Papers Explained 189: Proofread

Proofread is a novel feature in Gboard that uses a server-side Large Language Model (LLM) to provide seamless sentence-level and paragraph-level corrections with a single tap, alleviating the pain points of fast typers who prefer to focus on typing rather than checking committed words.
The system behind Proofread consists of four parts: data generation, metrics design, model tuning, and model serving.
- The data generation process involves a carefully designed error synthetic framework that simulates user input and ensures the data distribution is close to the Gboard domain.
- The metrics designed to measure the model’s quality include grammar error existence check and same meaning check based on LLMs.
- The model tuning process involves Supervised Fine-tuning followed by Reinforcement Learning (RL) tuning, inspired by InstructGPT. The results show that the rewrite task tuning and RL tuning recipe significantly improves the proofreading performance of the foundation models.
- To reduce serving cost, the feature is built on top of the medium-sized LLM PaLM2-XS, which can be fit into a single TPU v5 after 8-bit quantization. The latency is further optimized with bucket keys, segmentation, and speculative decoding.

Datasets
Each item in the dataset consists of a source sentence with several possible reference sentences. The dataset preparation process involves the following steps:
Sampling data from a web crawled dataset and processing it with a Grammar Error Correction (GEC) model to fix grammar errors.
Synthesizing grammar errors into the source sentence to simulate real-world user inputs, including:
- Character omission (e.g., “hello” as “hllo”)
- Character insertion (e.g., “hello” as “hpello”)
- Transposition (e.g., “hello” as “hlelo”)
- Double tap (e.g., “hello” as “heello”)
- Omit double characters (e.g., “hello” as “helo”)
- Gaussian-based positional errors (e.g., “hello” as “jello”)
Passing the data with synthetic errors to the Gboard simulator to fix errors using Gboard’s built-in literal decoding, Active key correction (KC), and active auto correction (AC) functions. Additionally, heuristic rules are applied to fix cases such as:
- Emoji/emoticons alignment
- Date time formatting
- URL patterns
Filtering out noise data using a Large Language Model (LLM) with carefully designed instructions to avoid polluting the model. The data is diagnosed based on various dimensions, including:
- Reference sentence still has errors remaining
- Reference sentence is not fluent or clear enough
- Reference sentence has a different meaning than the source sentence
- Reference sentence has a different tone, aspect, or tense than the source sentence
Using part of the examples labeled by human raters as a golden set for evaluation.

Metrics
Given the three elements, input (corrupted text), answer(predicted candidate from the model) and target(ground truth), we present the following metrics.
- EM / Exact Match Ratio: ratio of answer equal to target exactly.
- NEM / Normalized Exact Match Ratio : ratio of answer equal to target ignoring capitalization and punctuation.
- Error Ratio: ratio of answer containing grammar errors, which is conducted by LLM with specific instruction.
- Diff Meaning Ratio: ratio of answer and target don’t have the same meaning, which is also conducted by LLM with specific instruction.
- Good Ratio: ratio of answer without grammar error and has the same meaning with target.
- Bad Ratio: ratio of answer either have grammar error or has different meaning with target.
Model Tuning
The model tuning process starts with the PaLM2-XS model
The initial step is to fine-tune the model on the Rewrite dataset containing hundreds of text rewriting tasks. Next, the models are fine-tuned on a synthetic dataset. RLAIF is used, along with heuristic rewards. Two alternative heuristic rewards based on Large Language Models (LLM) are designed:
1. Global Reward: The LLM is used to determine whether a candidate is a good fix of corrupted inputs, using few-shot examples.
2. Direct Reward: The goal is to improve the Good Ratio, so the rewards are directly converted from grammar error checks and diff meaning checks, both relying on LLM. The ground truth is included in the example, and the rewards are combined as the final reward.
To optimize the model, Proximal Policy Optimization (PPO) is used, which involves KL divergence to help the model retain the ability to recover the original text.
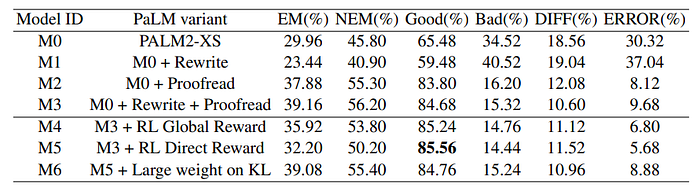
- [Comparing M2 and M3] Though fine-tuning on Rewrite dataset degrades the quality, sequential fine-tuning on Rewrite and Proofread datasets yields the best results with Good ratio 84.68% and Bad ratio 15.32%.
- [Comparing M3, M4 and M5] The Bad ratio of PaLm2-XS model could be improved by 0.56% and 0.88% relatively through applying the RL with Global Reward and RL with Direct Reward respectively.
- [Comparing M5 and M6] RL reduces the EM and NEM ratios, indicating a shift in the output distribution for both correct and incorrect cases. While increasing the KL divergence penalty can mitigate this, it doesn’t significantly improve the Good/Bad ratios.
Model Serving
The Proofread model is served using Google’s TPUv5e chip, which has 16GB HBM and 8-bit quantization to reduce memory footprint and latency without compromising quality. The model is designed for deployment in chat applications, where the average sentence length is typically short (less than 20 words). To handle longer documents, the model segments the document into paragraphs and processes them in parallel.
The methodology also incorporates speculative decoding and heuristic drafter models that are tailored to user history patterns. The initial input is processed using the speculative draft, and external drafter models are used as needed. This approach reduces operational costs and improves efficiency.
The system has been empirically evaluated, and a 39.4% reduction in median latency per serving request has been recorded, measured in TPU cycles. This highlights the efficiency of the system in real-time applications.
Paper
Proofread: Fixes All Errors with One Tap 2406.04523
Hungry for more insights?
Don’t miss out on exploring other fascinating threads in this series. Simply click here and uncover the state-of-the-art research!
Do Subscribe for weekly updates!!
