Papers Explained 208: Minitron

The study investigates whether pruning an existing Large Language Model (LLM) and re-training it with a fraction of the original training data can be a suitable alternative to repeated, full retraining. They develop a set of compression best practices for LLMs that combine depth, width, attention, and MLP pruning with knowledge distillation-based retraining.
Using this approach, the Nemotron-4 family of LLMs is compressed by a factor of 2–4×, resulting in compute cost savings of 1.8× for training the full model family (15B, 8B, and 4B). The compressed models, called Minitron, exhibit up to a 16% improvement in MMLU scores compared to training from scratch.
The models are available at HuggingFace and the project is available at GitHub.
Recommended Reading [Papers Explained 206: Nemotron-4 15B]
Pruning Methodology

Importance Analysis
A purely activation-based importance estimation strategy is proposed that simultaneously computes sensitivity information for all the axes (depth, neuron, head, and embedding channel) using a small (1024 samples) calibration dataset and only forward propagation passes:
Width:
The importance of each head, neuron and embedding channel is computed by activation-based importance scores on the calibration dataset D:

Depth:
The importance of each layer is evaluated using two metrics:
Perplexity (PPL): simply remove a single layer and compute its effect on perplexity of this pruned model
Block Importance (BI): serves as the “importance” or sensitivity of the layer using the cosine distance between the input and output of a layer.

Iterative Importance
Pruning and importance estimation are iteratively alternated for a given axis or combination of axes. Given number of iterations T and source and target dimensions (layers, heads, etc.) ds and dt, respectively, importance is computed on ds − i · (ds −dt)/T dimensions and pruning to ds − (i + 1) · (ds −dt)/T dimensions; i ∈ [0, T − 1].
Obtaining a Pruned Model
For a given architecture configuration, the elements of each axis are ranked according to the computed importance and then trimmed (reshaped) directly in the corresponding weight matrices.
For neuron and head pruning, MLP and MHA layer weights are trimmed, respectively. In the case of embedding channels, the embedding dimension of the weight matrices in MLP, MHA, and LayerNorm layers are trimmed.

Given a search space and parameter budget (left side of the figure), all feasible architectures meeting the parameter budget by sticking are enumerated to commonly used neuron, head and embedding dimensions. The feasible candidates then undergo lightweight retraining (∼1.8B tokens).
Retraining
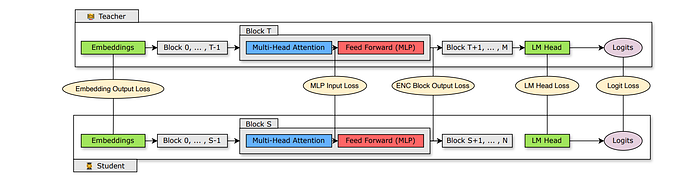
Retraining refers to the accuracy recovery process following pruning. A combination of Conventional training with ground truth labels and knowledge distillation (KD) using supervision from an unpruned model (teacher) is used for retraining.
The output probability distribution of an LLM for a given token xi is computed as:
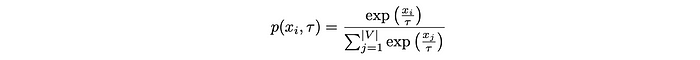
Logit-based KD loss across the sequence of all output tokens is represented as
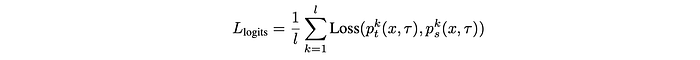
Various loss functions and combinations of intermediate states and mappings across the Transformer model are explored for distillation, along with their respective trade-offs.
The intermediate state-based KD loss across a sequence of Transformer-specific hidden states is represented as
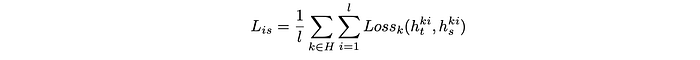
The mismatch in student and teacher hidden states is handled by learning a shared linear transformation during distillation to upscale the student hidden state to the teacher hidden state dimension.
The total loss L is computed as L = LCLM + Llogits + α × Lis; where LCLM is the student cross entropy loss against the ground truth labels, and α is a weighting coefficient.
Experiment Setup
The Nemotron-4 model with 15.6B parameters is compressed to two target parameter ranges: 8B and 4B.
The retraining process used the Nemotron-4 curated dataset, consisting of: 8T tokens, For lightweight retraining, 1.8 billion tokens are used. A calibration dataset D is created for importance estimation, consisting of 1024 random samples drawn from the full dataset.

Structured Compression Best Practices
1. To train a family of LLMs, train the largest one and prune+distill iteratively to smaller LLMs.
2. Use (batch=L2, seq=mean) importance estimation for width axes and PPL/BI for depth.
3. Use single-shot importance estimation; iterative provides no benefit.
4. Prefer width pruning over depth for the model scales we consider (≤ 15B).
5. Retrain exclusively with distillation loss using KLD instead of conventional training.
6. Use (logit+intermediate state+embedding) distillation when depth is reduced significantly.
7. Use logit-only distillation when depth isn’t reduced significantly.
8. Prune a model closest to the target size.
9. Perform lightweight retraining to stabilize the rankings of searched pruned candidates.
10. If the largest model is trained using a multi-phase training strategy, it is best to prune and retrain the model obtained from the final stage of training.
Results
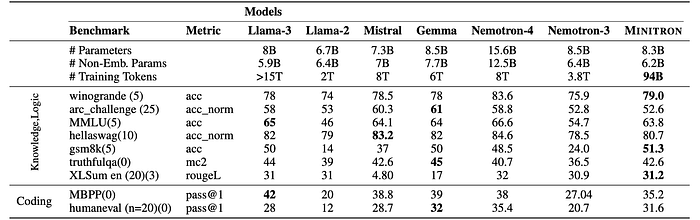
Minitron 8B outperforms Nemotron-3 8B and LLaMa-2 7B, and performs similarly to Mistral 7B, Gemma 7B, and LLaMa-3 8B, while using significantly fewer training tokens.
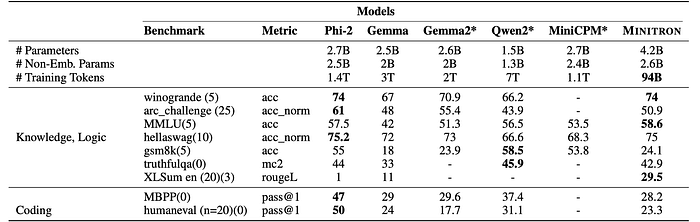
Minitron 4B retains model capabilities better than smaller specialized models and outperforms Gemma2.
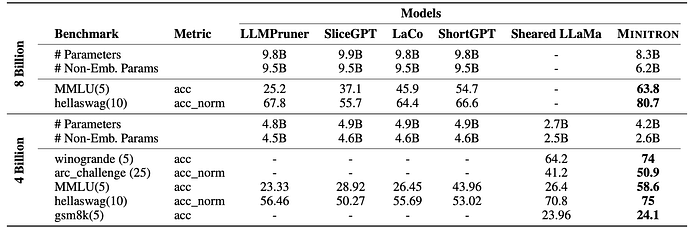
Minitron 8B significantly outperforms multiple depth-pruned models of larger size (∼ 10B parameters).
Paper
Compact Language Models via Pruning and Knowledge Distillation 2407.14679
Hungry for more insights?
Don’t miss out on exploring other fascinating threads in this series. Simply click here and uncover the state-of-the-art research!
Do Subscribe for weekly updates!!
