Papers Explained 296: MAmmoTH-VL

Existing multimodal instruction tuning datasets target simplistic tasks, and only provide phrase-level answers with- out any intermediate rationales. To address these challenges, we introduce a scalable and cost-effective method to construct a large-scale multimodal instruction-tuning dataset with rich intermediate rationales designed to elicit CoT reasoning. Using only open models, we create a dataset containing 12M instruction-response pairs to cover diverse, reasoning-intensive tasks with detailed and faithful rationales.
Method

The pipeline involves three key steps:
- open-source data collection and categorization
- task-specific data augmentation and rewriting using open models
- quality filtering to remove hallucinated or irrelevant content
Dataset Collection and Categorization

To achieve both scale and diversity while maintaining accessibility for open-source initiatives, data is sourced from 153 publicly available multimodal instruction datasets. The raw data includes image-text pairs covering a broad spectrum of use cases such as OCR, charts, captioning, and domain-specific images (e.g., medical).
Based on MLLM training paradigms and common downstream tasks, the training data is reorganized into 10 major categories: General, OCR, Chart, Caption, Domain-specific, Code&Math, Language, Detection, Multi-Image, and Video.
Based on quality of instructions and responses, the datasets are categorized into three groups:
- Group A (58 datasets). These datasets contain detailed, informative, and accurate responses that are well-structured and aligned with the desired task-oriented structure. Data from this group are retained in their original form as no further elaboration or rewriting was necessary.
- Group B (60 datasets). These datasets include responses that are brief or incomplete but have the potential for meaningful enhancement. To enrich their quality and utility, the data is rewritten into task-specific Q&A pairs.
- Group C (35 datasets). These datasets contain responses that are overly brief, vague, or lacking in depth, making them unsuitable for meaningful improvement.
Instruction Data Rewriting
Customized prompts are designed for each data category. For caption-based data, a text-only model (Llama-3–70B-Instruct) is employed to generate task-oriented Q&A pairs. Captions typically contain rich textual information, and text-only models are better suited for creating diverse and complex instructions compared to multimodal models. For all other types of data, a multimodal model (InternVL2-Llama3–76B) is utilized to ensure strong alignment between visual content and generated instructions, effectively leveraging both text and images for coherent outputs.
Self-data Filtering
A preliminary manual inspection of the rewritten data revealed instances of hallucinations, particularly in tasks such as OCR and chart interpretation. This underscores the necessity of a robust data filtering step to enhance the quality of the generated content. A “Model-as-Judge” approach is utilized to filter the data efficiently. Specifically, the InternVL2-Llama3–76B model is leveraged to evaluate the logical consistency of each question-answer pair against the corresponding image. The assumption is that while the model may introduce inaccuracies during generation, it excels better in verification tasks.
Model Training
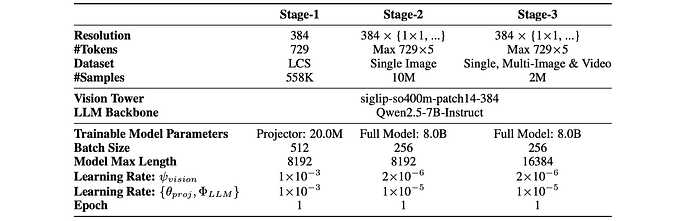
To demonstrate the effectiveness of MAmmoTH-VL- 12M, an MLLM following the architecture of Llava-OneVision is trained. This architecture comprises a language tower, a vision tower, and a projector. Qwen2.5–7B-Instruct serves as the LLM backbone, Siglip-so400m-patch14–384 as the vision tower, and a two-layer MLP as the projector. Training is divided into three stages.
- Language-Image Alignment. The goal is to align the visual features well into the word embedding space of LLMs. The same pre-training corpus as LLaVA is used.
- Visual Instruction Tuning (Single Image, SI). The model is first trained on 10M single-image instructions randomly sampled from MAmmoTH-VL- 12M.
- Visual Instruction Tuning (One Vision). The model is then trained on a mixture of single-image, multi-image, and video data (2M).
Evaluation
Single-Image Performance
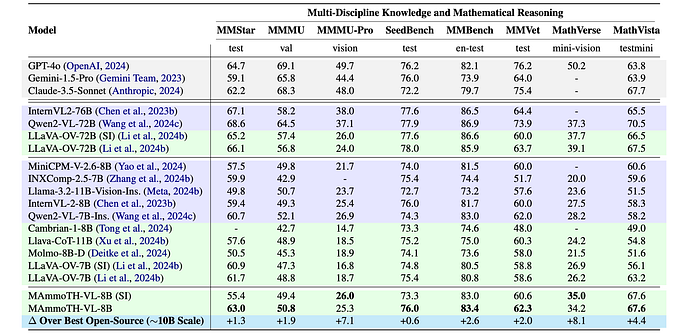
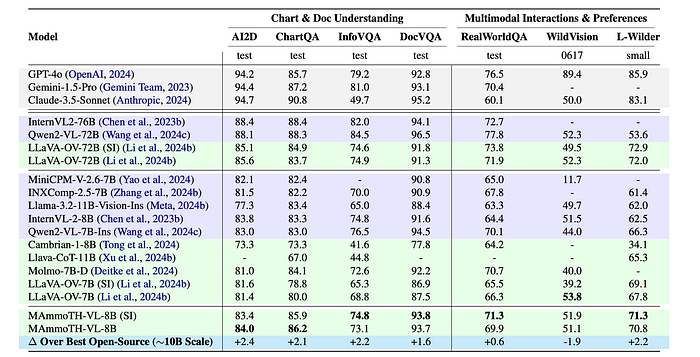
- MAmmoTH-VL-8B achieves state-of-the-art performance among open-source multimodal models across diverse benchmarks, approaching the performance of leading open-weight models.
- MAmmoTH-VL-8B achieves state-of-the-art performance on 9 benchmarks (both open-source and open-weight) particularly in mathematical reasoning.
- While the multi-image/video version of the model shows slight performance decreases on some benchmarks compared to the single-image variant (MAmmoTH-VL-8B (SI)), the overall performance remains robust.
Multi-Image and Video Performance
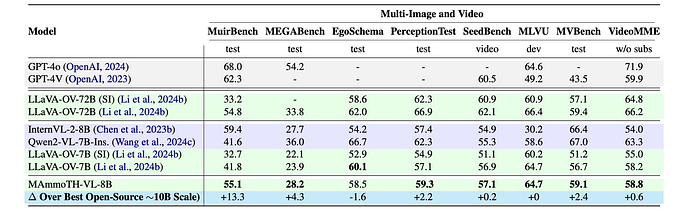
- MAmmoTH-VL-8B significantly outperforms other open-source models, including the previous best, LLaVA-One-Vision-7B. This is particularly evident on MuirBench, where it achieves a 13-point improvement.
- While showing strong performance, MAmmoTH-VL-8B still lags behind Qwen2-VL-7B. This performance gap is attributed to the limited size of the training dataset (1M multi-image/video samples) used for MAmmoTH-VL-8B due to computational constraints.
- The results suggest that further performance improvements can be achieved by increasing the amount of multi-image and video data used for training.
Paper
MAmmoTH-VL: Eliciting Multimodal Reasoning with Instruction Tuning at Scale 2412.05237
Hungry for more insights?
Don’t miss out on exploring other fascinating threads in this series. Simply click here and uncover the state-of-the-art research!
Do Subscribe for weekly updates!!