Papers Explained 187c: Llama 3.1 — Multimodal Experiments

Llama 3 is a new set of foundation models, designed for multilinguality, coding, reasoning, and tool usage. The largest model boasts 405B parameters and a 128K token context window performing comparably to leading models like GPT-4 across various tasks. And smaller models outperforming alternatives of similar size.
This article covers experiments of adding multimodal capabilities to Llama3.
Refer the Part A of this article to read about the models released in April 2024: [Papers Explained 187a: Llama 3]
Refer the Part B of this article to read about the models released in July 2024: [Papers Explained 187b: Llama 3.1]
Vision Experiments of Llama 3.1

Visual recognition capabilities are incorporated into Llama 3 via a compositional approach. First, a pre-trained image encoder and the pre-trained language model are composed by introducing and training a set of cross-attention layers between the two models on a large number of image-text pairs. Then, temporal aggregator layers and additional video cross-attention layers are introduced that operate on a large collection of video-text pairs to learn the model to recognize and process temporal information from videos.
Pre Training Data
The dataset construction involves four main stages:
- Quality Filtering: Non-English captions and low-quality captions are removed using heuristics such as CLIP scores.
- Perceptual Deduplication: To reduce training compute spent on redundant data and memorization, an internal version of the SSCD copy-detection model is used to de-duplicate images at scale. The duplicates are grouped using a connected-components algorithm and only one image-text pair per component is kept.
- Resampling: Diversity of image-text pairs is ensured via resampling. A vocabulary of n-grams is constructed by parsing high-quality text sources. The frequency of each vocabulary n-gram in the dataset is computed and the data is resampled based on the frequency of n-grams.
- Optical Character Recognition: Text written in the image is extracted using a proprietary OCR pipeline and concatenated with the caption..
To improve performance on document understanding tasks:
- Documents are transcribed by rendering pages from documents as images and pairing them with their respective text.
- Focus is on ensuring that the pre-training dataset for image recognition does not contain unsafe content, such as CSAM (sexual abuse material). Perceptual hashing approaches and internal classifiers are used to identify and remove NSFW content.
Annealing dataset is created by resampling the image-caption pairs to a smaller volume of ∼350M examples using n-grams. This selects a higher-quality data subset. The resulting data is augmented with ∼150M examples from five additional sources:
- Visual Grounding: Noun phrases in the text are linked to bounding boxes or masks in the image.
- Screenshot Parsing: Screenshots are rendered from HTML code, and the model is tasked with predicting the code that produced a specific element in the screenshot.
- Question-Answer Pairs: Question-answer pairs are included in the system, enabling the use of vast amounts of question-answering data that are too large for model finetuning.
- Synthetic Captions: Images with synthetic captions generated by an early version of the model are included. These captions provide a more comprehensive description of images than original captions.
- Synthetically-Generated Structured Images: TSsynthetically generated images for various domains are included, such as charts, tables, and math equations, accompanied by structured representations like markdown or LaTeX notation.
Architecture
Image Encoder
The image encoder is a ViT-H/14 630M trained on 2.5B image-text pairs for five epochs with resolution 224 × 224. Since Image encoders trained via a contrastive text alignment objective are unable to preserve fine-grained localization information, a multi-layer feature extraction is employed, where features from the 4th, 8th, 16th, 24th and 31st layers are also provided in addition to the final layer features.
In addition, 8 gated self-attention layers are further inserted (making a total of 40 transformer blocks) prior to pre-training of the cross-attention layers to learn alignment-specific features. The image encoder therefore eventually has a total 850M parameters with the additional layers. With the multi-layer features, the image encoder produces a 7680-dimensional representation for each of the resulting 16 × 16=256 patches. The parameters of the image encoder are not frozen during subsequent training stages.
Image Adapter
Cross-attention layers using GQA are introduced between the visual token representations produced by the image encoder and the token representations produced by the language model. The cross-attention layers are applied after every fourth self-attention layer in the core language model. The image adapter is trained in two stages:
- Initial pre-training. The image adapter is pretrained on the dataset of ∼6B image-text pairs. For compute efficiency reasons, all images are resized to fit within at most four tiles of 336 × 336 pixels each, where the tiles are arranged to support different aspect ratios, e.g., 672 × 672, 672 × 336, and 1344 × 336.
- Annealing. The image adapter is continually trained on ∼500M images from the annealing dataset. During annealing, the per-tile image resolution is increased to improve performance on tasks that require higher-resolution images, for example, infographics understanding.
Video adapter
The model takes as input up to 64 frames (uniformly sampled from a full video), each of which are processed by the image encoder. temporal structure is modeled in videos through two components:
- encoded video frames are aggregated by a temporal aggregator which merges 32 consecutive frames into one,
- additional video cross attention layers are added before every fourth image cross attention layer.
The temporal aggregator is implemented as a perceiver resampler pre-trained using 16 frames per video (aggregated to 1 frame), but the number of input frames is increased to 64 during supervised finetuning.
Post Training Data
SFT Data:
For images:
- Academic datasets are converted into question-answer pairs using templates or LLM rewriting to improve language quality.
- Human annotations are collected through multi-modal conversation data, with annotators writing conversations based on images from various domains and tasks (e.g., open-ended Q&A, captioning).
- To ensure diversity, large-scale datasets are clustered and sampled uniformly across different clusters. Additional images are acquired for specific domains by expanding a seed via k-nearest neighbors.
- Annotators use intermediate checkpoints of existing models to facilitate model-in-the-loop style annotations, allowing them to utilize model generations as a starting point and provide additional human edits.
For synthetic data:
- Text-representations of images are used with text-input LLMs to generate question-answer pairs in the text domain, replacing text representations with corresponding images.
- Examples include rendering texts from Q&A datasets as images or rendering table data into synthetic images of tables and charts. Captions and OCR extractions from existing images are also used to generate additional conversational or Q&A data.
For videos:
- Academic datasets with pre-existing annotations are converted into textual instructions and target responses, which are then converted into open-ended responses or multiple-choice options.
- Humans annotate videos with questions and corresponding answers, focusing on questions that require temporal understanding (i.e., cannot be answered based on a single frame).
Preference Data:
The dataset consists of comparisons between two different model outputs, labeled as “chosen” and “rejected”, with 7-scale ratings. The models used to generate responses are sampled from a pool of the best recent models, each with different characteristics.
The human-annotated preference data includes:
- Comparisons between two different model outputs
- Labels indicating whether one response is preferred over the other (“chosen” or “rejected”)
- 7-scale ratings for each comparison
- Optional human edits to correct inaccuracies in chosen responses
Synthetic preference pairs were also generated by using text-only LLMs to edit and introduce errors in the supervised finetuning dataset. This was done by:
- Using an LLM to introduce subtle but meaningful errors (e.g., changing objects, attributes, or calculations) in the original supervised finetuning data
- Pairing these edited responses with the original “chosen” responses as negative “rejected” samples
To create more on-policy negative samples, rejection sampling is used. This involves:
- Iteratively sampling high-quality generations from a model
- Using all generations that are not selected as negative rejected samples and additional preference data pairs
Post Training
Supervised Fine Tuning Recipe
Image: The pre-trained image adapter,and the instruction tuned language model’s weights are initialized. The language model weights are kept frozen. First, a hyperparameter sweep is run using multiple random subsets of data, learning rates and weight decay values. Next, the models are ranked based on their performance. Finally, the weights of the top-K models are averaged to obtain the final model.
Video: For video SFT, the video aggregator and cross-attention layers are initialized using the pre-trained weights. The rest of the parameters in the model, the image weights and the LLM, are initialized from corresponding models following their fine tuning stages. Similar to video pre-training, only the video parameters are fine tuned on the video SFT data. For this stage, the video length is increased to 64 frames, and an aggregation factor of 32 is used to get two effective frames. The resolution of the chunks is also increased to be consistent with the corresponding image hyperparameters.
Reward Modeling
The vision reward model (RM) is trained on top of the vision SFT model and the language RM. The vision encoder and the cross-attention layers are initialized from the vision SFT model and unfrozen during training, while the self-attention layers are initialized from the language RM and kept frozen.
The same training objective as the language RM, with a weighted regularization term added to the square of the reward logit averaged over the batch is used. This prevents the reward scores from drifting.
The same ranking (edited > chosen > rejected) as language preference data is used. Additionally negative responses are augmented synthetically by manipulating the words or phrases related to the information in the image (such as numbers or visual texts). This encourages the vision RM to ground its judgment based on the actual image content.
Direct Preference Optimization
Similar to the language model, vision adapters are also further trained with DPO. Instead of always freezing the reference model, updating it in an exponential moving average (EMA) fashion every k-steps helps the model learn more from the data, resulting in better performance in human evaluations.
Rejection Sampling
Most available question-answer pairs only contain the final answer and lack the chain-of-thought explanation that is required to train a model that generalizes well for reasoning tasks. Hence rejection sampling is used to generate the missing explanations for such examples and boost the model’s reasoning capabilities.
In some examples, despite the final answer being correct, the explanations are found to be incorrect. This pattern is observed to occur more frequently for questions where only a small fraction of the generated answers are correct. Hence questions where the probability of the answer being correct falls below a certain threshold are dropped.
Vision Experiment Results
Image Recognition Results

- The Llama 3-V 405B model outperforms GPT-4V on all benchmarks, while being slightly behind Gemini 1.5 Pro and Claude 3.5 Sonnet.
- It appears particularly competitive on document understanding tasks.
Video Recognition Results

- Llama 3 performs particularly well on video recognition given that only the 8B and 70B parameter models are evaluated.
- Llama 3 achieves its best performance on PerceptionTest, suggesting the model has a strong ability to perform complex temporal reasoning.
- On long-form activity understanding tasks like ActivityNet-QA, Llama 3 is able to obtain strong results even though it is processing only up to 64 frames, which means that for a 3-minute long video the model only processes one frame every 3 seconds.
Speech Experiments of Llama 3.1
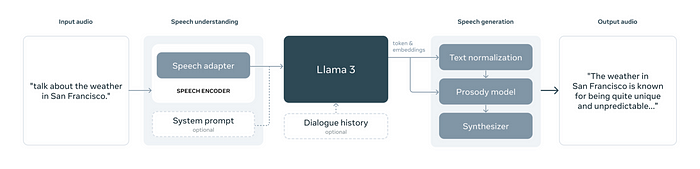
On the input side, an encoder, along with an adapter, is incorporated to process speech signals. A system prompt (in text) is used to enable different modes of operation for speech understanding in Llama 3. If no system prompt is provided, the model acts as a general-purpose spoken dialogue model which can effectively respond to the user speech in a manner that is consistent with the text-only version of Llama 3. The dialogue history is introduced as the prompt prefix to improve the multi-round dialogue experience. The speech interface of Llama 3 supports up to 34 languages. It also allows for the interleaved input of text and speech, enabling the model to solve advanced audio-comprehension tasks.
A streaming text-to-speech (TTS) system is implemented that generates speech waveforms on-the-fly during language model decoding. Speech generator for Llama 3 is based on a proprietary TTS system and the language model is not fine-tuned for speech generation. Instead, the focus is on improving speech synthesis latency, accuracy, and naturalness by leveraging Llama 3 embeddings at inference time.
Data
Speech Understanding
The training data for the large language model can be categorized into two types: pre-training data and supervised finetuning data.
Pre-training data includes approximately 15 million hours of unlabeled speech recordings from various languages. The audio data is filtered using a voice activity detection (VAD) model, with a threshold above 0.7, to select suitable samples for pre-training. Additionally, the data is checked for PII.
Supervised fine tuning data includes:
- Automatic Speech Recognition (ASR) training data: 230K hours of manually transcribed speech recordings from 34 languages.
- Artificial Speech Translation (AST) training data: 90K hours of translations in two directions (from 33 languages to English and from English to 33 languages). This data includes both supervised and synthetic data generated using the NLLB toolkit. The use of synthetic AST data helps improve model quality for low-resource languages.
- Spoken dialogue data: Synthetic responses are generated for speech prompts by asking the language model to respond to transcriptions of those prompts. This is done using a subset of the ASR dataset with 60K hours of speech. Additionally, 25K hours of synthetic data are generated by running the Voicebox TTS system on subsets of the data used to finetune Llama 3. The spoken dialogue data is selected based on several heuristics, including focusing on relatively short prompts with a simple structure and without non-text symbols, to match the distribution of speech.
Speech Understanding
The speech generation datasets consist of two main components: Text Normalization (TN) data and Prosody Model (PM) data. Both datasets are augmented with an additional feature, which is the output of the Llama 3 model’s 16th decoder layer, referred to as Llama 3 embeddings.
Text Normalization (TN) Data:
The TN training dataset consists of 55K samples. Each sample is a pair of written-form text and its corresponding normalized spoken-form text. The normalization process involves applying handcrafted rules to the written-form text. The dataset covers a wide range of semiotic classes, such as numbers, dates, and times.
Prosody Model (PM) Data:
The PM training data includes linguistic and prosodic features extracted from a 50K-hour TTS dataset. The dataset consists of paired transcripts and audios recorded by professional voice actors in studio settings.
Llama 3 Embeddings
The Llama 3 embeddings are taken as the output of the 16th decoder layer of the Llama 3 model. The 8B model is used with an empty user prompt to generate the embeddings for a given text (written-form input text for TN or audio transcript for PM). Each chunk in the Llama 3 token sequence is explicitly aligned with the corresponding chunks in the native input sequence for TN or PM (TN-specific text tokens or phone-rate features, respectively). This allows for training the TN and PM modules with streaming input of Llama 3 tokens and embeddings.
Model Architecture
Speech Understanding
The speech module consists of two parts: a speech encoder and an adapter. The output of the speech module is directly fed into the language model as token representation, allowing for direct interaction between speech and text tokens. Two new special tokens are incorporated to enclose the sequence of speech representations.
The speech encoder is a Conformer model with 1B parameters. It takes in 80-dimensional mel-spectrogram features, which are first processed by a stride-4 stacking layer followed by a linear projection to reduce the frame length to 40 milliseconds. The resulting features are then processed by an encoder with 24 Conformer layers, each consisting of two Macron-net style feed-forward networks, a convolution module with a kernel size of 7, and a rotary attention module with 24 attention heads.
The speech adapter contains about 100 M parameters. It consists of three parts: a convolution layer, a rotary Transformer layer, and a linear layer. The convolution layer has a kernel size of 3 and a stride of 2, designed to reduce the speech frame length to 80 milliseconds. This allows the model to provide more coarse-grained features to the language model. The Transformer layer has a latent dimension of 3072 and a feed-forward network with a dimension of 4096 that further processes the information from speech with context after convolutional downsampling. Finally, the linear layer maps the output dimension to match that of the language-model embedding layer.
Speech Generation
The Text Normalization (TN) module ensures semantic correctness by transforming written text into spoken form, while the Prosody Modeling (PM) module enhances naturalness and expressiveness by predicting prosodic features.
The TN module is a streaming LSTM-based sequence-tagging model that predicts the sequence of handcrafted rules used to transform input text. It also takes in Llama 3 embeddings via cross-attention to leverage contextual information, enabling minimal text token lookahead and streaming input/output. For example, the written-form text “123” would be read as “one hundred twenty three” or spelled out digit-by-digit depending on the semantic context.
The PM module is a decoder-only Transformer-based model that takes Llama 3 embeddings as an additional input. This integration leverages the linguistic capabilities of Llama 3, utilizing both its textual output and intermediate embeddings at the token rate to enhance the prediction of prosody features. The PM predicts three key prosodic features: log duration of each phone, log F0 (fundamental frequency) average, and log power average across the phone duration.
The PM model comprises a unidirectional Transformer with six attention heads, each block including cross-attention layers and dual fully connected layers with a hidden dimension of 864. A distinctive feature of the PM is its dual cross-attention mechanism, with one layer dedicated to linguistic inputs and the other to Llama embeddings. This setup efficiently manages varying input rates without requiring explicit alignment.
Training Recipe
Speech Understanding
The training process for the speech module consists of two stages: speech pre-training and supervised fine-tuning. In the first stage, speech pre-training, the model uses unlabeled data to train a speech encoder that can generalize well across languages and acoustic conditions. This is done using the BEST-RQ algorithm, which applies a mask to the input mel-spectrogram and performs nearest-neighbor search with respect to cosine similarity metric.
The second stage, supervised fine-tuning, integrates the pre-trained encoder with a language model (LLM) and trains them jointly while keeping the LLM frozen. This enables the model to respond to speech input. The training data for this stage is a mixture of ASR, AST, and spoken dialogue data, and the model is trained using labeled data corresponding to speech understanding abilities.
Speech Generation
To support real-time processing, the prosody model employs a lookahead mechanism that considers a fixed number of future phones and a variable number of future tokens. This ensures consistent look ahead while processing incoming text, which is crucial for low-latency speech synthesis applications.
A dynamic alignment strategy is developed utilizing causal masking to facilitate streamability in speech synthesis. This strategy incorporates a lookahead mechanism for a fixed number of future phones and a variable number of future tokens, aligning with the chunking process during text normalization. For each phone, the token lookahead includes the maximum number of tokens defined by the chunk size, resulting in variable lookahead for Llama embeddings but fixed lookahead for phonemes.
The Llama 3 embeddings are sourced from the Llama 3 8B model, which remains frozen during the training of the Prosody Model. The input phone-rate features include both linguistic and speaker/style controllability elements.
During inference, the same lookahead mechanism and causal masking strategy are employed to ensure consistency between training and real-time processing. The PM handles incoming text in a streaming manner, updating the input phone by phone for phone-rate features and chunk by chunk for token-rate features. The new chunk input is updated only when the first phone for that chunk is current, maintaining the alignment and lookahead as during training.
For prosody target prediction, a delayed pattern approach is used, which enhances the model’s ability to capture and reproduce long-range prosodic dependencies. This approach contributes to the naturalness and expressiveness of the synthesized speech, ensuring low-latency and high-quality output.
Speech Experiment Results
Speech recognition

- The model outperforms models that are tailored to speech like Whisper20 and SeamlessM4T on all benchmarks. On MLS English, Llama 3 performs similarly to Gemini.
Speech translation

- The performance of Llama 3 models in speech translation highlights the advantages of multimodal foundation models for tasks such as speech translation.
Text Normalization

- Using the full right context improves performance for the model without Llama 3 embeddings. However, the model that incorporates the Llama 3 embeddings outperforms all other models, hence enabling token-rate input/output streaming without relying on long context in the input.
Prosody modeling

- Llama 3 8B PM is preferred 60% of the time compared to the streaming baseline, and 63.6% of the time compared to the non-streaming baseline, indicating a significant improvement in perceived quality.
- The key advantage of the Llama 3 8B PM is its token-wise streaming capability, which maintains low latency during inference. This reduces the model’s lookahead requirements, enabling more responsive and real-time speech synthesis compared to non-streaming baselines.
Paper
Introducing Meta Llama 3: The most capable openly available LLM to date
Introducing Llama 3.1: Our most capable models to date
Recommended Reading [LLaMA Models]
Hungry for more insights?
Don’t miss out on exploring other fascinating threads in this series. Simply click here and uncover the state-of-the-art research!
Do Subscribe for weekly updates!!
