Papers Explained 186: Grok

Grok is a 314B Mixture-of-Experts model, with 25% of the weights active on a given token, modeled after the Hitchhiker’s Guide to the Galaxy, hence designed to answer questions with a bit of wit and has a rebellious streak. It will also answer spicy questions that are rejected by most other AI systems . It has real-time knowledge of the world via the 𝕏 platform.

Grok-1 displayed strong results, surpassing all other models in its compute class, including ChatGPT-3.5.
Grok 1.5
Grok-1.5 is an advancement over grok, capable of long context understanding up to 128k tokens and advanced reasoning.

Grok-1.5 can handle longer and more complex prompts, while still maintaining its instruction-following capability, In the Needle In A Haystack (NIAH) evaluation, Grok-1.5 achieved powerful perfect retrieval results for embedded text within contexts of up to 128K tokens.
Grok 1.5 V
Grok-1.5V, is the first multimodal model in the grok series. In addition to its strong text capabilities, Grok 1.5V can process a wide variety of visual information, including documents, diagrams, charts, screenshots, and photographs.

Grok 2 and Grok 2 Mini
Grok-2 is a frontier language model with state-of-the-art capabilities in chat, coding, and reasoning on par with Claude 3.5 Sonnet and GPT-4-Turbo. Grok-2 mini is a small but capable sibling of Grok-2.
On the lmsys arena Grok-2 outperforms both Claude 3.5 Sonnet and GPT-4-Turbo.
Both Grok-2 and Grok-2 mini demonstrate significant improvements over the previous Grok-1.5 model.

- * GPT-4-Turbo and GPT-4o scores are from the May 2024 release.
- † Claude 3 Opus and Claude 3.5 Sonnet scores are from the June 2024 release.
- ‡ Grok-2 MMLU, MMLU-Pro, MMMU and MathVista were evaluated using 0-shot CoT.
- § For MATH, maj@1 results are presented.
- ¶ For HumanEval, pass@1 benchmark scores are reported.
Grok 3 Beta
Grok 3 is a cutting-edge language model developed with a focus on strong reasoning and extensive pretraining knowledge. Trained on the Colossus supercluster with significantly increased compute power, it shows marked improvements in reasoning, mathematics, coding, world knowledge, and instruction-following.
- Advanced Reasoning: Utilizes large-scale reinforcement learning (RL) to refine its chain-of-thought process, enabling it to think for seconds to minutes, correct errors, explore alternatives, and deliver accurate answers. This “Think” mode allows users to inspect the model’s reasoning process.
- High Performance: Achieves leading performance on academic benchmarks and real-world user preferences, including:
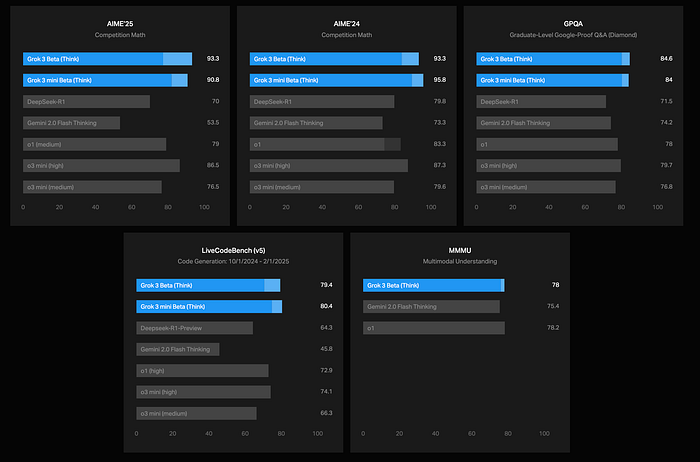

- 93.3% on the 2025 American Invitational Mathematics Examination (AIME) with highest test-time compute.
- 84.6% on graduate-level expert reasoning (GPQA).
- 79.4% on LiveCodeBench for code generation and problem-solving.
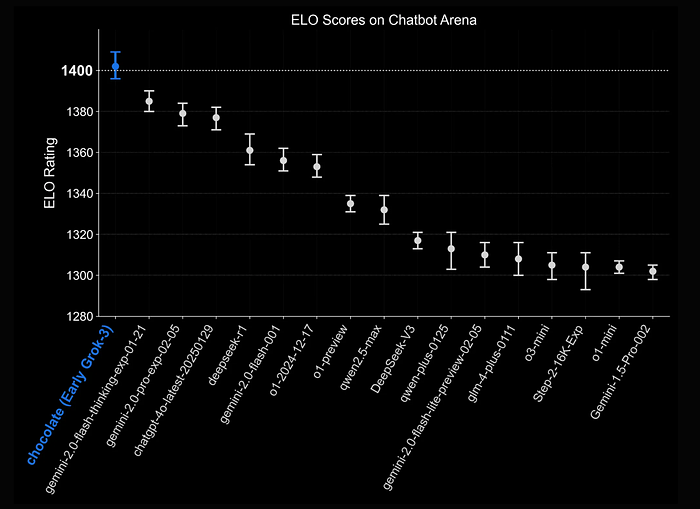
- An Elo score of 1402 in the Chatbot Arena (early version codenamed “chocolate”).
- Massive Scale Pretraining: Even without the “Think” mode, Grok 3 provides instant, high-quality responses and state-of-the-art results on benchmarks like GPQA (graduate-level science knowledge), MMLU-Pro (general knowledge), AIME (math), MMMU (image understanding), and EgoSchema (video understanding).
- Large Context Window: A 1 million token context window (8x larger than previous models) allows processing of extensive documents and complex prompts while maintaining accuracy. Achieved state-of-the-art accuracy on the LOFT (128k) benchmark for long-context RAG use cases.
- Improved Factual Accuracy and Stylistic Control: Demonstrates enhanced accuracy and control over language style.
- Grok 3 mini: A cost-efficient version for STEM tasks requiring less world knowledge, achieving 95.8% on AIME 2024 and 80.4% on LiveCodeBench.
- Grok Agents (e.g., DeepSearch): Combines reasoning with tool use, including code interpreters and internet access. DeepSearch is designed to synthesize information, reason about conflicting facts, and provide concise summaries.
Both Grok 3 and Grok 3 mini are still in training and expected to evolve rapidly with user feedback.
Hungry for more insights?
Don’t miss out on exploring other fascinating threads in this series. Simply click here and uncover the state-of-the-art research!
Do Subscribe for weekly updates!!
