Papers Explained 277: ModernBERT

ModernBERT is a state-of-the-art encoder-only transformer model trained on 2 trillion tokens with a native 8192 sequence length, incorporating architectural advancements like GeGLU activations, RoPE embeddings, and alternating global/local attention. It utilizes unpadding, Flash Attention, and a hardware-aware design for maximized inference efficiency. Trained with an updated tokenizer and a code-inclusive dataset, ModernBERT achieves top performance across diverse tasks including GLUE (outperforming DeBERTaV3-base), BEIR (in both DPR and ColBERT settings), long-context retrieval (MLDR), and code retrieval (CodeSearchNet and StackQA), while demonstrating superior inference speed and memory efficiency compared to existing encoder models
The models are available at HuggingFace.
Architectural Improvements
Modern Transformer
Bias Terms: Bias terms are disabled in all linear layers except for the final decoder linear layer. A decoder bias might help alleviate weight tying’s negative effects. All bias terms are also disabled in Layer Norms. These two changes allow more of the parameter budget to be spent in linear layers.
Positional Embeddings: Rotary positional embeddings (RoPE) are used instead of Absolute Positional Embeddings, motivated by their proven performance in short- and long-context language models, efficient implementations in most frameworks, and ease of context extension.
Normalization: A pre-normalization block with standard layer normalization is used to help stabilize training. LayerNorm is added after the embedding layer. The first LayerNorm in the first attention layer is removed to avoid repetition.
Activation: GeGLU, a Gated-Linear Units (GLU)-based activation function, built on top of the original BERT’s GeLU activation function, is adopted.
Efficiency Improvements
Alternating Attention: Attention layers in ModernBERT alternate between global attention, where every token within a sequence attends to every other token, and local attention, where tokens only attend to each other within a small sliding window. In ModernBERT, every third layer employs global attention with a RoPE theta of 160,000 and the remaining layers use a 128 token, local sliding window attention with a RoPE theta of 10,000.
Unpadding: Encoder- only language models typically use padding tokens to ensure a uniform sequence length in a batch, wasting compute on semantically empty tokens. Unpadding avoids this inefficiency by removing padding tokens, concatenating all sequences from a minibatch into a single sequence, and processing it as a batch of one. Prior unpadding implementations unpad and repad sequences internally for different model layers, wasting compute and memory bandwidth. ModernBERT unpads inputs before the token embedding layer and optionally repads model outputs leading to a 10-to-20 percent performance improvement over other unpadding methods.
Flash Attention: Flash Attention is a core component of modern transformer- based models, providing memory and compute efficient attention kernels. ModernBERT uses a mixture of Flash Attention 3 for global attention layers and Flash Attention 2 for local attention layers.
torch.compile: PyTorch’s built-in compiling is leveraged to improve the training efficiency by compiling all compatible modules, yielding a 10 percent improvement in throughput with negligible compilation overhead.
Model Design

Deep & Narrow language models have better downstream performance than their shallower counterparts, at the expense of slower inference. Large runtime gains can be unlocked by designing models in a hardware-aware way. ModernBERT has 22 and 28 layers for the base and large models, for a total parameter count of 149 and 395 million, respectively, striking the balance between downstream performance and hardware efficiency. ModernBERT base has a hidden size of 768 with a GLU expansion of 2,304, while large has a hidden size of 1,024 and GLU expansion of 5,248. These ratios allow optimal tiling across tensor cores and the most efficient tiling across the differing number of streaming multiprocessors on the target basket of GPUs.
Training
Data Mixture: Both ModernBERT models are trained on 2T tokens of primarily English data from a variety of data sources, including web documents, code, and scientific literature, following common modern data mixtures.
Tokenizer: A modified version of the OLMo tokenizer is used, providing better token efficiency and performance on code-related tasks. The ModernBERT tokenizer uses the same special tokens (e.g., [CLS] and [SEP]) and templating as the original BERT model, facilitating backwards compatibility. To ensure optimal GPU utilization, the vocabulary is set to 50,368, a multiple of 64 and includes 83 unused tokens to support downstream applications.
Sequence Packing: To avoid high minibatch-size variance within training batches as a result of unpadding, sequence packing with a greedy algorithm is adopted. This resulted in a sequence packing efficiency of over 99 percent, ensuring batch size uniformity.
Training Settings
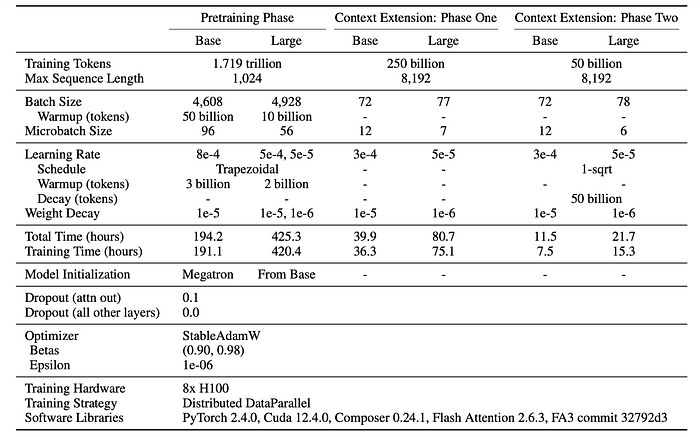
The Masked Language Modeling (MLM) setup is followed and the Next-Sentence Prediction objective is removed as it introduces noticeable overhead for no performance improvement. A masking rate of 30 percent is used, as the original rate of 15 percent has since been shown to be sub-optimal. After training on 1.7 trillion tokens at a 1024 sequence length and RoPE theta of 10,000, the native context length of ModernBERT is extended to 8192 tokens by increasing the global attention layer’s RoPE theta to 160,000 and training for an additional 300 billion tokens. Next, higher-quality sources are upsampled and the decay phase is conducted. This context extension process yielded the most balanced model on downstream tasks, as most of the ablations using only one of these strategies resulted in a performance loss on either retrieval or classification tasks.
Evaluation
ModernBERT is compared against other base and large sized models (BERT, RoBERTa, DeBERTa-v3, NomicBERT, GTE-en-MLM) on various tasks including:
- Natural Language Understanding (NLU): Evaluated using the GLUE benchmark.
- Text Retrieval: Evaluated using the BEIR benchmark in both single-vector (DPR) and multi-vector (ColBERT) settings.
- Long-Context Text Retrieval: Evaluated on the MLDR benchmark in single-vector (in-domain and out-of-domain) and multi-vector settings.
- Code Retrieval: Evaluated on CodeSearchNet (code-to-text) and StackOverflow-QA (hybrid text and code).

- General Performance: ModernBERT outperforms existing encoders (including specialized models like GTE-en-MLM and NomicBERT) across all evaluated tasks and model sizes (base and large). It represents a Pareto improvement over BERT and RoBERTa.
- Short-Context Retrieval: ModernBERT achieves superior performance on the BEIR benchmark in both DPR and ColBERT settings.
- Long-Context Retrieval: ModernBERT demonstrates strong performance on the MLDR benchmark, particularly in the multi-vector setting. In the single-vector setting, it performs well but highlights the potential need for long-context fine-tuning.
- NLU: ModernBERT achieves state-of-the-art results on the GLUE benchmark for base-sized models and near state-of-the-art for large models, surpassing DeBERTa-v3 in some cases.
- Code Retrieval: ModernBERT excels in code-related tasks (CodeSearchNet and StackOverflow-QA), likely due to its code-aware pretraining.
Efficiency
To measure and compare the inference efficiency (tokens processed per second) of different language models, such as ModernBERT and GTE-en-MLM, across various sequence lengths, Four synthetic datasets of documents are created with fixed and varying lengths (512, 8192 tokens). Models were evaluated based on tokens processed per second, averaged over ten runs. Evaluations were conducted on a single NVIDIA RTX 4090 GPU.
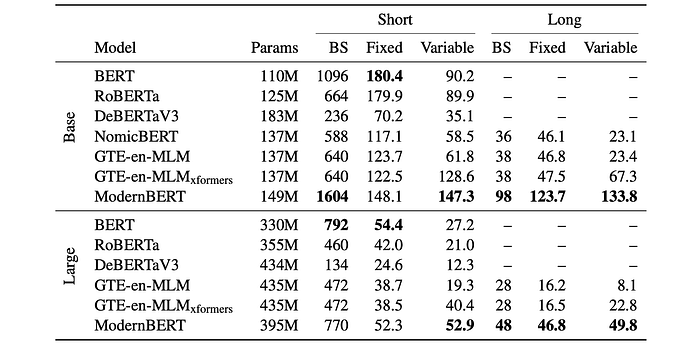
- ModernBERT consistently outperforms other models in terms of inference efficiency.
- On short context, ModernBERT is faster than recent encoders but slower than original BERT and RoBERTa.
- On long context, ModernBERT is significantly faster than competitors, processing documents 2.65 to 3 times faster at BASE and LARGE sizes, respectively.
- ModernBERT-large’s speed at 8192 tokens is closer to GTE-en-MLM base than GTE-en-MLM-large.
- Both GTE-en-MLM and ModernBERT benefit from unpadding, but ModernBERT remains more efficient due to its local attention mechanism.
- ModernBERT is the most memory-efficient model, processing larger batch sizes than other models.
Paper
Smarter, Better, Faster, Longer: A Modern Bidirectional Encoder for Fast, Memory Efficient, and Long Context Finetuning and Inference 2412.13663
Hungry for more insights?
Don’t miss out on exploring other fascinating threads in this series. Simply click here and uncover the state-of-the-art research!
Do Subscribe for weekly updates!!
