Papers Explained 260: GSM-Symbolic

This research investigates the true mathematical reasoning abilities of LLMs by addressing concerns about the reliability of existing benchmarks like GSM8K. The authors introduce GSM-Symbolic, a new benchmark based on symbolic templates that generate diverse questions, allowing for more controlled and reliable evaluations.
Their findings reveal several key insights:
- Variance in Performance: LLMs show significant performance variations when answering different versions of the same question, particularly when only numerical values change. This suggests a reliance on pattern recognition rather than genuine understanding.
- Fragility of Reasoning: Performance drops drastically as the number of clauses in a question increases, indicating a limitation in handling complex logical reasoning.
- Susceptibility to Irrelevant Information: Adding a seemingly relevant but ultimately unnecessary clause to a question causes a significant performance drop (up to 65%) across all tested models. This suggests LLMs may struggle to distinguish relevant from irrelevant information and might simply mimic patterns observed during training.
GSM-Symbolic: Template Generation

Given a specific example from the test set of GSM8K, parsable templates are created. The annotation process involves identifying variables, their domains, and necessary conditions to ensure the correctness of both the question and the answer. After creating the templates, several automated checks are applied to ensure the annotation process is correct. Once data is generated, 10 random samples per template are reviewed manually. As a final automated check, after evaluating all models, at least two models are verified to answer each question correctly; otherwise, the question is reviewed manually again.
Experimental Setup
A manageable dataset size is maintained by using 100 templates and generating 50 samples per template, resulting in 50 datasets of 100 examples each, where each example is a mutation of one of the original 100 examples from GSM8K. The evaluation setup follows a common procedure on GSM8K and other math benchmarks, which includes Chain-of-Thought (CoT) prompting with 8-shots and greedy decoding. It is noted that in preliminary experiments, the number of shots does not significantly change the performance and conclusions.
Experiments
How Reliable Are the Current GSM8K Results?
Several pre-trained language models are tested on 50 different datasets generated from GSM-Symbolic. The performance of these models on GSM-Symbolic is compared to their performance on the original GSM8K dataset, which served as the template for GSM-Symbolic.

- High Variance in Performance: All models exhibited significant performance variance across different GSM-Symbolic datasets. For example, Gemma2–9B’s performance varied by over 12%, and Phi-3.5-mini’s by around 15%.
- Performance Discrepancy: Models often performed better on the original GSM8K questions than on the GSM-Symbolic datasets. This suggests potential data contamination, where GSM8K test examples might have inadvertently been included in the training data.
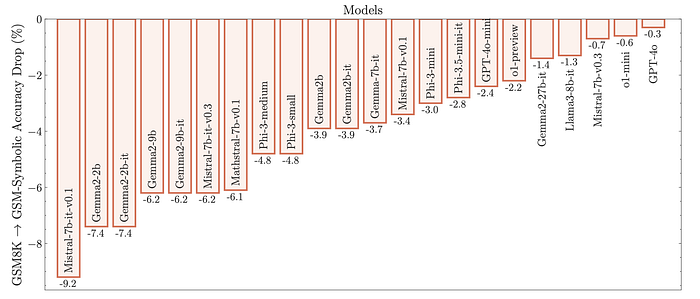
- Performance Drop: Models like Gemma2–9B, Phi-3, Phi-3.5, and Mathstral-7B showed a larger performance drop from GSM8K to GSM-Symbolic compared to models like Llama3–8b and GPT-4o. This further supports the data contamination hypothesis.
How Fragile is Mathematical Reasoning in Large Language Models?
Investigation of the impact of the type of change to understand the difference between changing names (e.g., person names, places, foods, currencies, etc.) versus changing numbers (i.e., the values of variables).
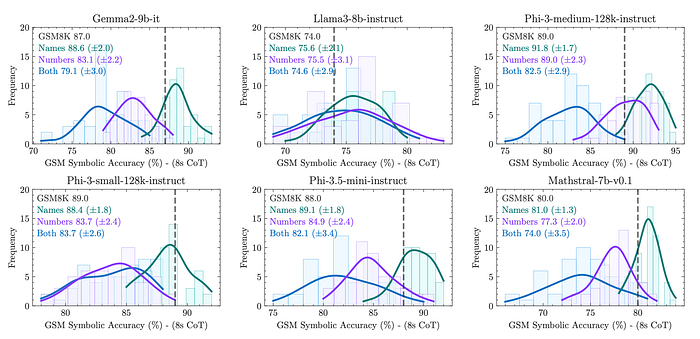
- Performance varies significantly when changing numbers compared to names.
- Changing names leads to lower variance in performance.
- Original GSM8K accuracy is closer to the center of the changed proper names distribution.
How Does Question Difficulty Affect Performance Distribution?
To investigate the impact of question difficulty on the mean and variance of model performance, new question templates are generated from the GSM-Symb dataset by:
- removing one clause (GSM-M1)
- adding one or two clauses (GSM-P1 and GSM-P2).

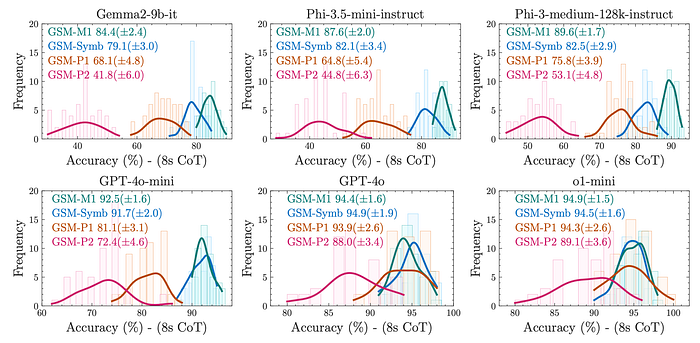
- As question difficulty increases (GSM-M1 to GSM-P2), performance decreases and variance increases.
- The rate of accuracy drop accelerates as difficulty increases, suggesting models may not be performing formal reasoning.
- The increased variance indicates that pattern-matching and searching become more challenging for models with higher difficulty questions.
Can LLMs Really Understand Mathematical Concepts?
To investigate the susceptibility of language models to “catastrophic performance drops” on instances outside their training distribution, a new dataset, GSM-NoOp, is created by adding seemingly relevant but inconsequential (“No-Op”) statements to existing GSM-Symbolic templates.

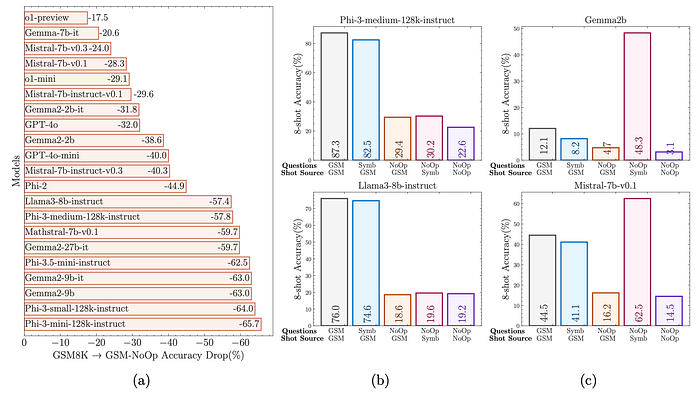
- Performance Decline on GSM-NoOp: Models exhibit a significant performance drop on GSM-NoOp, with some models (e.g., Phi-3-mini) experiencing over a 65% decline.
- Blindly Converting Statements: Models tend to convert statements to operations without truly understanding their meaning, potentially due to overfitting to patterns in training data.
- Limited Impact of Reasoning Shots: Providing 8 shots of the same question from GSM-Symbolic does not significantly improve performance on GSM-NoOp.
- Potential for Improvement with NoOp-NoOp Shots: Some models show improved performance when provided with 8 shots from different GSM-NoOp questions.
Paper
GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models 2410.05229
Hungry for more insights?
Don’t miss out on exploring other fascinating threads in this series. Simply click here and uncover the state-of-the-art research!
Do Subscribe for weekly updates!!
