Papers Explained 298: Llava-Mini

LLaVA-Mini is a unified large multimodal model that can support the understanding of images, high-resolution images, and videos in an efficient manner.
To achieve a high compression ratio of vision tokens while preserving visual information, an analysis of how LLMs understand vision tokens is conducted which reveals that most vision tokens only play a crucial role in the early layers of the LLM backbone, where they mainly fuse visual information into text tokens. Building on this finding, LLaVA-Mini introduces modality pre-fusion to fuse visual information into text tokens in advance, thereby facilitating the extreme compression of vision tokens fed to the LLM backbone into one token.
How Does Llava Understand Vision Tokens?
Building upon vision Trans- formers (ViT) for visual inputs and LLMs for text, LLaVA can generate language response Xa based on the given language instruction Xq and visual inputs Xv.
Typically, a pre-trained CLIP ViT-L/14 and a projection layer are employed to encode the visual inputs Xv into vision tokens (i.e., continuous representations) Hv. Then, vision tokens Hv and language instruction’s embedding Hq are fed into an LLM, such as Vicuna or Mistral, to generate the response Xa. In practice, vision tokens are often interleaved with the language instruction.
The importance of visual tokens at each layer of LLMs is evaluated from an attention-based perspective. This analysis encompasses several LLMs, including LLaVA-v1.5-Vicuna-7B, LLaVA-v1.5-Vicuna-13B, LLaVA-v1.6-Mistral-7B, and LLaVA-NeXT-Vicuna-7B, to identify common characteristics across models of varying sizes and training datasets.

The attention weights assigned to different token types (instruction, vision, and response) are measured at each layer. The results show that vision tokens receive more attention in earlier layers, but this attention decreases significantly in deeper layers, with over 80% of the attention being directed towards instruction tokens. This change suggests that vision tokens play a central role in early layers, where they provide relevant visual information to instruction tokens through attention mechanisms. In contrast, later layers rely more on instructions that have already incorporated visual data to generate responses

To further assess the importance of individual visual tokens, the entropy of the attention distribution at each layer is calculated. The entropy of attention toward visual tokens is much higher in the earlier layers, indicating that most visual tokens are evenly attended to in the early layers.

The visual understanding ability of LMMs is evaluated when visual tokens are dropped at different layers. LLaVA-v1.5 is tested on GQA and MMBench with visual tokens being removed at layers 1–4, then 5–8, and so on up to layers 29–32. The results showed that removing visual tokens in the early layers (1–4) led to a complete loss of visual understanding ability, while removing tokens in higher layers had little effect and the model retained most of its original performance.
LLaVA-Mini

The LLaVA-Mini model uses a pre-trained CLIP vision encoder to extract visual features from images, which are then mapped into a word embedding space using a projection layer. This produces “vision tokens” Hv. For language instructions Xq, an embedding layer generates “text token representations” Hq.
To reduce the number of vision tokens fed into the LLM backbone, LLaVA-Mini uses a query-based compression module. This module introduces learnable compression queries Qv that interact with all vision tokens Hv through cross-attention to produce compressed vision tokens Hˆ v. To preserve spatial information in the image during compression, 2D sinusoidal positional encoding is used on both the learnable queries and original vision tokens.
The compression process can be expressed as:
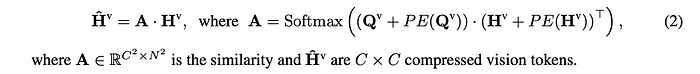
However, this compression inevitably results in some loss of visual information. To retain as much visual information as possible, LLaVA-Mini introduces a modality pre-fusion module before the LLM backbone. This module consists of Nfusion Transformer blocks and takes concatenated vision tokens Hv and text tokens Hq as input. The output corresponding to the text tokens is extracted as “fusion tokens” Hˆ q, which can be expressed as:

Finally, the compressed vision tokens Hˆ v and fusion tokens Hˆ q are fed into LLM together to generate a response.
High-Resolution Image
For high-resolution images, the model divides each image into four sub-images, processes each sub-image individually using the vision encoder (e.g., CLIP’s ViT-L), and then compresses the resulting N²×4 vision tokens into C2 compressed vision tokens using a compression module.
The modality pre-fusion module takes the four sub-images, the original image, and language instruction as inputs and generates lq fusion tokens with richer global and local visual information. The number of tokens input to the Large Language Model (LLM) is C² + lq.
Video
For videos, LLaVA-Mini processes each frame individually, generating C² vision tokens and lq fusion tokens per frame. The C² vision tokens from each frame are concatenated sequentially to yield a total of M × C² vision tokens, while the lq fusion tokens are aggregated through pooling to generate the video’s fusion tokens.
The number of tokens fed to the LLM is reduced from MN² + lq to MC² + lq for a video of M frames.
Training
LLaVA-Mini follows the same training process as LLaVA, consisting of two stages.
- Vision-Language Pretraining: During this stage, no compression or modality pre-fusion modules are applied yet (meaning the N2 vision tokens remain unchanged). Instead, LLaVA-Mini learns to align vision and language representations using visual caption data. The training process focuses solely on the projection module while keeping the vision encoder and Large Language Model (LLM) frozen in place.
- Instruction Tuning: This stage involves training LLaVA-Mini to perform various visual tasks using minimal vision tokens and instruction data. To achieve this, two new components are introduced: compression and modality pre-fusion. All modules in LLaVA-Mini (except for the frozen vision encoder) are trained end-to-end, meaning they learn together as a single unit.
Experiments
LLaVA-Mini is evaluated on 11 image benchmarks and 7 video benchmarks. It is compared to other state-of-the-art image and video LLMs. A high-resolution version, LLaVA-Mini-HD, is also tested. The model uses CLIP ViT-L/336px as the vision encoder and Vicuna-v1.5–7B as the LLM backbone. It compresses visual information into a minimal number of tokens (as low as one token per image/frame) using modality pre-fusion. For videos, one frame per second is extracted.
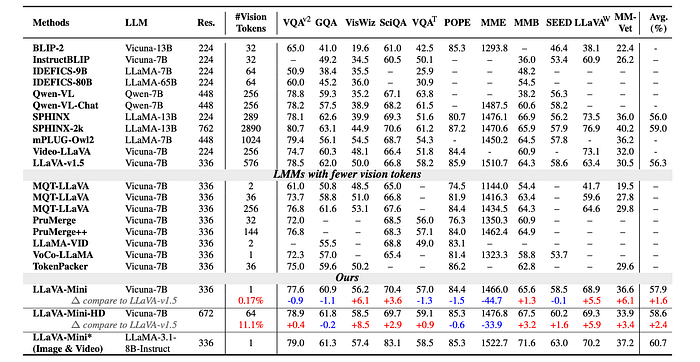
- Comparable Performance with Fewer Tokens: LLaVA-Mini achieves performance comparable to LLaVA-v1.5 on image understanding tasks while using significantly fewer vision tokens (1 vs. 576), representing a 0.17% compression rate. This is achieved through modality pre-fusion, which avoids the performance drop seen in other methods that merge tokens directly after the vision encoder.
- Improved Performance with Higher Resolution: LLaVA-Mini-HD, the high-resolution version, shows a 2.4% average performance improvement over LLaVA-v1.5.
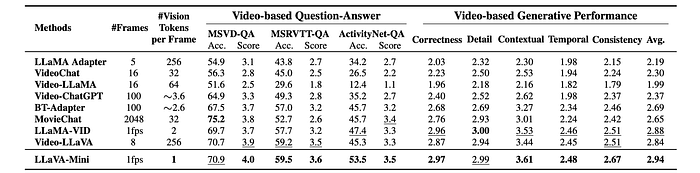
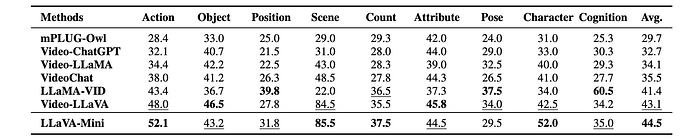
- Superior Video Understanding: LLaVA-Mini outperforms other video LMMs on several benchmarks. Its ability to represent each frame with a single token allows it to process more frames per video, capturing more visual information.
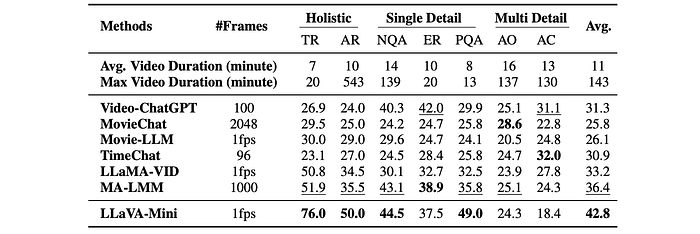
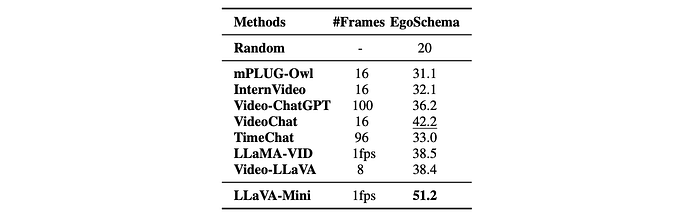
- Strong Performance on Long Videos: LLaVA-Mini demonstrates strong performance on long-form video benchmarks (MLVU and EgoSchema) despite being trained only on shorter videos, showcasing its length extrapolation capabilities.
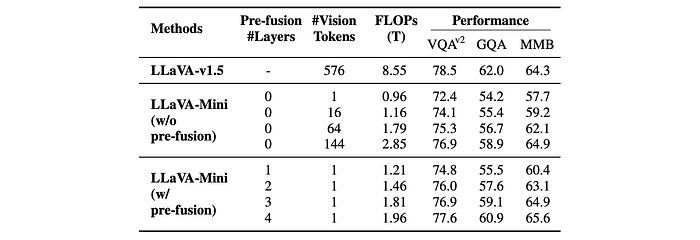
- Impact of Modality Pre-fusion: Modality pre-fusion is shown to be crucial for maintaining performance with fewer vision tokens.
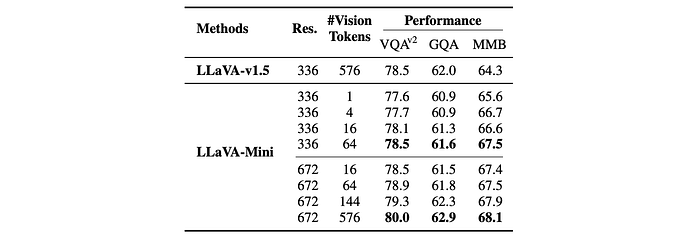
- Impact of Vision Token Count: Performance generally improves with more vision tokens, but LLaVA-Mini achieves strong results even with a minimal number.
Paper
LLaVA-Mini: Efficient Image and Video Large Multimodal Models with One Vision Token 2501.03895
Hungry for more insights?
Don’t miss out on exploring other fascinating threads in this series. Simply click here and uncover the state-of-the-art research!
Do Subscribe for weekly updates!!
