Papers Explained 195: PaLI-X

This work focuses on scaling a Vision-Language model to achieve outstanding performance on a wide variety of benchmarks. PaLI-X is a multilingual vision and language model consisting of a large-capacity visual encoder and a language-only encoder-decoder, both pre trained and further trained at-scale on a vision-and-language data mixture using self-supervision and full-supervision signals that achieves state-of-the-art (SoTA) results on 25+ benchmarks.
Recommended Reading [Papers Explained 194: PaLI]
Model Architecture

The PaLI-X model architecture follows the encoder-decoder architecture: image(s) are processed by a ViT encoder, with the resulting visual embeddings fed to an encoder-decoder backbone, along with embeddings from additional text input (e.g., question / prefix / prompt).
Vision Model
The visual backbone is scaled to 22B parameters, To equip the model with a variety of complex vision-language tasks, an OCR-based pre training is incorporated as follows: images from the WebLI dataset are annotated with OCR-text detected by GCP Vision API; the encoder is then further pre-trained with a mixture of the original JFT-based classification task and a new OCR-based classification task (whether or not a given token occurred in the image according to OCR results).
PaLI-X is designed to take n >= 1 images as inputs (for few-shot and video understanding)
Language Model
The encoder-decoder backbone is initialized from a variant of the UL2 encoder decoder model that uses 32B parameters.
Overall Model
The visual embeddings, after going through a projection layer, are concatenated with the token embeddings of the text input, and fed to the encoder-decoder backbone.
Few-shot formulation

PaLI-X processes few shot input as follows: all images, including the target one, are first independently processed by the visual encoder, and the resulting patch-level embeddings are flattened and concatenated to form the visual input sequence. After going through a projection layer, they are concatenated with the text embeddings to form the multimodal input sequence used by the encoder.
Pre Training Data
The pretraining mixture consists of the following data and objectives:
- Span corruption on text-only data (15% of tokens)
- Split-captioning on WebLI alt-text data
- Captioning on CC3M native and translated alt-text data (35 languages)
- Split-OCR on WebLI OCR annotations
- Visual-question-answering objective over image, question, answer pairs generated using VQ2A method (CC3M training split, 35 language pairs)
- Visual-question-generation objective using the same pairs as above
- Visual-question-answering objective over image, question, answer pairs using Object-Aware method (English only)
- Captioning on Episodic WebLI examples (target alt-text predicted from remaining alt-text and images)
- Visual-question-answering on 4-pair examples (resembling Episodic WebLI, using VQ2A-CC3M pairs), with answer target conditioned on other pairs of image, question, answer data
- Pix2struct objective targeting page layout and structure using screenshot images paired with DOM-tree representations of html pages
- Captioning on short video data using VTP data (four frames per video)
- Object-detection objective on WebLI data using OWL-ViT model (L/14) to annotate WebLI images, resulting in hundreds of pseudo object labels and bounding boxes per image
- Image-token prediction objective tokenizing WebLI images (256x256 resolution) using ViT-VQGAN model with patch size 16x16 (256 tokens per image), framed as a 2D masked-token task
Training Stages
The model is trained in two stages.
- The visual encoder (after mixed-objective training) is kept frozen, while the rest of the parameters are trained on a total of 2.2B examples at the base resolution 224×224 (native to ViT-22B), using the entire mixture.
- It continues training using only the OCR-related objectives (pix2struct and split-ocr) plus the object detection objective; this is done in several substages, during which image resolution is gradually increased to 448×448, 672×672 and finally 756×756.
Evaluation
Image Captioning and Visual Question Answering
Per-task fine-tuning results
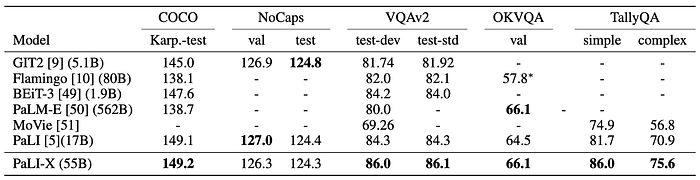
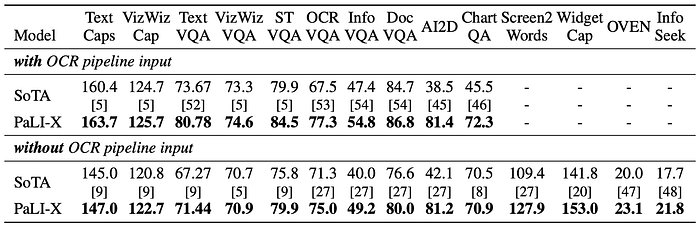
- Scale Advantage: PaLI-X’s larger capacity demonstrates significant benefits for challenging scene-text and document understanding tasks.
- Superior Performance: PaLI-X outperforms state-of-the-art models on diverse vision-language tasks, achieving substantial margins in some cases.
Multitask Fine-tuning
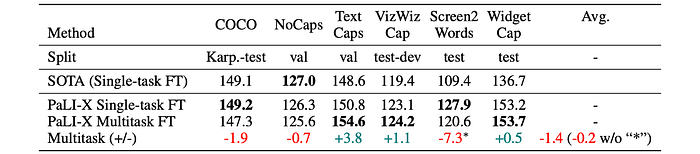
- PaLI-X achieves on-par performance with single-task fine-tuning across multiple benchmarks, demonstrating the effectiveness of multitask learning.
Few-shot Evaluation

- PaLI-X excels in few-shot learning, achieving SOTA results on COCO captioning with both 4 and 32 shots, and demonstrating strong multilingual capabilities on XM3600.
Video Captioning and Question Answering
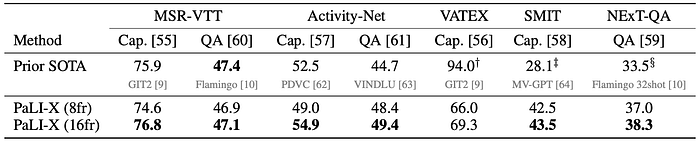
- The 16-frames version of the model outperformed the 8-frame version in most cases, with a significant margin in some instances (e.g., a 6 point increase in CIDEr score for ActivityNet Captions).
- PaLI-X achieved new SOTA performance for 5 out of 7 tasks, and performed very close to prior SOTA on MSR-VTT-QA.
Image classification

- PaLI-X achieved state-of-the-art (SOTA) performance for generative models on ImageNet and comparable or superior performance on out-of-distribution datasets compared to the current SOTA generative model with an open vocabulary, GIT2, which was fine-tuned at a 384 image resolution.
Object Detection

- The detection-tuned model achieved a mean Average Precision (mAP) of 31 on the LVIS dataset, with a higher mAP of 31.4 specifically on rare classes.
- In zero-shot evaluation, the model obtained an mAP of approximately 12 for both common and rare classes on the LVIS dataset.
- The model demonstrated comparable performance on rare classes as on common classes, which traditionally required complex sampling schedules and augmentations. This was attributed to the diverse training mix provided by PaLI-X.
Paper
PaLI-X: On Scaling up a Multilingual Vision and Language Model 2305.18565
Recommended Reading [Multi Modal Transformers]
Hungry for more insights?
Don’t miss out on exploring other fascinating threads in this series. Simply click here and uncover the state-of-the-art research!
Do Subscribe for weekly updates!!
