Papers Explained 294: Multi-LLM Text Summarization

The multi-LLM summarization framework has two fundamentally important steps at each round of conversation: generation and evaluation. These steps are different depending on whether the multi-LLM decentralized summarization is used or centralized. In both strategies, k different LLMs generate diverse summaries of the text. However, during evaluation, the multi-LLM centralized summarization approach leverages a single LLM to evaluate the summaries and select the best one whereas k LLMs are used for decentralized multi-LLM summarization.
Method
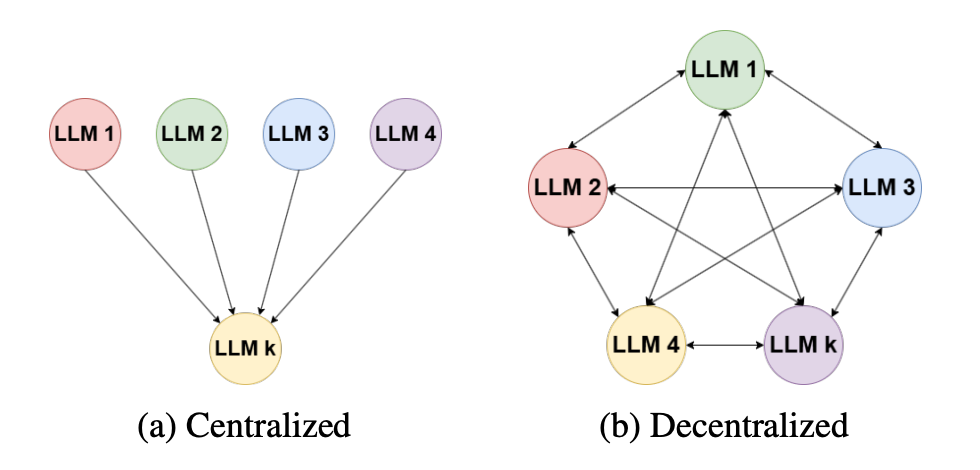
The approach tackles long text document input, which can span to tens of thousands of words and as such usually exceeds the context window of most standard LLMs. To handle this, a two stage process is established that involves chunking the source document, independently summarizing each chunk of the source document, and then applying a second round of chunking and summarization on the concatenated intermediate results. Throughout both these stages, both frameworks allow multiple LLMs to collaborate and converge on a single final high quality summary of the entire original reference document.

Centralized Multi-LLM Summarization

Single Round
Each LLM is prompted once, and their summaries are gathered. A single evaluation step then selects the best final summary.
In the single-round setting, each LLM from the list of participating models independently generates a summary of the same input text using a common prompt P. For each LLM Mj ∈ M, the output is Sj =Mj(P,S) where S represents the input text. Running this step for all Mj yields a set of summaries S = {S1,…,Sk}. Conceptually, each model contributes its unique perspective, leading to a diverse pool of candidate summaries, which is important for robust summary selection in the following evaluation phase.

After collecting the set of candidate summaries S, a central agent C ∈ M evaluates these summaries. The central LLM C uses an evaluation prompt Pec to assess the quality of each summary. Formally, E = C(Pec, S), where E is the central LLM’s evaluation of all candidate summaries. This includes the choice for the best summary (expressed as its anonymized identifier) and a confidence score for that evaluation (expressed as an integer from 0 to 10). The identifier is de-anonymized to recover the text of the selected summary Sj and set this as our final output S∗. In the single-round regime, this terminates the process as no further iterations are performed.

Conversational
The generation and evaluation phases are repeated multiple times. Each generation-evaluation process is defined as one round, and conditions under which the process ends or a new round should begin are defined, up to a maximum number of rounds.
The first round of the conversational approach mirrors the single-round procedure. Each LLM Mj generates an initial summary S(1)j from the original input text S using the prompt P: S(1) =Mj(P,S). If the evaluation result from the previous round has a confidence score less than the threshold or, if the LLM fails to output a readable confidence score, the pipeline proceeds to the next round. For the second and subsequent rounds, the prompt P(i) is used. LLMs in the subsequent rounds have access to both the text to be summarized and summaries from the previous round. Concretely, in round i > 1: S(i)j =Mj(P(i),S).

The evaluation phase in round i > 1 is conceptually similar to the single-round setting, but now operates on candidate summaries generated immediately before in the generation phase Si = {S1(i), . . . , Sk(i)}. The central LLM C evaluates these candidates using Pec: E(i) = C(Pec, Si). If the confidence level meets the threshold, the process terminates, and the summary chosen by the central LLM is accepted as S∗. Otherwise, the process proceeds to the next round of summary generation and evaluation.
Decentralized Multi-LLM Summarization

Single Round
Generation procedure is the same as that in the centralized approach. Multiple LLMs independently generate summaries for the input text, obtaining the list of summaries S = {S1,…,Sk}.
For evaluation, each model that authored a summary is prompted with a new evaluation prompt which does not include a confidence level and receives the text to be summarized along with summaries authored by all agents including itself. More formally, model preferences E(i), . . . , E(i) are collected, where each E(i) represents model Mj’s choice of the best summary among S(i),…,S(i). Convergence is achieved when a majority of models select the same summary. When no majority choice emerges, the single-round approach (tmax = 1) the algorithm selects the summary from a designated tie-breaker model Mt.

Conversational
Generation follows the methodology as in the centralised approach producing the set of summaries S = S1 , . . . , Sk . A key distinction from the single- round approach lies in the conditional regenera- tion mechanism: when consensus fails in the first round, subsequent rounds use a new prompt which includes generated summaries from previous evaluations.
The first round of evaluation is identical to that in the single-round approach, but enters additional rounds with new generation prompts. In the single-round case, non-consensus triggers an immediate fallback to a tie-breaker model. In contrast, the conversational approach initiates a new generation-evaluation round with an updated prompt. This process continues until either a majority consensus emerges or tmax rounds are exhausted. After tmax rounds without a consensus, the algorithm defaults to the tie-breaker mechanism.
Experimental Setup
ArXiv and GovReport are used to evaluate summarization methods. The quality of LLM-generated summaries is assessed using ROUGE-1, ROUGE-L, BLEU-1, and BLEU-4 metrics. For comparison with the multi-LLM approach, GPT-3.5, GPT-4o, GPT-4o mini, and LLaMA3–8B are leveraged as baselines. All models use a 4K-char chunk-size, and the final summary represents a concatenation of the generated summaries.

Evaluation

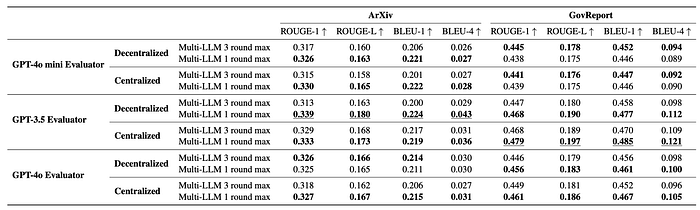
- The multi-LLM framework significantly outperforms single-LLM baselines, achieving up to 3x improvement in some cases.
- The centralized multi-LLM method improves scores by an average of 73%, while the decentralized method improves scores by an average of 70%.
- Using just two LLMs and a single round of generation and evaluation yields significant performance gains, indicating the cost-effectiveness of the approach.
- The framework’s effectiveness is consistent across different central models (evaluators) and tie-breaking models.
- Additional LLMs beyond two and additional rounds of generation and evaluation do not yield further improvements.
Implementation
from langchain_ollama import ChatOllama
gemma2 = ChatOllama(model="gemma2:9b", temperature=0)
llama3 = ChatOllama(model="llama3:8b", temperature=0)
llama3_1 = ChatOllama(model="llama3.1:8b", temperature=0)prompt_initial_summary = """
Provide a concise summary of the text in around 160 words.
Output the summary text only and nothing else.
```
{text}
```
""".strip()
prompt_subsequent_summary = """
Given the original text below, along with the summaries of that text by 3 LLMs,
please generate a better summary of the original text in about 160 words.
ORIGINAL:
```
{text}
```
Summary by agent_1:
```
{summary_1}
```
Summary by agent_2:
```
{summary_2}
```
Summary by agent_3:
```
{summary_3}
```
""".strip()
prompt_decentralised_evaluation = """
Given the original text below, along with the summaries of that text by 3 agents,
please evaluate the summaries and output the name of the agent that has the best summary.
Output the exact name only and nothing else.
ORIGINAL:
```
{text}
```
Summary by agent_1:
```
{summary_1}
```
Summary by agent_2:
```
{summary_2}
```
Summary by agent_3:
```
{summary_3}
```
""".strip()
prompt_centralised_evaluation = """
Given the initial text below, along with the summaries of that text by 3 LLMs,
please evaluate the generated summaries and output the name of the LLM has the best summary.
On a separate line indicate a confidence level between 0 and 10.
ORIGINAL:
```
{text}
```
Summary by agent_1:
```
{summary_1}
```
Summary by agent_2:
```
{summary_2}
```
Summary by agent_3:
```
{summary_3}
```
Remember, on a separate line indicate a confidence level between 0 and 10.
""".strip()
prompt_concate = """
Provide a concise summary of the text in around 160 words.
Output the summary text only and nothing else.
```
{summaries}
```
""".strip()class SingleTurnCentralised():
def __init__(self, models):
self.models = models
def generate(self, text):
summaries = []
for model in self.models:
summaries.append(model.invoke([{"role": "user", "content": prompt_initial_summary.format(text=text)}]).content)
return summaries
def evaluate(self, text, summaries):
response = gemma2.invoke([
{"role": "user", "content": prompt_centralised_evaluation.format(text=text, summary_1=summaries[0], summary_2=summaries[1], summary_3=summaries[2])}
]).content
winner, *_, confidence = response.split()
return winner, confidence
def __call__(self, chunks):
summarised_chunks = []
for chunk in chunks:
summaries = self.generate(chunk)
winner, confidence = self.evaluate(chunk, summaries)
summarised_chunks.append(summaries[int(winner[-1]) -1])
final_summary = gemma2.invoke([{"role": "user", "content": prompt_concate.format(summaries="\n".join(summarised_chunks))}]).content
return final_summary
single_turn_centralised = SingleTurnCentralised([gemma2, llama3, llama3_1])
final_summary = single_turn_centralised(chunks)Paper
Multi-LLM Text Summarization 2412.15487
Hungry for more insights?
Don’t miss out on exploring other fascinating threads in this series. Simply click here and uncover the state-of-the-art research!
Do Subscribe for weekly updates!!
