Papers Explained 270: OLMoE

OLMoE is a sparse Mixture-of-Experts based Language Model with 7B parameters, out of which only 1B parameters are active per input token, making it more cost-effective than dense models with similar parameter counts.
Pretrained on 5 trillion tokens, OLMoE-1B-7B outperforms all comparable open-source models and even rivals larger closed-source models. Further fine-tuning through instruction and preference learning yields OLMoE-1B-7B-Instruct which surpasses larger instruct models on benchmarks like MMLU, GSM8k, and HumanEval.
The models and dataset are available at HuggingFace.
Recommended Reading [Papers Explained 98: OLMo]
Approach
Model Architecture
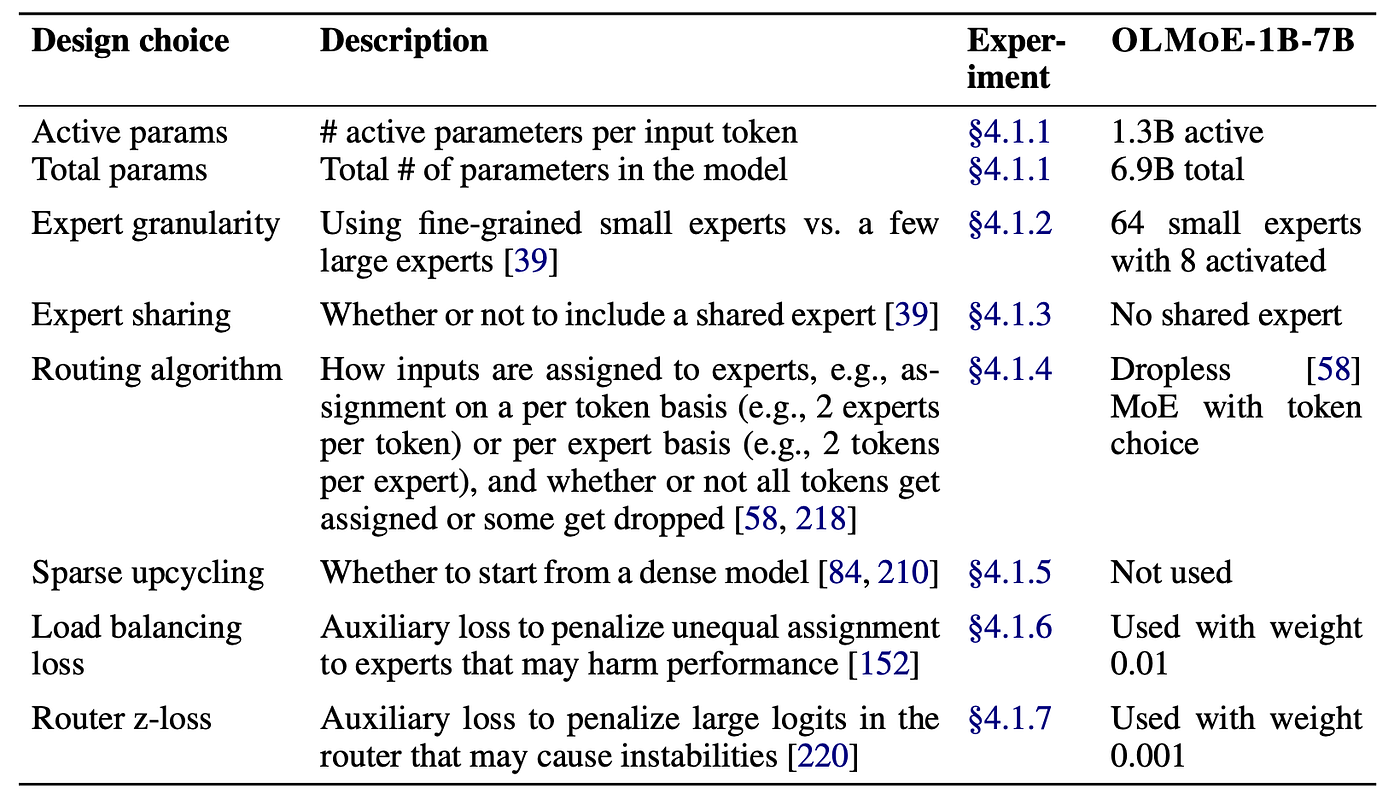
OLMoE is a decoder-only LM consisting of NL transformer layers. The feedforward network (FFN) in dense models like OLMo, is replaced with an MoE module consisting of NE smaller FFN modules called experts, of which a subset of k experts are activated for each processed input token x.


where r, called the router, is a learned linear layer mapping from the input logits to the chosen k experts. A softmax is applied to the router outputs to compute routing probabilities for all NE experts. Each selected expert Ei processes the input x, the output of which is then multiplied with its respective routing probability. The results are then summed across all chosen Top-k experts to constitute the output of the MoE module for a single layer of the model out of its NL total layers.
PreTraining
A mix of data is used, including a quality-filtered subset of Common Crawl referred to as DCLM-Baseline, StarCoder, Algebraic Stack, arXiv, peS2o, and Wikipedia. This pre-training dataset is referred to as OLMoE-Mix.

All sources above are filtered to remove documents with a sequence of 32 or more repeated n-grams, where an n-gram is any span of 1 to 13 tokens. For the StarCoder subset, additional filtering removes any document that is either from a repository with fewer than 2 stars on GitHub, or whose most frequent word constitutes over 30% of the document, or whose top-2 most frequent words constitute over 50% of the document.
All samples are shuffled randomly at the beginning of each epoch and training occurs for a total of 5.133T tokens (1.3 epochs). During the annealing phase (final 100B tokens), the entire dataset is reshuffled, and then the learning rate is linearly decayed to 0.
Adaptation
OLMoE-1B-7B-Instruct is created by the standard adaptation recipe split into instruction tuning followed by preference tuning.
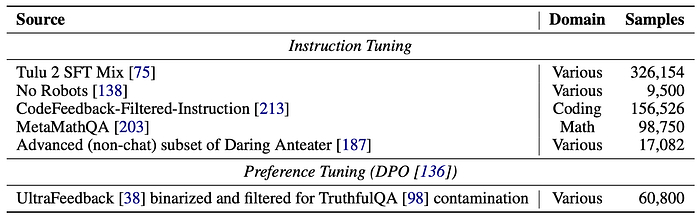
The instruction tuning dataset includes additional code and math data to boost performance on downstream coding and math applications. No Robots and a subset of Daring Anteater were also included, as they are of high quality and add diversity, two key factors for successful adaptation.
Evaluation
During Pre Training
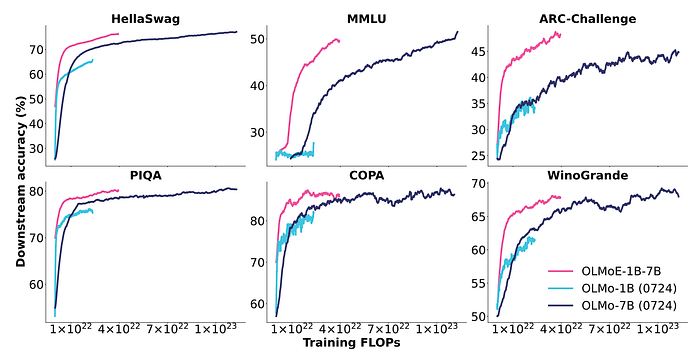
- OLMoE-1B-7B achieves superior performance compared to existing OLMo models across all tested downstream tasks.
- Despite using less than half the FLOPs and only 1B active parameters compared to OLMo-7B, OLMoE-1B-7B matches or surpasses its performance.
- The improved performance is attributed to the dataset and modeling changes implemented.
After Pre Training
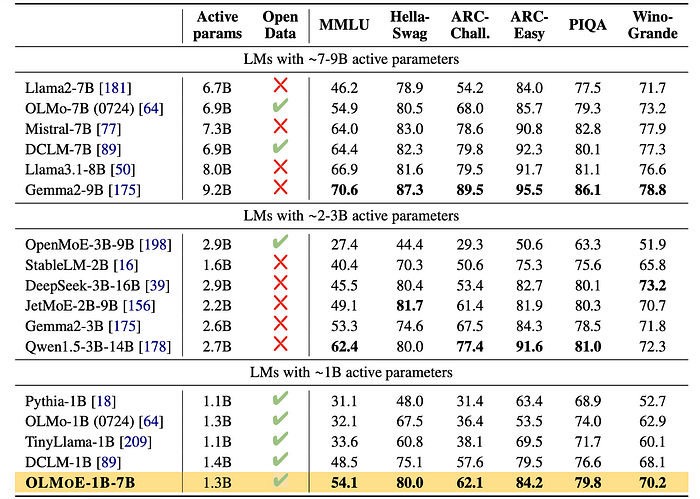
- OLMoE-1B-7B outperforms models with less than 2B active parameters, making it the most cost-effective option.
- Despite requiring 6–7 times less compute per forward pass, OLMoE-1B-7B surpasses some dense 7B parameter models like Llama2–7B but falls short of models like Llama3.1–8B.
- OLMoE-1B-7B achieves state-of-the-art performance in its cost regime (considering active parameters as a proxy for cost).
After Adaptation
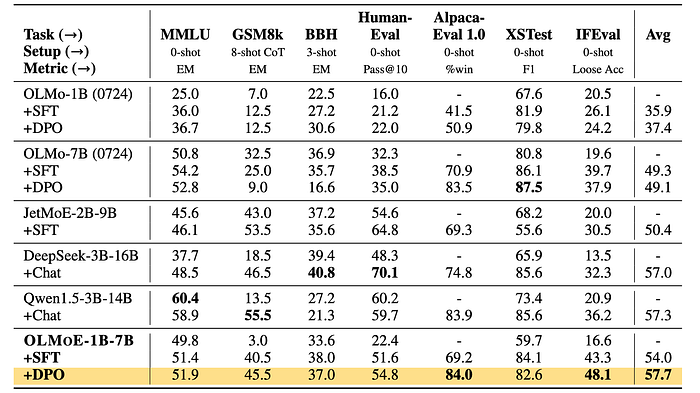
- SFT significantly improved model performance on all tasks, with a >10× gain on the GSM8k dataset (likely due to additional math data incorporated during training).
- DPO tuning was particularly beneficial for tasks like AlpacaEval, aligning with previous research.
- The DPO-tuned model (OLMoE-1B-7B-Instruct) achieved the highest average performance across all benchmarked tasks.
- OLMoE-1B-7B-Instruct outperformed the chat version of Qwen1.5–3B-14B, despite Qwen having more parameters and a pretrained model that outperformed OLMoE-1B-7B in Table 4.
- OLMoE-1B-7B-Instruct achieved an 84% score on AlpacaEval, surpassing even larger dense models on the leaderboard.
Experimenting with Alternative Design Choices
Mixture-of-Experts vs. Dense
A controlled setup is used to compare MoEs and dense models. An MoE configuration with 6.9B total parameters and 1.3B active parameters is selected, matching OLMo-7B in total parameter count and OLMo-1B in active parameter count, respectively.
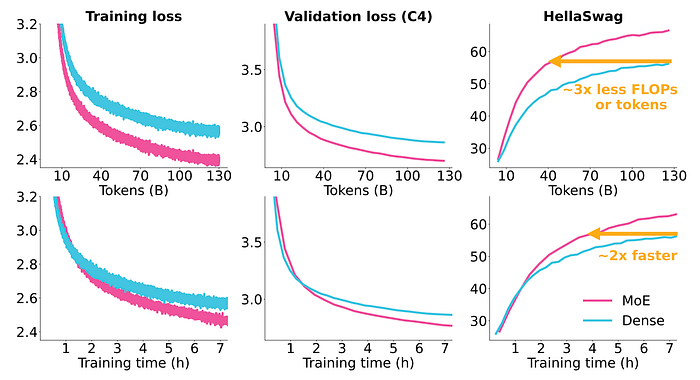
- The MoE model achieves comparable performance to the dense model with approximately 3 times fewer tokens (equivalent to 3 times less compute measured in FLOPs).
- Due to the memory overhead of training the MoE, its token processing speed is lower (23,600 tokens per second per GPU) compared to the dense model (37,500 tokens per second per GPU).
- Despite the lower processing speed, the MoE model trains approximately 2 times faster than the dense model.
Expert Granularity
Experiment with different numbers of experts per layer in an LLM architecture, varying the size of each expert while maintaining a constant compute budget.
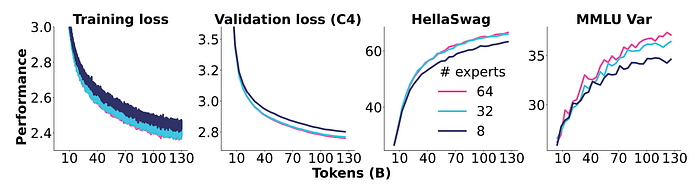
- Increasing expert granularity (smaller experts, more experts) generally leads to improvements in training loss, validation loss, and downstream performance.
- A configuration with 32 experts (4 active) outperforms the baseline of 8 experts (1 active) by around 10% on tasks like HellaSwag and MMLU.
- However, there are diminishing returns to further increasing granularity. Moving to 64 experts (8 active) yields a smaller improvement of 1–2%.
Shared Experts
A single shared and a single routed expert is benchmarked against two routed experts.
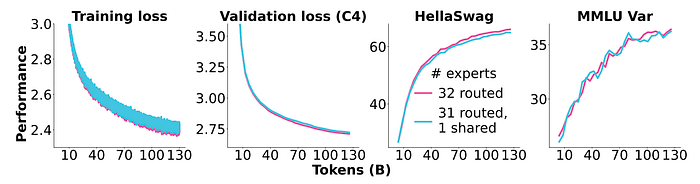
- While both settings lead to similar performance, sharing an expert performs slightly worse.
- Hence shared experts are not used in OLMOE-1B-7B
Expert Choice vs. Token Choice
The MoE router determines which experts process each input token. There are two common types:
- Expert Choice (EC): Each expert selects a fixed number of tokens from the input sequence, ensuring load balance.
- Token Choice (TC): Each token selects a fixed number of experts, potentially leading to uneven load distribution and requiring a load balancing loss.
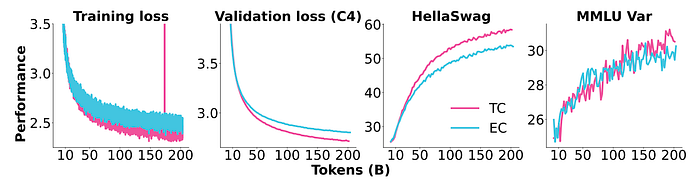
- TC outperforms EC for the same token bud- get for all tasks.
- TC’s performance is attributed to the use of dropless MoEs and a load balancing loss, leading to better performance compared to previous TC implementations.
- EC remains around 20% faster at 29,400 tokens per second per device compared to TC’s 24,400 tokens per second per device.
- EC might be more suitable for multimodal setups where dropping noisy image tokens is less detrimental than text tokens.
- While TC is preferred for the current release of OLMoE, EC might be revisited for future multimodal models.
Sparse Upcycling
- Dense MLP is cloned for each desired expert to constitute MoE layers.
- A newly initialized router is added in front of each MoE layer.
- Pretraining continues with the new model so that the cloned MLPs can gradually specialize in different things and the router can be learned.
Upcycled MoE models are compared with MoE models trained from scratch.
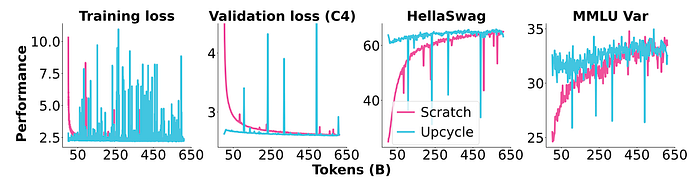
- While sparse upcycling can be effective, training an MoE from scratch can achieve comparable performance with less compute.
- The performance of upcycled models is limited by the hyperparameters of the original dense model.
- Adding noise to the upcycled weights does not improve performance.
Paper
OLMoE: Open Mixture-of-Experts Language Models 2409.02060
Hungry for more insights?
Don’t miss out on exploring other fascinating threads in this series. Simply click here and uncover the state-of-the-art research!
Do Subscribe for weekly updates!!
