Papers Explained 248: LMDX

The main obstacles to LLM adoption in semi structured document information extraction tasks have been the absence of layout encoding within LLMs, critical for a high quality extraction, and the lack of a grounding mechanism ensuring the answer is not hallucinated. Language Model Based Document Information EXtraction and Localization (LMDX) is a methodology to adapt arbitrary LLMs for document information extraction. LMDX can do extraction of singular, repeated, and hierarchical entities, both with and without training data, while providing grounding guarantees and localizing the entities within the document.
Methodology

Optical Character Recognition
Firstly an OCR is used on the document image to obtain words and line segments, along with their corresponding spatial positions (bounding boxes) on the document.
Chunking
The document is divided into document chunks so that each is small enough to be processed by the LLM.

Prompt Generation
The prompt generation stage takes in the N document chunks and creates a LLM prompt for each of them. The prompt design contains the document representation, a description of the task, and the target schema representation containing the entities to extract. XML-like tags are used to define the start and end of each component.

Document Representation
The chunk content is represented in the prompt as the concatenation of all its segment texts, suffixed with the coordinates of those segments in the following format: < segment text > XX|YYsegment. Coordinate tokens are built by normalizing the segment’s X and Y coordinate, and quantizing them in B buckets, assigning the index of that bucket as the token for a coordinate.
In practice line level segments with 2 coordinates [x center,y center] and B=100 are used.
Task Description
The task description is simply a short explanation of the task to accomplish. In our experiments, we hard code it to the following: From the document, extract the text values and tags of the following entities:
Schema Representation
The schema is represented as a structured JSON object, where the keys are the entity types to be extracted, and the values correspond to their occurrence (single or multiple), and sub-entities (for hierarchical entities). For instance, {“foo”: “”, “bar”: [{“baz”: []}]}
Completion Targets
Like the schema, the completion is a JSON structured object with the keys being the entity types, and values being the extracted information from the document chunk. The keys in the completion have the same ordering, occurrence and class (hierarchical or leaf) as the entity types in the schema. The values of leaf entities must follow a specific format:
< text on segment1 > XX|YYsegment1 \n < text on segment2 > XX|YYsegment2 \n …
Missing entity types are completed by the model with null for singular types, and [] for repeated types.
LLM Inference
Each of the N prompts are inferred on the LLM to sample K completions using Top K sampling.
Decoding
The raw LLM completions are parsed into structured entities and their locations.
Conversion to structured entities
Each model completion is parsed as a JSON object. Completions that fail to parse are discarded. Predicted entity types that are not in the schema are discarded as well . If the model unexpectedly predicts multiple values for single occurrence entity types, the most frequent value is used as the final predicted value.
Entity Value Parsing
The JSON value is expected to include both text extractions and segment identifiers for each predicted entity. The value is first parsed into its (segment text, segment identifier) pairs. For each pair, the corresponding segment in the original document is looked up using the segment identifier, and it is verified that the extracted text is exactly included in that segment. Entity values with any segments that fail to ground in the original document are discarded.

Prediction Merging
The predicted entities for the same document chunk from the K LLM completions are first merged through majority voting. Then, the predictions among the N document chunks are merged by concatenating them to obtain the document-level predictions.
Prediction Merging for hierarchical entities
Majority voting is performed on all affiliated leaf, intermediate, and top-level entity types for each top-level hierarchical entity type among K completions, as if they are flattened. The votes are tallied with equal weight to determine which completion to use for the prediction, and the most common one is selected for that hierarchical entity.
Setup
The PaLM 2-S LLM is evaluated on LMDX methodology and is referred to as LMDXPaLM 2-S

The training process is composed of two phases
In the first phase, PaLM 2-S is fine-tuned on a data mixture containing a variety of (document, schema, extraction) tuples.In particular, this data mixture contains the Payment dataset, along with a diverse set of publicly available PDF form templates obtained from government websites that were filled with synthetic data.
The goal of this phase is to train the model to interpret the semantics of the entity types and extraction hierarchy specified in the schema, and find them within the document, along with learning the extraction syntax.
During the second phase, starting from the base entity extractor checkpoint from the previous phase, the LLM is finetuned on the target to specialize it to do high quality extraction on the target benchmark. No document or schema contained in the base extraction training phase overlap with the documents and schemas used in the specialization training phase.
Evaluation
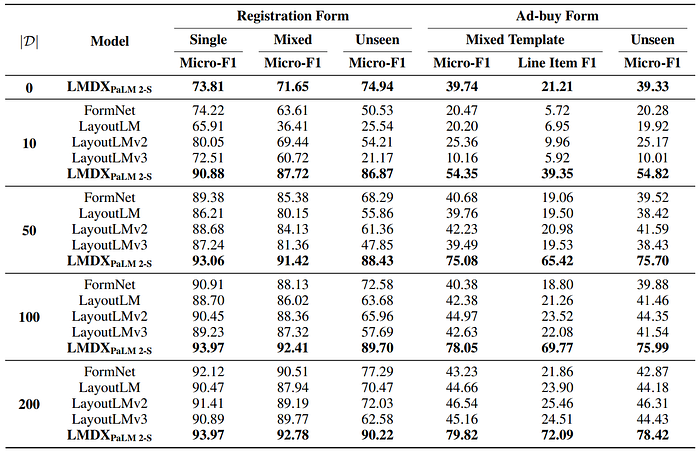
- LMDXPaLM 2-S sets a new state-of-the-art by a wide margin for VRDU data across all regimes and tasks.
- LMDXPaLM 2-S can extract information decently even with no training data, showing similar extraction quality at zero-shot as baselines with 10–100 training documents.
- For Ad-Buy Form Mixed Template, LMDXPaLM 2-S achieves a Micro-F1 score of 39.74% (vs. 40.68% for FormNet with 50 train documents) and 73.81% Micro-F1 for Registration Single Template (vs. 74.22% for FormNet with 10 train documents).
- LMDXPaLM 2-S is highly data efficient, reaching 5.06% Micro-F1 of its peak performance at 10 training documents for Registration Form Mixed Template, whereas LayoutLMv2, the strongest baseline, achieves 19.75% of its peak performance.
- LMDXPaLM 2-S generalizes better to unseen templates than baselines, with a drop of less than 5% Micro-F1 on Unseen Template compared to Single Template across all data regimes, whereas LayoutLMv2 experiences a drop between 19.38% and 27.32%.
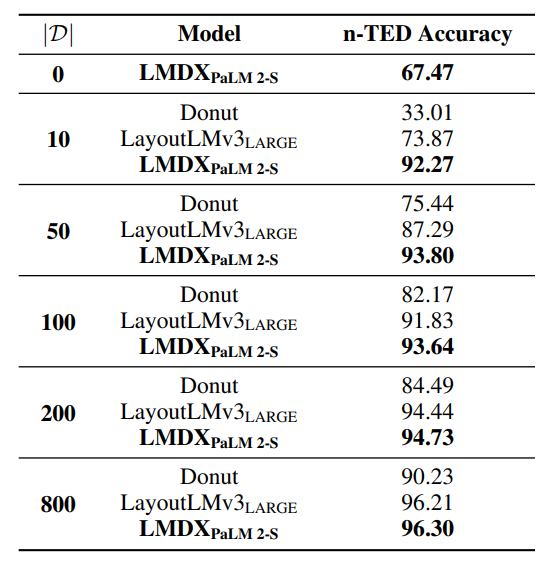
- At 10 documents, LMDXPaLM 2-S is 4.03% from its peak performance attained at 800 documents, versus 22.34% for the strongest baseline LayoutLMv3LARGE, showcasing the data efficiency of the LMDX methodology.
Performance on Hierarchical Entities
- LMDXPaLM 2-S outperforms baselines in grouping line items across all data regimes.
- At zero-shot, LMDXPaLM 2-S achieves a 21.21% F1 score in line item grouping, comparable to the best baseline’s 25.46% F1 score with 200 train documents.
- When trained with all the available data, LMDXPaLM 2-S achieves a significantly higher 72.09% F1 score in line item grouping.
- This represents a substantial 46.63% improvement over the best baseline, LayoutLMv2.
Paper
LMDX: Language Model-based Document Information Extraction and Localization 2309.10952
Recommended Reading [Document Information Processing]
Hungry for more insights?
Don’t miss out on exploring other fascinating threads in this series. Simply click here and uncover the state-of-the-art research!
Do Subscribe for weekly updates!!
