Papers Explained 276: Self-Taught Evaluators

This paper presents an approach that aims to improve evaluators without human annotations, using synthetic training data only. Starting from unlabeled instructions, an iterative self- improvement scheme generates contrasting model outputs and trains an LLM-as-a-Judge to produce reasoning traces and final judgments, repeating this training at each new iteration using the improved predictions.
Method

The setting considered is pairwise evaluation using the LLM-as-a-Judge approach that takes:
- an input (user instruction) x
- two possible assistant responses y(A) and y(B) to the user instruction x
- the evaluation prompt containing the rubric and asking to evaluate and choose the winning answer.
It is common to output, prior to the final judgment, a chain-of-thought (or “reasoning chain”), which is a set of steps generated in natural language that helps the model decide its final judgment.
The overall proposed method is an iterative training scheme that bootstraps improvements by annotating the current model’s judgments using constructed synthetic data — so that the Self-Taught Evaluator is more performant on the next iteration.
Initialization
Access to a large set of human-written user instructions, for example, the type commonly collected in production systems, and an initial seed LLM is assumed.
Instruction Selection
A challenging, balanced distribution of user instructions is selected from the uncurated set by categorizing them via LLM.
Response Pair Construction
For each input xi in the curated training pool, preference data involving two responses y(w) and y(l) is generated where w is expected to be preferable (winning) over l (losing).
Given the instruction xi, an instruction-following LLM first generates a baseline response yw as usual. The LLM then generates a “noisy” version of the original instruction x′ = φ(x).

The LLM is then prompted for a high-quality response yl to x′, which would not be a good response for x. This yields a synthetic preference yw ≻ yl for the original input x.
This paired data is then used to construct training examples: (xi, y(A), y(B)) where the order of whether the winner is w=A or w=B is randomized. This is important to deal with position bias for LLM-as-a-Judge inference.
Judgment Annotation
The LLM-as-a-Judge model generates evaluation judgments (reasoning chains and verdicts) for each training example (xi, y(A), y(B)). For a given input ei, N diverse evaluations J := {ji1,…,jiN} are collected by sampling from the model. Rejection sampling is then applied to filter J by removing jin when the final verdict disagrees with the ground truth labeling. A single correct reasoning chain and verdict are selected at random from the pool of correct solutions. If no such judgment exists (J is empty) then the example is discarded. This allows for the construction of final training examples of synthetic preferences for fine-tuning: ((xi, y(A), y(B)), ji).
Model Fine-tuning (Iterative Training)
The Self-Taught Evaluator (LLM-as-a-Judge model) is first initialized with the seed LLM. The model is then trained in an iterative manner. At each iteration, training examples are annotated with judgments using the current model, giving training examples {(xi, y(A), y(B), ji)}. These are used to train the next iteration’s model by fine-tuning. Note that the seed model is initialized at each iteration.
Experimental Setup
Initial model M0 is initialized from Llama3–70B-Instruct.
A large pool of human-written instructions {xi} from the WildChat dataset is used. To perform prompt selection, the category of each instruction is annotated with the Mixtral 22Bx8 Instruct model and 20,582 examples in the reasoning category are selected.

For the selected inputs synthetic responses y^w and y^l are generated using Mixtral 22Bx8 Instruct
For each training example, N = 15 judgments are sampled from the model Mi−1 and one positive sample ji per example is retained. Over the entire dataset, the same amount of examples from different labels (“A is better”, “B is better”) are sampled to ensure balanced training. Judgements for training M0 were sampled from Mixtral 22Bx8 Instruct, and from the Llama model being trained in all subsequent iterations. The training data is constructed as (<system prompt>, {(xi, y(A), y(B), ji)}).

As LLM-as-a-Judge uses chain-of-thought reasoning chains generated by the LLM followed by a verdict, majority vote inference can yield improvements. At inference time when evaluating final performance, generations are sampled N times, and the final judgment is taken to be the most common verdict.

To evaluate the proposed method, synthetic judgments are generated using various data sources and methods:
- HelpSteer2: Judgments are generated based on the dataset’s scores for helpfulness, correctness, coherence, complexity, and verbosity. An aggregated score, derived using a specific weighting [0.65, 0.8, 0.45, 0.55, −0.4], determines the ground truth preference for each example.
- GSM8K: Judgments are created by sampling from an instruction-following model multiple times. The model generates “yw” when the final solution matches the ground truth and “yl” when it differs.
- Coding instructions from WildChat: Similar to the “reasoning” prompts used in the main experiment, the authors also utilize “Coding” category prompts from WildChat to generate judgments.
- hh_rlhf: Judgments are generated based on prompts and responses from the “harmless_base” training split. Human preferences provided in the dataset are used as ground truth, and rejection sampling is employed to construct the judgments.
Evaluation
The evaluation is conducted on three benchmarks: RewardBench, MT-Bench, and HelpSteer2.
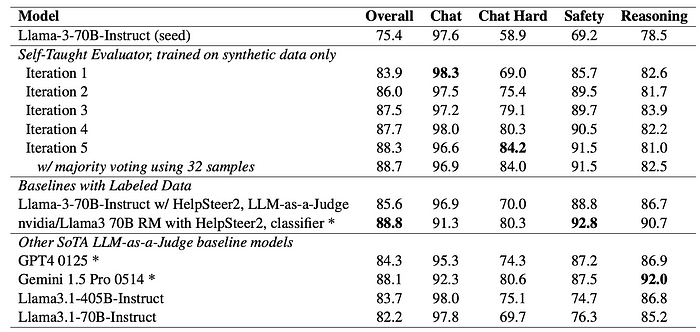
RewardBench: The Self-Taught Evaluator significantly outperforms the seed model, achieving a score of 88.3 on iteration 5 compared to the seed model’s 75.4. This performance is comparable to top-performing reward models trained with labeled data. Improvements are particularly noticeable in the Chat Hard, Safety, and Reasoning categories. Majority voting further boosts performance to 88.7, surpassing many existing reward models.
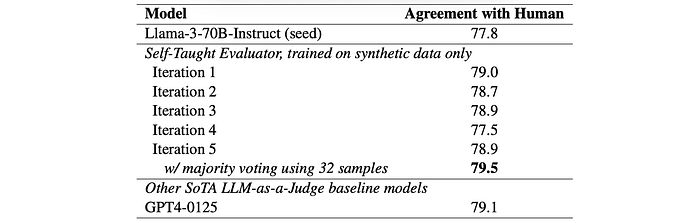
MT-Bench: The Self-Taught Evaluator outperforms the seed model and performs on par with or slightly better than GPT4–0125 on non-tie examples. Evaluation considers both possible orderings of responses A and B.
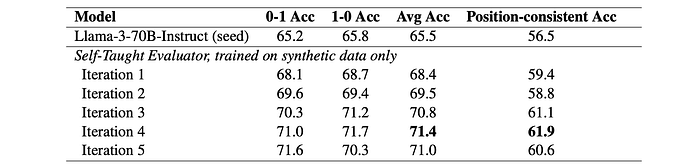
HelpSteer2: The Self-Taught Evaluator demonstrates improved average accuracy and position-consistent accuracy compared to the seed model. Evaluation includes analyzing both individual orderings and the average across orderings to assess position bias.
Paper
Self-Taught Evaluators 2408.02666
Hungry for more insights?
Don’t miss out on exploring other fascinating threads in this series. Simply click here and uncover the state-of-the-art research!
Do Subscribe for weekly updates!!
