Papers Explained 223: LLM Compiler

The LLM Compiler is a suite of pre-trained models designed for code optimization tasks, specifically for compiler intermediate representations (IRs), assembly language, and optimization techniques. The LLM Compiler is built upon Code Llama and is released in two sizes: 7B and 13B parameters. The training pipeline for LLM Compiler involves extending Code Llama with additional pretraining on a corpus of 546 billion tokens of LLVM-IR and assembly code and instruction fine-tuning to interpret compiler behavior.. Fine-tuned versions of the model demonstrate its enhanced capabilities in optimizing code size and disassembling from x86_64 and ARM assembly back into LLVM-IR, achieving 77% of the optimizing potential of an autotuning search and 45% disassembly round trip (14% exact match).

LLM Compiler: Specializing Code Llama for compiler optimization
Pretraining on assembly code and compiler IRs
LLM Compiler models are initialized with the weights of Code Llama and then trained for 401 billion tokens on a compiler centric dataset composed mostly of compiler intermediate representations and assembly code generated by LLVM version 17.0.6. These are derived from the same dataset of publicly available code used to train Code Llama. As in Code Llama, a small proportion of training batches is sourced from natural language datasets.


Instruction fine-tuning for compiler emulation

The idea is to generate from a finite set of unoptimized seed programs a large number of examples by applying randomly generated sequences of compiler optimizations to these programs. We then train the model to predict the code generated by the optimizations. The model is also trained to predict the code size after the optimizations have been applied.
The task specification involves generating the resulting code after applying optimization passes to unoptimized LLVM-IR (as emitted by the clang frontend) and a starting code size. There are two flavors: one that outputs compiler IR, and another that outputs assembly code. The input IR, optimization passes, and code size are the same for both flavors.
The model is evaluated using two metrics for code size: the number of IR instructions and binary size (computed by summing the sizes of the .TEXT and .DATA sections of the IR or assembly after lowering to an object file). Binary size excludes the .BSS section, which does not affect on-disk size.
The optimization passes used are from LLVM 17.0.6 and include transformation and analysis passes. The model selects 167 out of 346 possible pass arguments for opt, excluding non-optimization utility passes and transformations that are not semantics preserving.
To generate the compiler emulation dataset, random lists of between 1 and 50 optimization passes were applied to unoptimized programs. The length of each pass list was selected uniformly at random, and pass lists that resulted in compiler crashes or timed out after 120 seconds were excluded.
LLM Compiler FTD: Extending for downstream compiler tasks
Instruction fine-tuning for optimization flag tuning
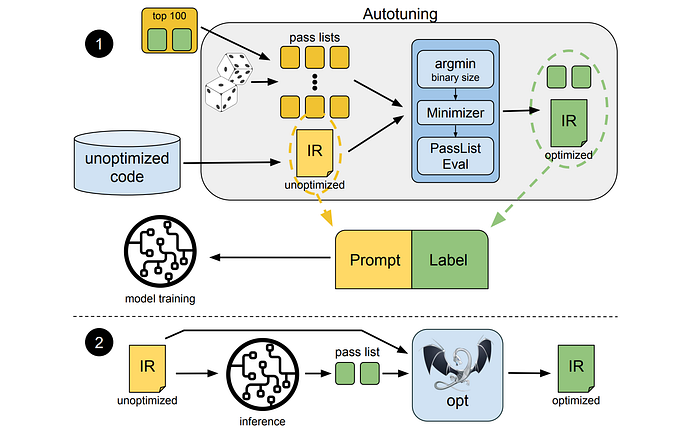
LLM Compiler FTD models are trained on the task of selecting flags for LLVM’s IR optimization tool opt to produce the smallest code size. This task has been shown to have a significant impact on both runtime performance and code size.
To generate training data, an iterative compilation process is used that involves:
1. Generating initial candidate best pass lists using large-scale random search.
2. Minimizing each pass list by eliminating redundant passes, sorting passes based on a key, and performing local search to insert new passes.
3. Applying PassListEval, a tool that evaluates candidate pass lists for correctness and crashes.
LLM Compiler FTD models are then trained on this dataset of flag tuning examples derived from 4.5M unoptimized IRs used for pretraining.
To evaluate the model’s performance, a zero-shot version of the task is used, where the model predicts flags to minimize code size of unseen programs. The model is trained and evaluated on the same constrained set of optimization passes and computes binary size in the same manner as the compiler emulation task.
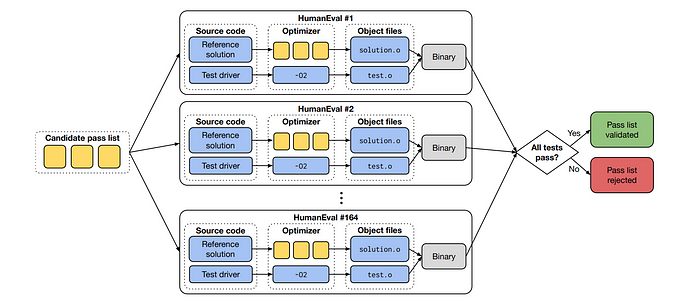
A tool is developed and referred to as PassListEval, that helps identify pass lists that break program semantics or cause compiler crashes. This tool evaluates candidate pass lists over a suite of 164 self-testing C++ programs taken from HumanEval-X.
The dataset used for training the model consists of flag tuning examples derived from 4.5M unoptimized IRs used for pretraining. The authors apply an autotuning pipeline to generate a gold standard for optimization, which requires running the compiler thousands of times.
The goal of instruction fine-tuning LLM Compiler FTD is to achieve some fraction of the performance of the autotuner without requiring running the compiler thousands of times.
Instruction fine-tuning for disassembly
The ability to lift code from assembly back into higher-level structures enables optimizations and porting of legacy code to new architectures. Machine learning techniques have been applied to decompilation tasks, such as lifting binaries into intermediate representations and proposing methods for matching binary code across different programming languages.
Researchers have trained language models to decompile x86 assembly into high-level C code. In this study, the authors demonstrate how an LLM Compiler FTD can learn the relationship between assembly code and compiler IR by fine-tuning it for disassembly.
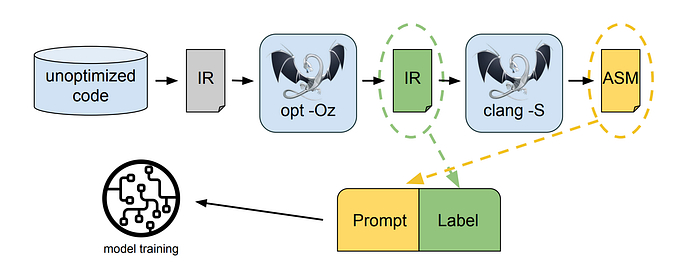
The task is to learn the inverse translation of clang -xir — -o — -S, which involves lifting assembly code into IR. However, using an LLM for disassembly can cause problems with correctness, as the lifted code must be verified manually or through test cases.
To address this issue, a lower bound on correctness can be found by round-tripping, which involves compiling the lifted IR back into assembly and verifying that it is identical to the original assembly. This provides an easy way to measure the utility of a disassembly model.
LLM is provided with assembly code and trained to emit the corresponding disassembled IR. The context length for this task is set to 8k tokens for both input assembly code and output IR.
The dataset used consists of 4.7M samples derived from the same dataset used in previous tasks. The input IR has been optimized with -Oz before being lowered to x86 assembly.
Training parameters
Data is tokenized via byte pair encoding, employing the same tokenizer as Code Llama, Llama, and Llama 2. Compared to the Code Llama base model, the context length of individual sequences is increased from 4,096 to 16,384.
Evaluation
Flag tuning task
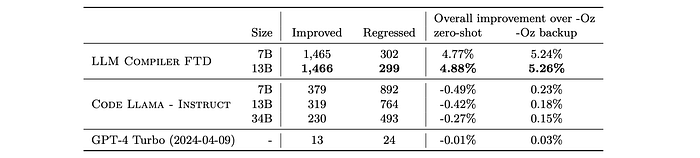
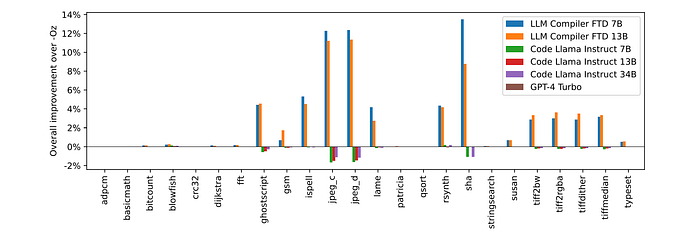
- Only LLM Compiler FTD models provide an improvement over -Oz.
- The 13B parameter LLM Compiler FTD model marginally outperforms the smaller model, generating smaller object files than -Oz in 61% of cases.
- LLM Compiler FTD 13B regresses in 12% of cases.
- Eliminating regressions by compiling twice (once with the model-generated pass list, once with -Oz) raises the overall improvement over -Oz to 5.26% for LLM Compiler FTD 13B.
- Modest improvements over -Oz are also possible for Code Llama — Instruct and GPT-4 Turbo after eliminating regressions.
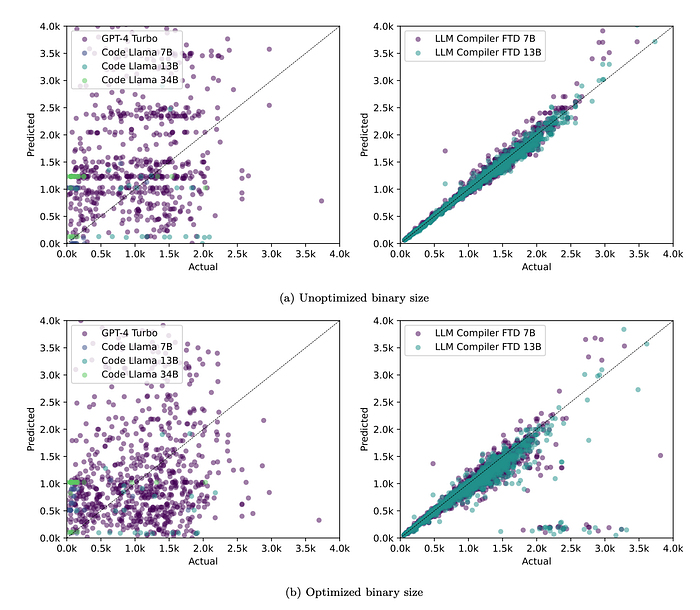
- LLM Compiler FTD binary size predictions correlate well with ground truth.
- The 7B model achieves MAPE values of 0.083 and 0.225 for unoptimized and optimized binary sizes, respectively.
- The 13B model has similar MAPE values of 0.082 and 0.225.
- Code Llama — Instruct and GPT-4 Turbo binary size predictions show little correlation with ground truth.
- LLM Compiler FTD errors are slightly higher for optimized code than unoptimized code, sometimes overestimating the effectiveness of optimization.
Disassembly task

- LLM Compiler FTD 13B achieves the highest round-trip BLEU score and most frequent perfect disassembly (round-trip exact match).
- LLM Compiler FTD 7B has a slightly higher round-trip success rate than LLM Compiler FTD 13B.
- Code Llama — Instruct and GPT-4 Turbo struggle with generating syntactically correct LLVM-IR.
Foundation model tasks
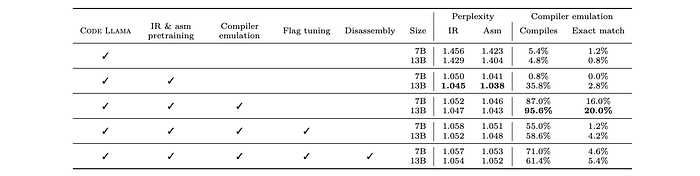
Next-token Prediction:
- Performance significantly improves after training on Code Llama (which has limited IR/assembly exposure) and slightly declines with subsequent fine-tuning stages.
Compiler Emulation:
- Code Llama base and pre-trained models perform poorly as they lack training on this task.
- Highest performance achieved immediately after compiler emulation training (95.6% IR/assembly compiles, 20% exact match).
- Performance declines after fine-tuning for flag tuning and disassembly.
Software engineering tasks
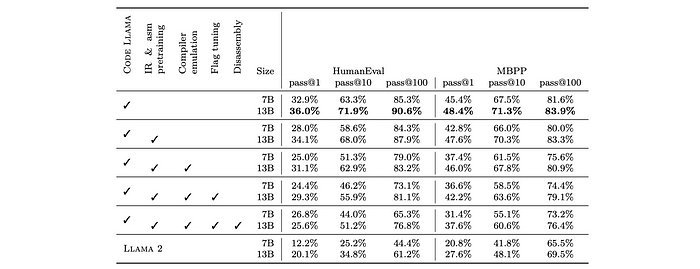
- Each stage of compiler-centric training (LLM Compiler and LLM Compiler FTD) leads to a slight decrease in Python programming ability compared to the base Code Llama model.
- Performance on HumanEval and MBPP benchmarks declined by up to 18% and 5% for LLM Compiler, and up to 29% and 22% for LLM Compiler FTD.
- Despite the decline, all models still outperform Llama 2 on both benchmarks.
Paper
Meta Large Language Model Compiler: Foundation Models of Compiler Optimization 2407.02524
Hungry for more insights?
Don’t miss out on exploring other fascinating threads in this series. Simply click here and uncover the state-of-the-art research!
Do Subscribe for weekly updates!!
