Papers Explained 184: Instruction Pretraining

Instead of directly pre-training on raw corpora, Instruction Pre-Training augments each text from the raw corpora with a set of instruction-response pairs generated by an instruction synthesizer, then pre-trains LMs on the augmented corpora.

200M instruction-response pairs covering 40+ task categories are synthesized in this work to verify the effectiveness of Instruction Pre-Training.
The models are available at HuggingFace.
Instruction Synthesizer

The instruction synthesizer is developed through multitask fine-tuning on a language model. The tuning data are curated to be highly diverse, enabling the instruction synthesizer to generalize to unseen data. Furthermore, specific designs are incorporated to synthesize both one-shot and few-shot examples for subsequent pre-training.

For each context in the datasets, all the corresponding downstream tasks are gathered, the context is regarded as the raw text and the downstream tasks as the instruction-response pairs. For each dataset, a maximum of 10K examples with the highest number of instruction-response pairs are sampled, to enhance task diversity while avoiding dataset predominance.

A one-shot example consists of a raw text (TN) and a set of instruction response pairs (I_N R_N); data denoted without ′ are for tuning the instruction synthesizer, and data with ′ are for synthesizer inference and LM pre-training.

During instruction synthesizer tuning, each sequence fed into the synthesizer concatenates multiple one-shot examples sampled from the same dataset. During inference, multi round inference is conducted to synthesize instruction response pairs with patterns similar to those of previous rounds.
LM Pre-Training

Except for the pre-training data, Instruction PreTraining keeps all other pre-training settings the same as Vanilla Pre-Training: training with the next-token prediction objective and computing loss on all tokens.
General Pre-Training From Scratch
Considering the large amount of data required for general pre-training from scratch, only a part of the raw corpora is converted into instruction-augmented corpora, leaving the rest unchanged.
Domain-Adaptive Continual Pre-Training
For domain-adaptive continual pre-training, the data requirement is much smaller. Therefore, all raw corpora are converted into instruction-augmented corpora. The corpora is then mixed with the general instructions to benefit from improved prompting ability.
Experiment Settings
Instruction Synthesizer
The synthesizer is fine-tuned from Mistral-7Bv0.1. During inference, about 5 instruction-response pairs are created per raw text, where each pair contains about 52 tokens.
General Pre-Training From Scratch
Refined dataset is randomly sampled for raw pre-training corpora, consisting of 200M pieces of text containing about 100B tokens.
To create instruction-augmented corpora, two rounds of instruction synthesis is done, converting 1/5 of the raw corpora (40M raw texts) into instruction-augmented texts.
Since the fine-tuning data amount (0.2B tokens) is too small compared to that of the raw corpora, its sample ratio is increased so that it repeats 4 times throughout pre-training.
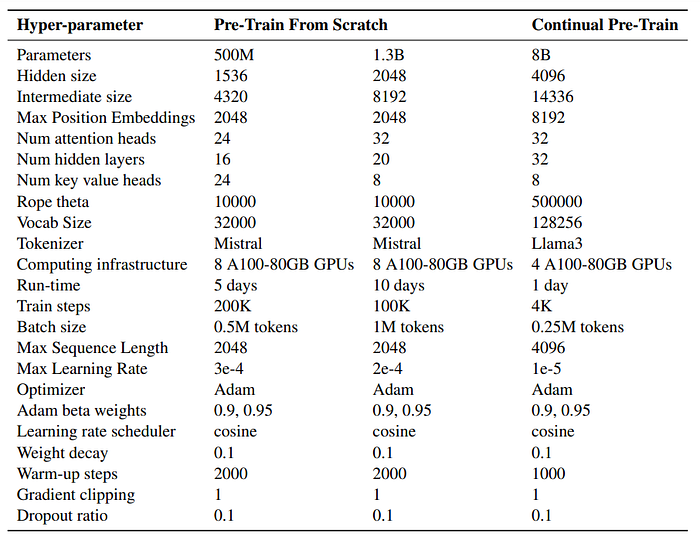
The architecture and tokenizer of Mistral is adopted to implement models of two different parameters: 500M and 1.3B.
Domain-Adaptive Continual Pre-Training
Raw corpora from two domains is used: PubMed Abstracts for biomedicine and financial news for finance. Then the instruction-augmented corpora is mixed with general instructions.
Llama3–8B is continually pretrained on each domain.
Evaluation
General Pre-Training From Scratch
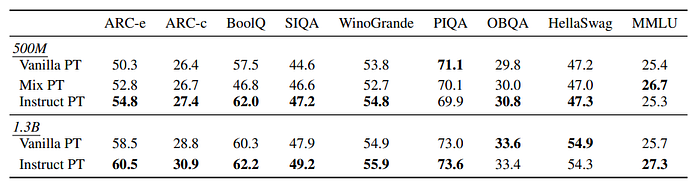
- Mix PT showed improved performance on several benchmarks compared to Vanilla PT, indicating that incorporating fine-tuning data into the pre-training process is beneficial.
- Instruct PT achieved even better performance than Mix PT, suggesting that instruction-augmented corpora further enhance model performance.
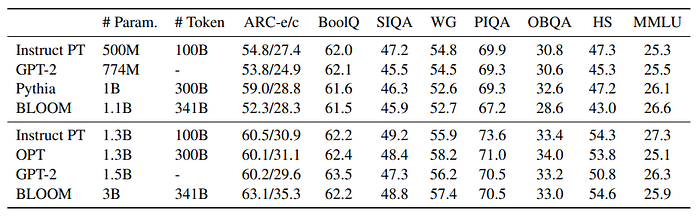
- Instruction pre-trained models matched or exceeded the performance of other open-source models (Pythia-1B and BLOOM-3B) using fewer tokens during training, demonstrating data efficiency.
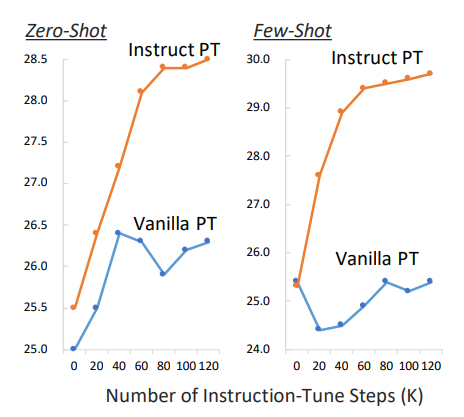
- The model pre-trained via Instruction Pre Training quickly outperforms the model pre-trained via Vanilla Pre-Training, and we observe a stable increasing trend of our model throughout the instruction tuning process.
Domain-Adaptive Continual Pre-Training
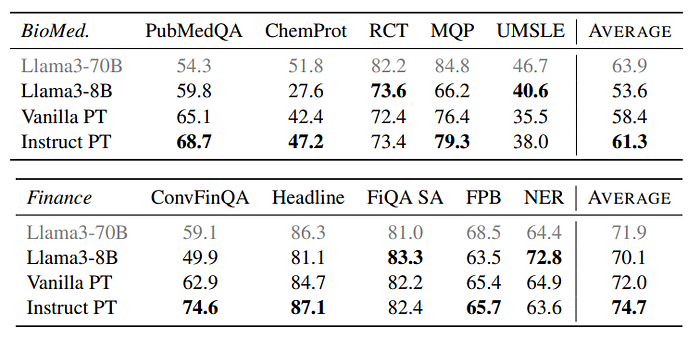
- Instruction Pre-Training consistently outperforms Vanilla Pre-Training on almost all domain-specific tasks.
- Continual pre-training with Instruction Pre-Training significantly enhances the domain specific performance of Llama3–8B, achieving parity with or even surpassing Llama3–70B.
- On the finance NER benchmark, even Llama3- 70B underperforms Llama3–8B, suggesting that this benchmark may not be reliable.
Paper
Instruction Pre-Training: Language Models are Supervised Multitask Learners 2406.14491
Hungry for more insights?
Don’t miss out on exploring other fascinating threads in this series. Simply click here and uncover the state-of-the-art research!
Do Subscribe for weekly updates!!
