Papers Explained 254: Pix2Struct

Pix2Struct, a pretrained image-to-text model for purely visual language understanding, which can be finetuned on tasks containing visually-situated language. Pix2Struct is pretrained by learning to parse masked screenshots of web pages into simplified HTML.
Architecture

Pix2Struct is an image-encoder-text-decoder based on ViT. While the bulk of the model is fairly standard, one small but impactful change is proposed to the input representation to make Pix2Struct more robust to various forms of visually-situated language. Before extracting fixed-size patches, the standard ViT scales the input images to a predefined resolution, which creates two undesirable effects:
- rescaling the image distorts the true aspect ratio, which can be highly variable for documents, mobile UIs, and figures.
- transferring these models to downstream tasks with higher resolution is non-trivial since the model only observes one specific resolution during pretraining.
The input image are always scaled up or down to extract the maximum number of fixed-size patches that fit within the given sequence length. In order for variable resolutions to be handled unambiguously by the model, 2-dimensional absolute positional embeddings are used for the input patches. Together, two major advantages are offered by these changes to the standard ViT inputs in terms of robustness:
- extreme aspect ratios, which is common in the domains that are experiment with
- on-the-fly changes to the sequence length and resolution.
Pretraining
The goal of pretraining is for the underlying structure of the input image to be represented by Pix2Struct. To that end, self-supervised pairs of input images and target text are created from web pages. For each page in the pretraining corpus, its HTML source and a screenshot are collected using a viewport of 1024 x 1024.
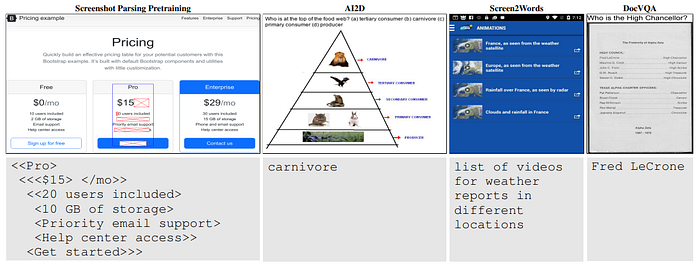
Screenshot parsing inputs & outputs

The screenshot and HTML are modified to ensure rich and dense learning signal during pretraining.
The HTML DOM tree is condensed by (1) only keeping nodes with visible elements or descendants with visible elements and (2) if a node does not contain visible elements and it only has a single child, replacing the singleton child with any grandchildren to remove chained nesting. In each node, only the text is used, along with filenames and alt-text of images.
The decoder sequence length is further reduced by finding the largest linearized subtree that fits within a predefined sequence length. A bounding box indicating the region covered by the chosen subtree is also drawn on the screenshot. For improved context modeling, a BART-like learning signal is introduced by masking 50% of the text and decoding the entire subtree. The masked regions are composed of randomly sampled spans of text from the selected subtree where the masks are applied.
Warming up with a reading curriculum
Images of text snippets with random colors and fonts are created. The model is simply trained to decode the original text.
Implementation
Two model variants are pretrained:
- a base model with 282M parameters including 12 encoder and 12 decoder layers with a hidden size of 768
- a large model with 1.3B parameters including 18 layers with a hidden size of 1536. Both models have the same warmup stage
Finetuning

- Captioning is the most straightforward, since the input image and the output text can be directly used. In the case where the focus of the caption is a specific bounding box (as in Widget Captioning), the target bounding box are drawn on the image itself.
- For visual question answering, while multimodal models typically reserve a specialized text channel for the question, instead the questions are rendered directly as a header at the top of the original image.
- In the case of multiple choice answers, the choices are also rendered in the header as part of the question.
- The most complex task is choosing between UI components that a natural language expression could be referring to. For each candidate, a training instance is created where the input image contains the bounding box and referring expression, and the decoding target is “true” or “false”. During training, five negative candidates are sampled per positive candidate. During inference, the candidate for which “true” is generated with the highest score is selected.
Evaluation Metrics:
- average normalized Levenshtein similarity (ANLS) for DocVQA and InfographicVQA
- exact match (EM) for AI2D, RefExp, and OCR-VQA
- relaxed accuracy (RA) for ChartQA
- CIDEr for the generation tasks.
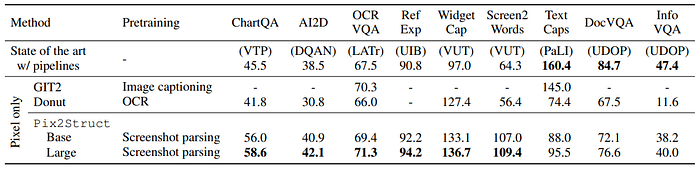
ChartQA:
- ChartQA is a VQA dataset with questions based on visual representations of tabular data.
- VisionTaPas is the current state of the art (SotA) method for ChartQA, using a pipeline approach with various encoders.
- Pix2Struct outperforms VisionTaPas significantly, improving the SotA from 45.5 to 58.6.
AI2D:
- AI2D is a dataset with multiple-choice questions based on science diagrams.
- The current SotA method, DQA-NET, focuses on modeling entity relationships using visual elements.
- Pix2Struct-Large outperforms DQA-NET and Donut by 3.6 and 11.27 points, respectively, without domain-specific modifications.
OCR-VQA:
- OCR-VQA is a dataset based on images of book covers with questions about book metadata.
- The current SotA method, GIT2, is pretrained on a large dataset and fine-tuned on various VQA datasets.
- Pix2Struct outperforms GIT2 by almost 1 point despite not using more labeled training data.
RefExp:
- RefExp involves retrieving components from app screenshots based on natural language referring expressions.
- UIBert is the current SotA method, pretrained on mobile app inputs.
- Pix2Struct substantially outperforms UIBert by 1.4 and 3.4% absolute, setting a new SotA.
Widget Captioning:
- Widget Captioning is an image captioning task for app screenshots with widget descriptions.
- VUT is the current SotA, using a specialized UI encoder.
- Pix2StructLarge improves the SotA CIDEr from 127.4 to 136.7.
Screen2Words:
- Screen2Words is an image captioning task describing the functionality of app pages.
- Pix2Struct-Large significantly improves the state of the art CIDEr from 64.3 to 109.4.
TextCaps:
- GIT2 and PaLI have advanced the state of the art on TextCaps by pretraining on image-caption pairs.
- Pix2Struct suggests that even for large-scale methods, end-to-end pixel-only performance lags behind pipeline SotA.
- Captioning may not transfer well to other domains, and screenshot parsing offers benefits with less data.
DocVQA:
- DocVQA involves questions about scanned documents.
- Pix2Struct-Large outperforms Donut, the previous visual SotA, by 9 points.
- Text-only models perform well due to the text-heavy nature of the data.
InfographicVQA:
- InfographicVQA focuses on questions about web infographics.
- Pix2Struct-Large sets the state of the art among visual models.
- Donut’s poor performance may be due to scaling images to a fixed aspect ratio.
Common Trends:
- Pix2Struct outperforms Donut in all tasks, highlighting the effectiveness of its pretraining.
- Pix2Struct advances the single-task state of the art on six of nine benchmarks across four domains.
- Scaling up from a base to a large model results in considerable improvements on all tasks, indicating the importance of batch size and training steps in pretrained models. Further scaling is promising.
Paper
Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding 2210.03347
Recommended Reading: [Document Information Processing]
Hungry for more insights?
Don’t miss out on exploring other fascinating threads in this series. Simply click here and uncover the state-of-the-art research!
Do Subscribe for weekly updates!!
