Papers Explained 196: PaLI-3

PaLI-3 is a 5B vision language model that outperforms larger models on various benchmarks. It uses a multilingual contrastive vision model scaled to 2B parameters, obtained using the SigLIP recipe. Despite not pretraining on any video data, PaLI-3 achieves new SOTA on several video QA benchmarks, indicating powerful generalization abilities.
Recommended Reading [Papers Explained 152: SigLip] [Papers Explained 194: PaLI]
Model Architecture

On a high level, the architecture follows PaLI-X: ViT encodes the image into tokens which, together with text input (the question, prompt, instruction), are passed to an encoder-decoder transformer that generates a text output.
Visual component
The vision backbone of PaLI-3 is initialized from a contrastively pretrained ViT-G/142 model (approx. 2B parameters) using the SigLIP training recipe.
In brief, an image embedding ViT-G/14 and a text embedding transformer are trained to separately embed images and texts, such that a binary classifier using the sigmoid crossentropy of the dot product of image and text embeddings correctly classifies whether the respective image and text correspond to each other or not.
Full PaLI model
The outputs of the ViT image encoder before pooling form the visual tokens, which are linearly projected and prepended to the embedded input text tokens. Together, these tokens are passed into a pretrained 3B parameter UL2 encoder-decoder language model, which generates text output.
Training
The training procedure is similar to that of PaLI and PaLI-X and consists of multiple stages:
Stage 0: Unimodal pretraining: The image encoder is pretrained contrastively on image-text pairs from the web, following the SigLIP training protocol. This differs from PaLI and PaLI-X, where a JFT classification pretrained encoder was used.The text encoder-decoder is a 3B UL2 model.
Stage 1: Multimodal Training
The combined PaLI model is trained on a multimodal task and data mixture, albeit keeping the image encoder frozen and using its native (224×224) resolution. The main mixture component is again derived from the WebLI dataset by heuristic filtering of the text quality and using the SplitCap training objective. Further ingredients are multilingual captioning on CC3M-35L and WebLI OCR, cross-lingual VQA and VQG using VQ2A-CC3M-35L, object-aware VQA, as well as object detection.
Notably, no task or data derived from video are included.
Document and text understanding capabilities are further improved by enriching WebLI with PDF documents with dense text and web-images described as posters or documents, in over 100 languages.
Stage 2: Resolution Increase
PaLI-3’s resolution is increased by fine-tuning the whole model (unfreezing the image encoder) with a short curriculum of increasing resolutions, keeping checkpoints at 812×812 and 1064×1064 resolution. The data mixture focuses on the part that involves visually-situated text and object detection.
Task specialization
Finally, for each individual task (benchmark), the PaLI-3 model is finetuned with frozen ViT image encoder on the task’s training data. For most tasks, the 812×812 resolution checkpoint is fine tuned, but for two document understanding tasks, 1064×1064 resolution checkpoint is used.
Evaluation
Classification Or Contrastively Pretrained ViT?
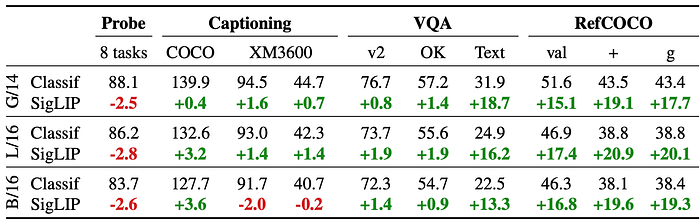
- SigLIP models, initially performing worse in few-shot linear classification, showed moderate improvements in simpler tasks like captioning and question-answering.
- SigLIP models demonstrated large gains in more complex tasks such as TextVQA and RefCOCO variants, indicating their superiority in these areas.
Visually Situated Text Understanding
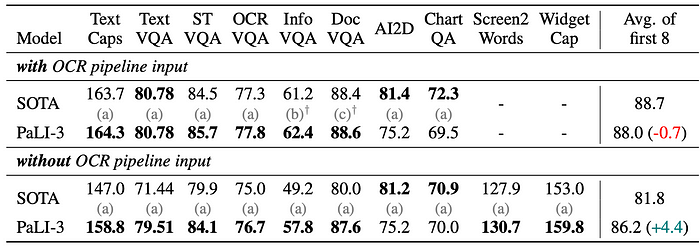
- PaLI-3 achieves SOTA performance on a majority of captioning and VQA benchmarks with and without external OCR input.
- Performance is slightly lower on AI2D and ChartQA benchmarks, which require advanced reasoning capabilities, compared to PaLI-X .
- When using external OCR systems, PaLI-3 is only 0.7 points behind all SOTA methods combined across 8 benchmarks.
- Without external OCR systems, PaLI-3 outperforms all SOTA methods by 4.4 points overall and by 8 points or more on specific benchmarks like TextCaps, TextVQA, InfographicVQA, and DocVQA.
- PaLI-3 without external OCR is only 1.8 points behind when using such systems, indicating a strong intrinsic OCR capability.
Referring Expression Segmentation

- Contrastive pretraining significantly outperforms classification pretraining for localization tasks.
- The full PaLI-3 model achieves slightly better performance than the current state-of-the-art in referring expression segmentation.
Natural Image Understanding
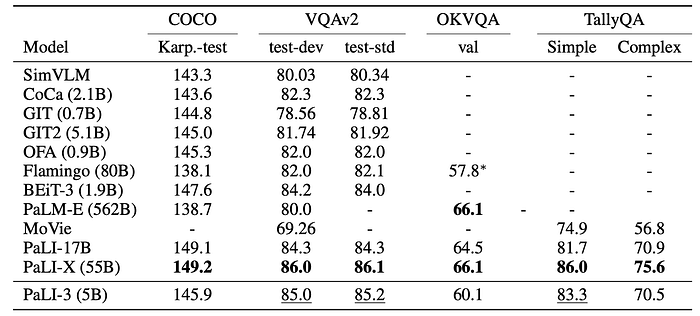
- Strong Performance: PaLI-3 demonstrates very strong performance on all benchmarks despite being significantly smaller than state-of-the-art (SOTA) models.
- COCO Captions: PaLI-3 outperforms all models except BEiT-3 and the 17B and 55B PaLI models.
- VQAv2 & TallyQA: PaLI-3 surpasses all previous models except PaLI-X, with a small gap (less than 1 point) on VQAv2.
- OKVQA: PaLI-3 is only behind PaLM-E (562B) and PaLI-X (55B) but outperforms the 32-shot Flamingo (80B) model.
Video Captioning and Question Answering

- PaLI-3 achieves state-of-the-art (SOTA) performance on MSR-VTT-QA and ActivityNet-QA benchmarks.
- It shows competitive results on the NExT-QA benchmark.
- PaLI-3 performs respectably on video captioning tasks, lagging behind the SOTA by only 3 CIDEr points on average.
- The model’s strong performance in both image and video QA tasks demonstrates the benefits of contrastive ViTs.
- Due to its size and performance, PaLI-3 is presented as a practical and effective choice for video understanding tasks.
Direct Image Encoder Evaluation
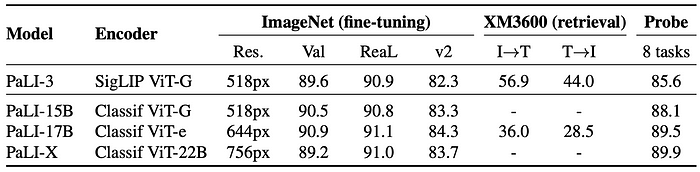
- Image Classification: SigLIP slightly lags behind classification-pretrained ViTs in top-1 and v2 accuracy on ImageNet but matches in ReaL accuracy, suggesting better generalization.
- Multilingual Image-Text Retrieval: SigLIP ViT-G model significantly outperforms the classification-pretrained larger ViT-e model.
- Linear Probing: SigLIP lags behind in few-shot classification tasks, likely due to the representation not being pretrained for linear separability.
- Overall: While classification-pretrained image encoders perform slightly better on standard classification tasks, SigLIP pretrained encoders are significantly better for vision-language tasks.
Paper
PaLI-X: On Scaling up a Multilingual Vision and Language Model 2305.18565
Recommended Reading [Multi Modal Transformers]
Hungry for more insights?
Don’t miss out on exploring other fascinating threads in this series. Simply click here and uncover the state-of-the-art research!
Do Subscribe for weekly updates!!
