Papers Explained 183: Magpie

Magpie is a self-synthesis method for generating large-scale alignment data. It is based on the observation that aligned LLMs like Llama-3-Instruct because of their auto-regressive nature can generate a user query when input only the left-side templates up to the position reserved for user messages. Magpie is then used to generate 4M instructions along with their corresponding responses.
The project is available at Github.
The models and datasets are available at HuggingFace.
Magpie : A Scalable Method to Synthesize Instruction Data

Magpie consists of two steps:
- Instruction Generation: Magpie crafts a query in a predefined template format, which defines the role of the instruction provider (e.g., user) but does not provide any instruction. The LLM then generates an instruction autonomously, and Magpie stops generating the instruction once the LLM produces an end-of-sequence token. This process is repeated to generate a set of instructions.
- Response Generation: Magpie sends these instructions to the LLM to generate the corresponding responses. Combining the roles of instruction provider and follower, the instructions from Step 1, and the responses generated in Step 2 yields the instruction dataset.
Magpie is applied to the Llama-3–8B-Instruct and Llama-3–70B-Instruct models to construct two instruction datasets: Magpie-Air and Magpie-Pro, respectively.

Extensions of Magpie
- Multi Turn Magpie: This extension involves generating multiple turns of instruction and response by appending the pre-query template to the end of the full prompt from the previous round of communication. A system prompt is used to control the behavior of the LLM and reinforce its awareness of the multi-round conversation context.
- Control Instruction Tasks of Magpie: This extension involves guiding LLMs through a system prompt to specify that it is a chatbot tailored for a particular domain and outlining the types of user queries it might encounter.
- Building Preference Optimization Dataset with Magpie: This extension involves integrating responses generated by the instruct model with those from the base model to create a preference dataset. Specifically, utilizing the reward difference (r∗ − r_base) from the FsfairX-LLaMA3-RM-v0.1 reward model.
300K instances are selected from Magpie-Pro and Magpie-Air-Filtered, yielding datasets Magpie-Pro-300K and Magpie-Air-300K-Filtered, respectively

The Output Length filter is applied last. Specifically, this filter selects the k instances of the longest responses. In the experiments, τ1 is empirically set to −12, and τ2 to 0.
Dataset Analysis
Statistical Analysis
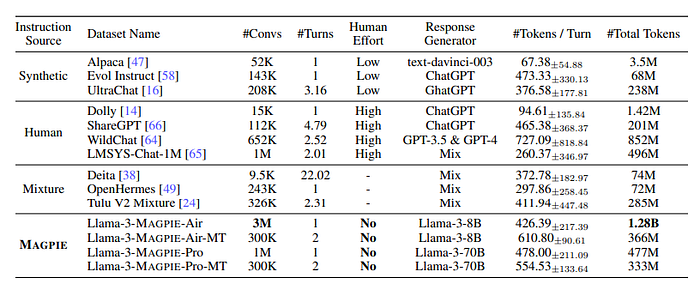
- Tokens are counted using the tiktoken library
Length Analysis
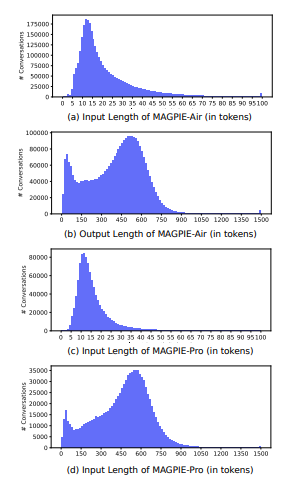
- Magpie Pro responses seem to be longer than Magpie Air.
Coverage Analysis
Used the all-mpnet-base-v2 embedding model to calculate input embeddings and employed t-SNE to project these embeddings into a two-dimensional space
Analyzed the coverage of Magpie-Pro in the embedding space using three synthetic datasets as baselines (Alpaca, Evol Instruct, and UltraChat)
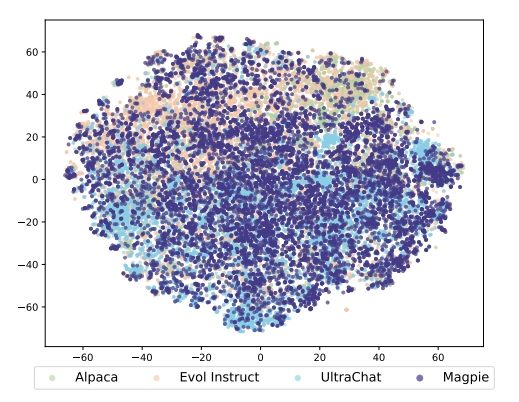
The t-SNE plot of Magpie-Pro encompasses the area covered by the other plots, demonstrating the comprehensive coverage of Magpie-Pro.
Attribute Analysis

Task Categories of Instructions
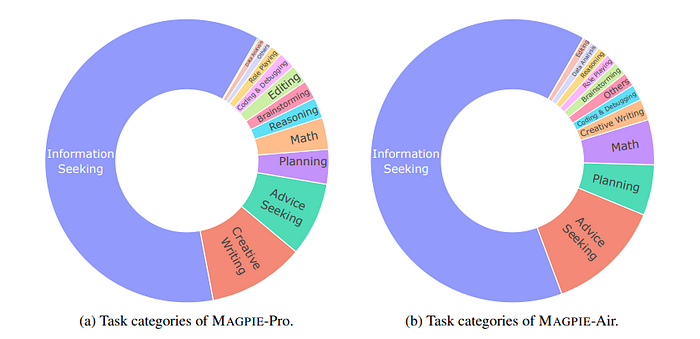
- The task category distributions of these two datasets are largely similar, however, Magpie-Pro exhibits a higher percentage of creative writing tasks.
- This distribution over the task categories aligns with the practical requests from human users.
Quality and Difficulty of Instructions
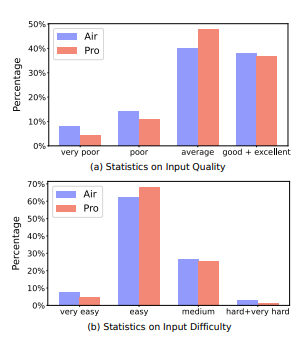
- Both datasets are of high quality, with the majority of instances rated ‘average’ or higher.
- The overall quality of Magpie-Pro surpasses that of Magpie-Air.
- The distributions across difficulty levels are similar for Magpie-Air and Magpie-Pro.
- Some instructions in MAGPIE-Pro are more challenging than those in Magpie-Air.
Instruction Similarity and Quality of Responses
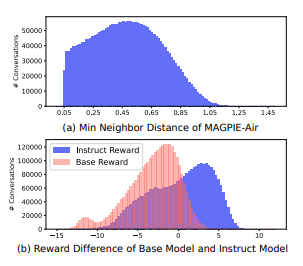
All instructions are represented in the embedding space using the all-mpnet-base-v2 embedding model
The minimum distance from each instruction to its nearest neighbors in the embedding space is calculated using Facebook AI Similarity Search (FAISS)
The reward difference for each instance in the dataset is calculated using the FsfairX-LLaMA3-RM-v0.1 reward model.
Safety Analysis

- Llama-Guard-2 is used to analyze the safety of Magpie-Air and Magpie-Pro.
- Both datasets are predominantly safe, with less than 1% of the data potentially containing harmful instructions or responses.
Performance Analysis
The quality of datasets generated by Magpie is evaluated by utilizing them to fine-tune model families including Llama-3 and Qwen1.5. The models are finetuned with a maximum sequence length of 8192 for 2 epochs.
Baselines for Instruction Tuning: ShareGPT, WildChat, Evol Instruct, UltraChat, OpenHermes, and Tulu V2 Mix.
Baselines for Instruction and Preference Tuning: UltraChat dataset (for instruction tuning) and Ultrafeedback dataset (for preference optimization)
Evaluation Benchmarks: AlpacaEval 2 and Arena-Hard.
Metrics: win rate (WR) and length-controlled win rate (LC), a debiased version of WR.
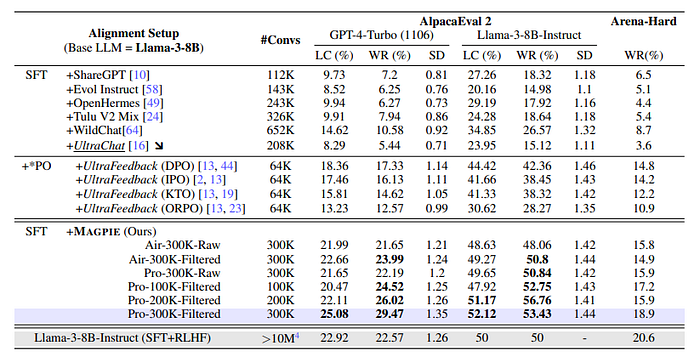
- Models fine-tuned with Magpie datasets significantly outperform those fine-tuned with baseline datasets.
- In addition, the fine-tuned models achieve comparable performance to the official aligned model, despite only undergoing SFT with a much smaller dataset.
- The models fine-tuned with Magpie consistently outperform those fine-tuned with Magpie-Air.
- As the size of the dataset increases, the performance of fine-tuned model improves, indicating that data quantity plays a critical role in enhancing instruction-following capabilities.
- Furthermore, the model fine-tuned with Magpie-Pro-300K-Filtered outperform those fine-tuned with the same amount of raw data. This demonstrates the effectiveness of our filtering technique, and underscores the importance of data quality.
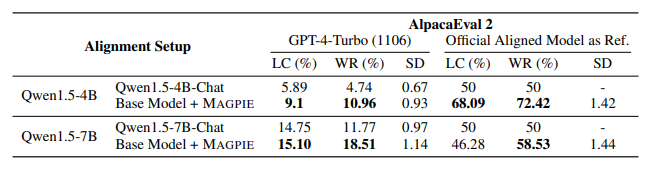
- Magpie fine-tuned models achieve better performance than the official aligned models, which have undergone instruction and preference tuning.
Paper
Magpie: Alignment Data Synthesis from Scratch by Prompting Aligned LLMs with Nothing 2406.08464
Hungry for more insights?
Don’t miss out on exploring other fascinating threads in this series. Simply click here and uncover the state-of-the-art research!
Do Subscribe for weekly updates!!
