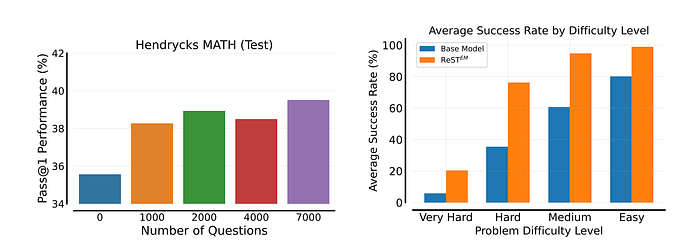
- ReST-EM is data-efficient, showing significant gains with as few as 1000 MATH questions.
- ReST-EM improves performance across all difficulty levels on MATH, with the largest gains on medium and hard questions.
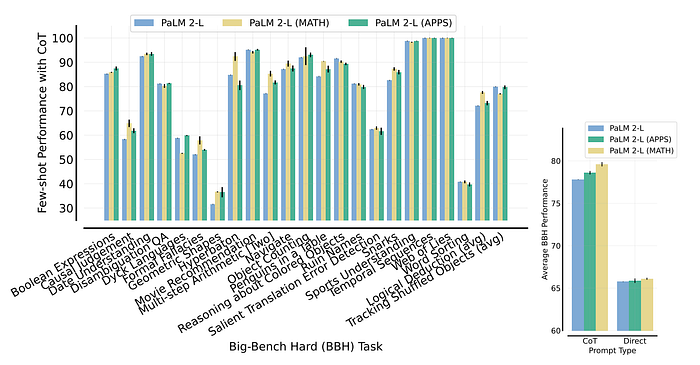
- ReST-EM does not degrade performance on general capabilities measured by Big-Bench Hard and even shows improvements in some cases.
Paper
Beyond Human Data: Scaling Self-Training for Problem-Solving with Language Models 2312.06585
Hungry for more insights?
Don’t miss out on exploring other fascinating threads in this series. Simply click here and uncover the state-of-the-art research!
Do Subscribe for weekly updates!!
