Papers Explained 264: Jina Embeddings v2

The current open-source text embedding models struggle to represent lengthy documents and often resort to truncation, requiring splitting documents into smaller paragraphs for embedding, resulting in a much larger set of vectors, leading to increased memory consumption and computationally intensive vector searches with elevated latency.
To address these challenges, this paper introduces JinaEmbeddingsv2, an open-source text embedding model capable of accommodating up to 8192 tokens.
The models are available at HuggingFace.
Recommended Reading [Papers Explained 263: Jina Embeddings v1]
Training Paradigm
The training paradigm for Jina Embeddings v2 is divided into three stages:
- Pre-training a Modified BERT
- Fine-tuning with Text Pairs
- Fine-tuning with Hard Negatives

Pre-training a Modified BERT
For the backbone language model, a novel transformer based on BERT is introduced with several modifications to enhance its ability to encode extended text sequences and to generally improve its language modeling capabilities:
- For the self-attention mechanism within the attention blocks, the Attention with Linear Biases (AL-iBi) approach is adopted. ALiBi forgoes the use of positional embeddings. Instead, it encodes positional information directly within the self-attention layer by introducing a constant bias term to the attention score matrix of each layer, ensuring that proximate tokens demonstrate stronger mutual attention. While the original implementation was designed for causal language modeling and featured biases solely in the causal direction, such an approach is not compatible with the bidirectional self-attention inherent in the encoder model. For these purposes, the symmetric encoder variant is employed where attention biases are mirrored to ensure consistency in both directions.

Each head’s scaling value, mi, out of the total n heads, is derived using:

- For the feedforward sub-layers within the attention blocks, Gated Linear Units (GLU) are adopted. For the small and base models, the GEGLU variant, which leverages the GELU activation function for the GLU is used. Conversely, for the large model, the ReGLU variant with the ReLU activation function is used.
- Regarding Layer Normalization, the post-layer normalization approach from the original transformer is used. Preliminary tests with pre-layer normalization, didn’t enhance training stability or performance. Consequently, it is not integrated into the model.
The pre-training phase leverages the English “Colossal, Cleaned, Common Crawl (C4)” dataset, which contains approximately 365M text documents harvested from the web, summing to around 170B tokens. One percent of the dataset is reserved for evaluating validation loss and the accuracy of the masked language modeling (MLM) task.
30% of the input tokens are randomly masked, employing whole word masking, and condition the models to infer these masked tokens. Of these masked tokens, 80% are substituted with the [MASK] token, 10% with a random token, and the remaining 10% stay unaltered. The loss LMLM is computed by evaluating the cross entropy between the predicted probabilities and the actual masked tokens.
Given the use of ALiBi attention, training position embeddings becomes unnecessary. This allows it to pre-train more efficiently on shorter sequences and adapt to longer sequences in subsequent tasks. Throughout the pre-training, sequences are capped at 512 tokens in length.
Fine-Tuning for Embeddings
To enable the model to perform a text operation, a mean pooling layer is added, which averages the token embeddings to merge their information into a single representation, without introducing additional trainable parameters.
Fine-tuning with Text Pairs
During the first fine-tuning stage, we train the mod- els on a corpus of text pairs (q, p). Roughly 40 diverse data sources are used similar to the data preparation outlined in the jina embeddings v1.
The goal of this fine-tuning stage is to encode text values that constitute a pair into analogous embedding representations, while encoding texts that aren’t paired into distinct embeddings. To achieve this contrastive goal, the InfoNCE loss function is used, similar to the jina embedding v1.
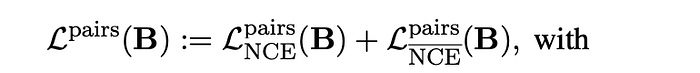

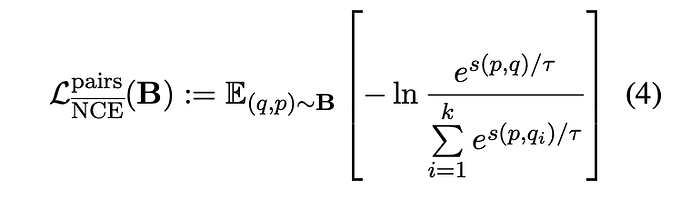
Fine-tuning with Hard Negatives
The goal of the supervised fine-tuning stage is to improve the models’ ranking capabilities. This improvement is achieved by training with datasets that include additional negative examples. Each training batch B, structured as (q, p, n1, . . . , n15), includes one positive and 15 negative instances.
For retrieval datasets, hard negatives are discerned by identifying passages deemed similar by retrieval models.
For non-retrieval datasets, negatives are selected randomly, since drawing a clear line between positives and hard negatives isn’t feasible.
The training employs a modified variant of the InfoNCE loss function, denoted as LNCE+. Similar to the preceding loss function, this one is bidirectional and incorporates the additional negatives when pairing queries with passages:
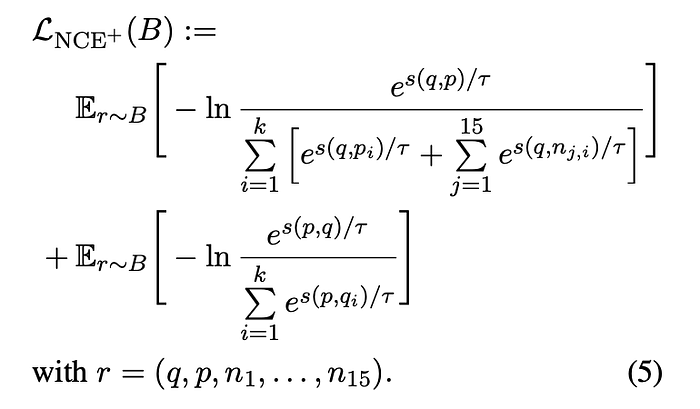
Evaluation
Evaluation of Jina BERT
The performance of the pre-trained JinaBERT models is evaluated on the GLUE benchmark, a collection of nine datasets for evaluating natural language understanding systems. Additionally, JinaBERT’s ability to handle long text sequences was assessed by evaluating masked language modeling (MLM) accuracy on varying sequence lengths. The pre-trained JinaBERT models are fine-tuned on each GLUE task for 10 epochs. For RTE, STS, and MRPC tasks, fine-tuning started from the MNLI single-task model.

- JinaBERT achieves competitive results on the GLUE benchmark.
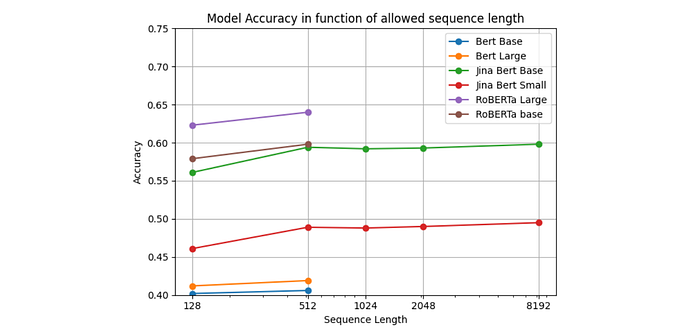
- JinaBERT maintains high MLM accuracy even when extrapolated to sequence lengths of 8192, demonstrating the effectiveness of ALiBi (the architecture used in JinaBERT) for handling long documents. This is in contrast to other BERT and RoBERTa models that rely on absolute positional embeddings and struggle with longer sequences.
Evaluation of Jina Embeddings v2
The MTEB Benchmark evaluates the model across 8 tasks and 58 datasets, covering 112 languages. This ensures comprehensive testing across various applications. For long-text evaluations, which are not covered by the MTEB, two new tasks are introduced.
Clustering: Uses a mini-batch k-means model, evaluated by the V measure. Two new clustering tasks introduced:
- PatentClustering: Uses the BigPatent dataset, challenging the model to cluster patents by category (documents average 6,376 tokens).
- WikiCitiesClustering: Involves grouping Wikipedia city articles by their respective countries (documents average 2,031 tokens).
Retrieval: Inspired by the BEIR dataset, retrieval tasks are evaluated using metrics such as nDCG@10, MRR@k, and MAP@k. A new retrieval task, NarrativeQA, is introduced for long-text QA.
LoCo Benchmark: Consists of five long-text retrieval tasks from publicly available datasets, with an emphasis on document length and thorough understanding.
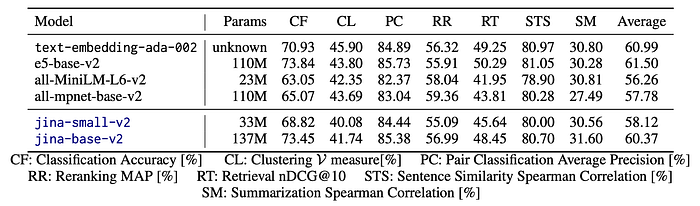
- Classification (CF): Jina-base-v2 (137M parameters) performed better than jina-small-v2 (33M parameters), showing the influence of model size in certain tasks.
- Retrieval (RT): Both models showed strong performance, with jina-base-v2 having a slight edge.
- Models like all-MiniLM-L6-v2 and all-mpnet-base-v2 underperformed in retrieval tasks due to a lack of second-stage fine-tuning, which jina models underwent.
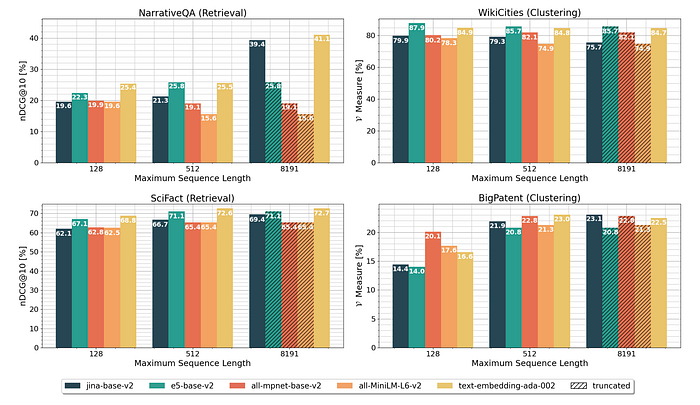
- For the NarrativeQA retrieval task, longer sequence lengths improved model performance significantly, especially for jina-base-v2 and OpenAI’s text-embedding-ada-002, both of which support 8K tokens.
- For BigPatent clustering, extended sequence lengths led to better results.
- For WikiCities clustering, longer sequence lengths resulted in slightly lower performance, as the first few sentences of articles typically contain the most relevant information for clustering by country.
Paper
Jina Embeddings 2: 8192-Token General-Purpose Text Embeddings for Long Documents 2310.19923
Recommended Reading [Retrieval and Representation Learning]
Hungry for more insights?
Don’t miss out on exploring other fascinating threads in this series. Simply click here and uncover the state-of-the-art research!
Do Subscribe for weekly updates!!
