Papers Explained 198: ColPali

ColPali leverages the document understanding capabilities of recent Vision Language Models to produce high-quality contextualized embeddings solely from images of document pages. Combined with a late interaction matching mechanism, ColPali largely outperforms modern document retrieval pipelines while being drastically faster and end-to-end trainable.
To benchmark current systems on visually rich document retrieval, the study introduces the Visual Document Retrieval Benchmark ViDoRe, composed of various page-level retrieving tasks spanning multiple domains, languages, and settings.
The project artifacts are available at HuggingFace.
Recommended Reading [Papers Explained 88: ColBERT] [Papers Explained 197: Pali Gemma]
The ViDoRe Benchmark

Widely used visual question-answering benchmarks are repurposed for retrieval tasks: using question as the query, and the associated page as the gold document.
Moreover, TabFQuAD, a human-labeled dataset on tables extracted from French industrial PDF documents is also used.
Topic-specific retrieval benchmarks that cover multiple domains are created to go beyond using repurposed QA datasets. Publicly accessible PDF documents are collected and queries related to each document page are generated using Claude-3 Sonnet. 1,000 document pages per topic are collected and associated with 100 queries that have been extensively filtered for quality and relevance by human annotators.
Evaluation Metrics
Efficient document retrieval systems exhibit joint properties of high retrieval performance (R1), low latency during querying (R2), and high throughput during indexation (R3).
To evaluate performance on the benchmark (R1) standard metrics from the retrieval literature: NDCG, Recall@K, MRR are used. Specifically,NDCG@5. To validate compliance with practical industrial constraints, query latencies (R2) and indexing throughputs (R3) are also considered.
ColPali

The key concept is to leverage the alignment between output embeddings of text and image tokens acquired during multimodal finetuning.To this extent, ColPali is a Paligemma-3B extension that is capable of generating ColBERT-style multi-vector representations of text and images.
A projection layer is added to map the output language modeling embeddings to a vector space of reduced dimension D = 128 as used in the ColBERT to keep lightweight bag-of-embedding representations.
Late Interaction
Given query q and document d, Eq and Ed denote their respective multi-vector representation in the common embedding space.
The late interaction operator, LI (q, d), is the sum over all query vectors Ed(j), of its maximum dot product ⟨·|·⟩ with each of the Nd document embedding vectors Ed(1:Nd).

Contrastive Loss
Following ColBERT the in-batch contrastive loss L is defined as the softmaxed cross-entropy of the positive scores w.r.t. the maximal negative scores.
Dataset
The training dataset of 127,460 fully english query — page pairs is comprised of train sets of openly available academic datasets (63%) and a synthetic dataset made up of pages from web-crawled PDF documents and augmented with VLM-generated (Claude-3 Sonnet) pseudo-questions (37%).
Parameters
All models are trained for 1 epoch on the train set in bfloat16 format, using LoRA, with α = 32 and r = 32 on the transformer layers from the language model, as well as the final randomly initialized projection layer.
Query Augmentation
As in ColBERT, 5 <unused0> are appended tokens to the query tokens to serve as a soft, differentiable query expansion or re-weighting mechanism.
Evaluation
Performance (R1)
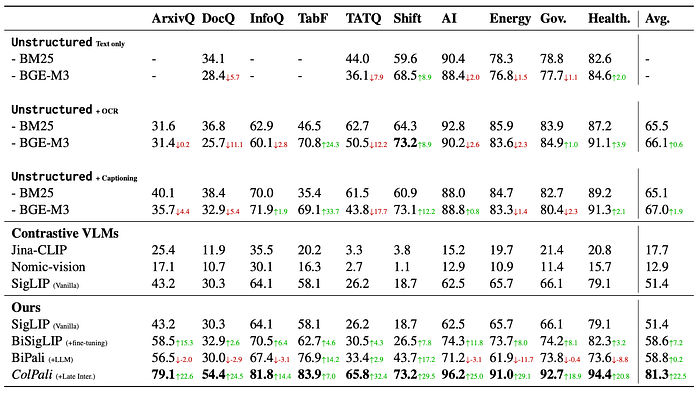
- Started with an off-the-shelf SigLIP model pretrained on the English split of WebLI, a large corpus of image-text pairs.
- Fine-tuned the textual component of SigLIP on a document-oriented dataset to improve performance on document retrieval tasks (BiSigLip).
- Integrated SigLIP with a language model (PaliGemma) to create BiPali, and then fine-tuned it on the training dataset.
- SigLIP outperformed Jina CLIP and Nomic-vision on document retrieval tasks, particularly in English.
- BiSigLip showed clear improvements over SigLIP on figure and table retrieval tasks (ArxivQA and TabFQuAD).
- BiPali performed slightly worse in English than the fine-tuned BiSigLIP variant but significantly better in French tasks, indicating the benefits of the LLM (Gemma 2B) for multilingual text understanding.
- ColPali outperformed strong baselines and all evaluated text-image embedding models across various benchmarks, including InfographicVQA, ArxivQA, and TabFQuAD.
- Text-centric documents were better retrieved by ColPali models across all domains and languages.
Online Querying (R2)
- ColPali’s language model took approximately 30 ms to encode a query with 15 tokens, while BGE-M3 encoding took about 22 ms under similar conditions.
- For smaller corpus sizes, the late interaction operation introduced only marginal overhead (≈ 1 ms per 1000 pages).
- The cosine similarity computation between bi-encoder vectors was found to be very fast and did not significantly contribute to the overall latency.
- Optimized late interaction engines were effective in scaling corpus sizes to millions of documents with minimal latency degradation.
Offline Indexing (R3)
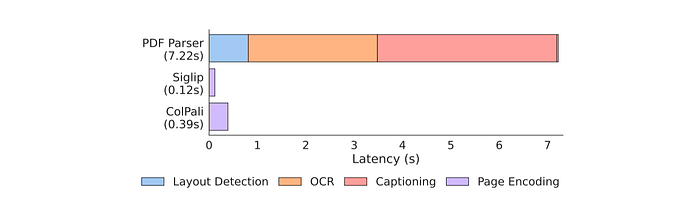
- ColPali achieves significant speedups in indexing compared to standard retrieval methods.
- Although the encoder model is larger than standard retrieval encoders, skipping the preprocessing allows large speedups at indexing.
Paper
ColPali: Efficient Document Retrieval with Vision Language Models 2407.01449
Recommended Reading [Retrieval and Representation Learning]
Hungry for more insights?
Don’t miss out on exploring other fascinating threads in this series. Simply click here and uncover the state-of-the-art research!
Do Subscribe for weekly updates!!
