Papers Explained 252: Nemotron-Mini-Hindi

Nemotron-Mini-Hindi is a 4B bilingual SLM supporting both Hindi and English, based on Nemotron-Mini 4B. The model emphasize the importance of continued pre- training of multilingual LLMs and the use of translation-based synthetic pre-training corpora for improving LLMs in low-resource languages as it is trained using a mix of real and synthetic Hindi + English tokens, with continuous pre-training performed on 400B tokens.
The models are available on HuggingFace: Base, Instruct.
Recommended Reading [Papers Explained 208: Minitron]
Method

The adaptation experiments are conducted using the multilingual Nemotron-Mini-4B model, also known as Minitron-4B. The model undergoes continuous pre-training with an equal mixture of Hindi and English data, consisting of 200B tokens per language. The original Nemotron-4B model was primarily trained on English tokens and had seen only 20B Hindi tokens. Given the limited amount of Hindi data, adapting an existing multilingual model rather than training from scratch is an effective strategy, allowing to leverage the knowledge learned from the pre-trained model.
Synthetic Data Curation
High-quality English data sources are selected and translated into Hindi using a custom document translation pipeline. This pipeline preserves the document structure, including elements like bullet points and tables, and employs the IndicTrans2 model for sentence translation. However, since the translated data may contain noise, an n-gram language model is used to filter out low-quality samples. This model, trained on MuRIL-tokenized real Hindi data, applies perplexity scores to identify and exclude noisy translations. Around 2% of the documents were discarded post-filtering.
The translated Hindi data comprises approximately 60B tokens. The synthetic data is then combined with around 40 billion real tokens (web-scraped data) to create a dataset totaling 100B Hindi tokens. Additionally, this entire Hindi text is transliterated into Roman script, expanding the total dataset to 220B tokens. The transliterated tokens are included to enable the model to support Hinglish queries. This Hindi data is further combined with 200B English tokens for continued pre-training. Including the English dataset helps prevent catastrophic forgetting of English capabilities and contributes to training stability. Fuzzy deduplication is performed on the entire text to eliminate similar documents.
Continued Pre-training

The Nemotron-Mini-4B model is derived from the Nemotron-15B model using compression techniques such as pruning and distillation. Re-training is performed on this model using a standard causal modeling objective. This model is referred to as Nemotron-Mini-Hindi-4B, a base model where Hindi is the primary language.
Model Alignment
The first alignment stage involves Supervised Fine-Tuning (SFT). A general SFT corpus with approximately 200k examples, comprising various tasks as outlined in Nemotron-4 340B, was used. Due to the lack of a high-quality Hindi SFT corpus, English-only data was leveraged for SFT. Additionally, translated English data (filtered using back-translation-based methods) was experimented with for SFT, but no improvements were observed with this addition. The use of the English-only SFT corpus enhances instruction-following capabilities in Hindi, highlighting the cross-lingual transferability of these skills.
After the SFT stage, the model undergoes a preference-tuning phase using Direct Preference Optimisation (DPO). Approximately 200k English samples and 60k synthetic Hindi samples were used. The synthetic Hindi samples were created by translating the English samples and then filtered using back-translation methods. It was observed that incorporating synthetic Hindi samples during this stage improves the overall performance of the model. The aligned model is referred to as Nemotron-Mini-Hindi-4B-Instruct.
Evaluation
The performance of the Nemotron-Mini-Hindi-4B language model and its instruct model is evaluated on a range of benchmarks including IndicXTREME, IndicNLG, IndicQuest, and translated English benchmarks. Performance was assessed using standard metrics for each benchmark, as well as human evaluations.
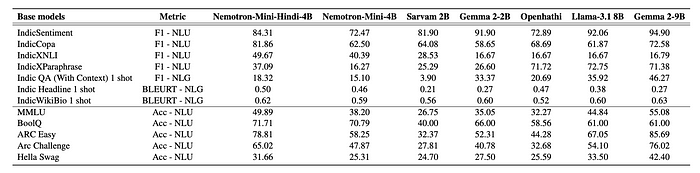

- The Nemotron-Mini-Hindi-4B Base model achieved state-of-the-art performance on most benchmarks, outperforming even larger models like Gemma-2–9B and Llama-3.1–8B on over half the benchmarks.
- Hindi-specific continued pre-training significantly improved performance on Hindi tasks.
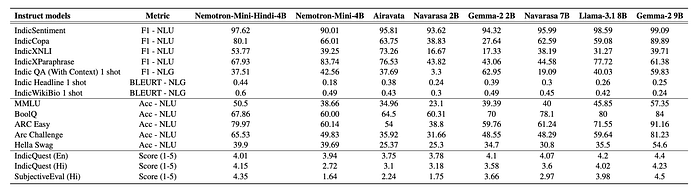
The instruct model showed improvements in both English and Hindi compared to the base model on IndicXTREME, IndicNLG, and translated English benchmarks.
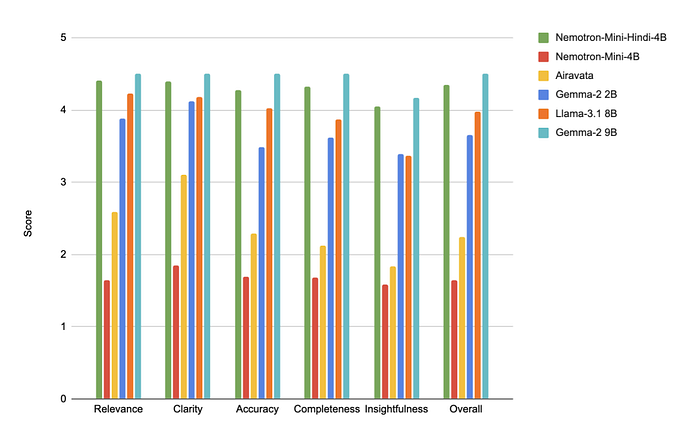
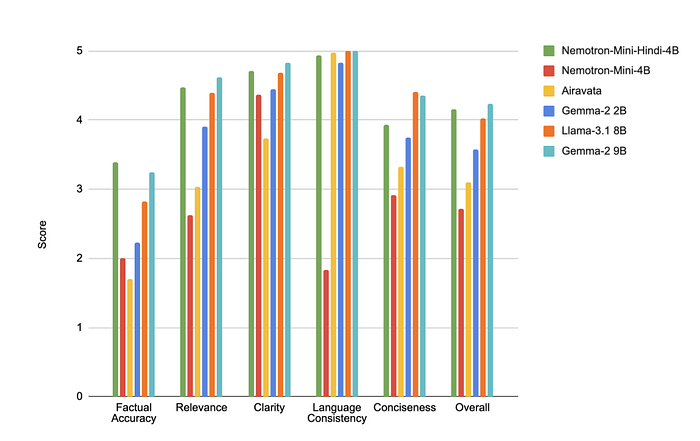
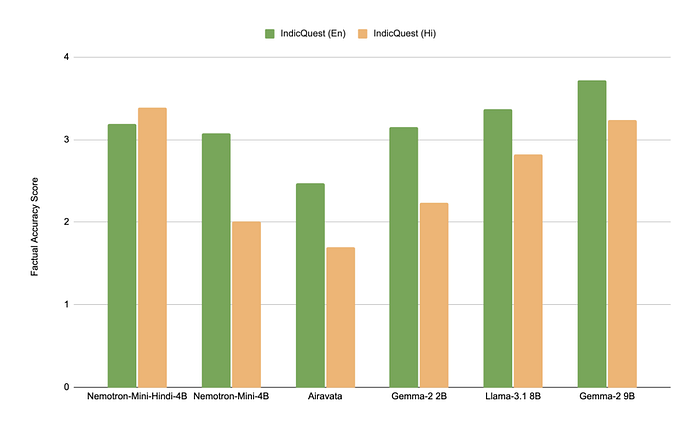
- The instruct model outperformed all baseline models except for Gemma-2–9B on IndicQuest and SubjectiveEval, demonstrating improvements in factuality and language consistency.

- Human evaluations consistently preferred responses from the Nemotron-Mini-4B-Hindi model over other models.
Paper
Adapting Multilingual LLMs to Low-Resource Languages using Continued Pre-training and Synthetic Corpus 2410.14815
Hungry for more insights?
Don’t miss out on exploring other fascinating threads in this series. Simply click here and uncover the state-of-the-art research!
Do Subscribe for weekly updates!!
