Papers Explained 243: ShieldGemma

ShieldGemma is a comprehensive suite of LLM-based safety content moderation models ranging from 2B to 27B built upon Gemma2. These models provide robust, state-of-the-art predictions of safety risks across key harm types (sexually explicit, dangerous content, harassment, hate speech) in both user input and LLM-generated output. This work also presents a novel LLM-based data curation pipeline that is adaptable to various safety-related tasks and beyond.
The models are available at HuggingFace.
Synthetic Data Curation

Synthetic data generation allows for the creation of diverse, adversarial data, while active learning minimizes the need for human annotation.
Raw Data Curation
- Problem Definition: a list of adversarial topics/subtopics in English and why this topic could be harmful, a list of generative AI use cases like email, tweet, FAQ, etc, are generated through Gemini.
- Query Generation: further diverse adversarial prompts are generated based on parameters like harm type, topic, subtopic, use case, locale, etc.
- (Optional) Response Generation: another LLM is used to generate responses based on parameters like queries, policies, whether generating adversarial or benign responses, etc.
50k examples of both user inputs and model responses each are generated which are evenly distributed into use cases, topics, harm types, etc.
Note that, the model is not guaranteed to generate violative examples and the real label would be decided by the human raters.
Data Expansion
Raw data is expanded along dimensions like difficulty and diversity using a critiquing and generation framework. 5k samples are generated for both user input and model output for semantic/synthetic diversity and difficulty, resulting in 20k samples.
The 100k synthetic raw data, 20k expanded data, and 14k Anthropic HH-RLHF are combined to form the raw data. For the Anthropic HH-RLHF data: for 50% of the data, only the first utterance is kept to mimic user input use case. For the remaining 50%, the first prompt-response pair are kept to mimic model response.
Data Sub-Sampling
Before annotating data, it’s necessary to subsample the data to reduce annotation effort, speed up iteration, and eliminate duplicate examples. This problem falls under the category of batch active learning, which involves iteratively selecting batches of data to improve classifier efficiency.
The ClusterMargin algorithm is used, which works as follows:
- Compute embeddings for the entire dataset using BERT.
- Run a clustering algorithm (e.g., Agglomerative clustering) on the embeddings to assign each data point to a cluster.
- Select the k examples with the smallest margin scores. In this case, the margin score is calculated using Gemma 1 to generate the probability of violating any policies and then taking the absolute difference between that probability and 0.5.
- Keep 10% of high-margin examples in case there are incorrect predictions on high-confidence examples.
- Run a round-robin process on the assigned clusters to further downsample the data to the desired batch size.
After labeling, these steps can be repeated iteratively to improve the model. The exercise involves downsampling the raw dataset to 15,000 examples for training and testing, with 10,500 examples reserved for training and 4,500 for testing.
Data Annotation
The data is sent to 3 raters to rate to generate a final label based on the majority vote.
The test dataset consists of:
- 2,671 benign examples
Adversarial examples for:
- Hate: 895
- Danger: 383
- Sexual harassment: 360
- Harassment: 239
Additionally, there are:
- Obscenity: 40 examples
- Violence: 70 examples
The model is trained on all six types of harm, but performance is only reported for the four targeted harms (hate, danger, sexual harassment, and harassment). The presence of 141 examples annotated with multiple harms increases the complexity of predicting harm types.
Fairness Expansion
To improve fairness of the model, counterfactual fairness expansion is used to expand the training data across identity categories like Gender, Race, Ethnicity, Sexual Orientation, and Religion.
- Ask a LLM to find any related terms like male (Gender), Japanese (Ethnicity), etc;
- If so, randomly generate another term in this identity category and ask a few-shot LLM to replace the original term with the new term while keeping the same meaning with correct grammar;
- Further send the data for human audit to remove bad examples.
Model Fine-Tuning
Gemma2 Instruction-Tuned models are fine tuned for a max sequence of 8k using the instruction

The predicted probability is calculated as
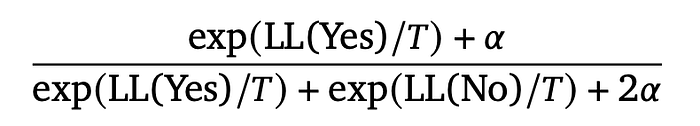
Evaluation
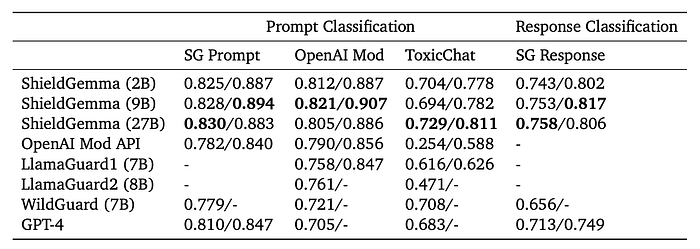
- All ShieldGemma (SG) models (2B, 9B and 27B) outperform all baseline models.
- On external benchmarks, the 9B/27B model demonstrates slightly stronger generalization capability.
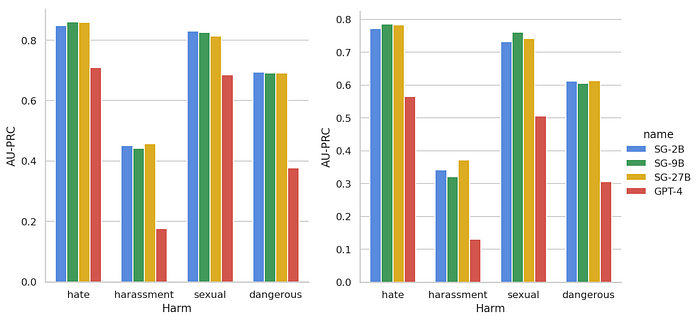
- All SG models have outperformed GPT-4 by a big margin for all of the harms.
- Note that the performance gap is expected, and the comparison is less favorable for GPT-4, as our model has been trained on datasets similar to the test datasets, while GPT-4 is evaluated zero-shot without any specific training.
- The performance among SG models is close to each other. On average, SG9B and SG-27B have outperformed SG-2B by less than 2%.
Paper
ShieldGemma: Generative AI Content Moderation Based on Gemma
Recommended Reading [Gemini / Gemma Models]
Hungry for more insights?
Don’t miss out on exploring other fascinating threads in this series. Simply click here and uncover the state-of-the-art research!
Do Subscribe for weekly updates!!
