Papers Explained 179: Obelics, Idefics

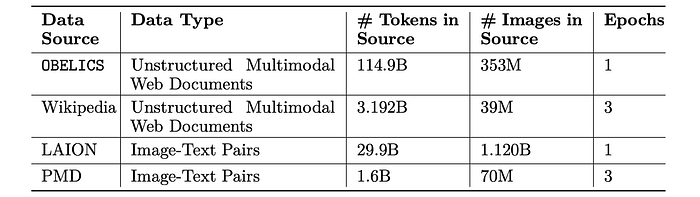
This work curates Obelics, an openly-accessible web-scale dataset consisting of 141M multimodal English web documents containing 353M associated images and 115B tokens. Obelics collects full multimodal documents interleaving text and images.
To demonstrate the viability of Obelics, an 80B multimodal model Idefics is trained which shows competitive performance against large-scale multimodal models such as Flamingo.
The models and dataset are available at HuggingFace.
Obelics Dataset Creation

Collecting of a Large Number of HTML Files
The data collection process starts by considering 25 Common Crawl dumps spanning from February 2020 to January/February 2023.
Selection of English content: a FastText classifier is applied to the extracted text, which filters out 63.6% of the documents.
Early text deduplication: MinHash deduplication is performed with 16 hashes calculated over 5-grams, without considering URL duplicates. To further refine the data, documents containing substantial proportions of repeated paragraphs and n-grams are eliminated.
Quality classification: To retain only pages containing human-written text, a logistic regression classifier is trained using curated datasets (Wikipedia and OpenWebText) as positive examples and Common Crawl samples as negative examples.
Following these steps, 1.1B documents are obtained.
Simplifying HTML Files
DOM Tree cleaning strategies To simplify the DOM trees, Line breaks (<br>) are converted into actual line breaks. Multiple consecutive line breaks and spaces are condensed into a single instance. HTML comments are removed from the DOM tree. Empty leaves and unnesting nodes are eliminated using recursive processes. When a parent node lacks attached text and has only one child, the child node replaces the parent node in the DOM hierarchy.
Tag unwrapping This operation involves removing unnecessary styling applied to displayed text by unwrapping a predefined set of tags : a, abbr, acronym, b, bdi, bdo, big, cite, code, data, dfn, em, font, i, ins, kbd, mark, q, s, samp, shadow, small, span, strike, strong, sub, sup, time, tt, u, var, wbr.
Node removal The tags which define the document’s structure are retained: address, article, aside, blink, blockquote, body, br, caption, center, dd, dl, dt, div, figcaption, h, h1, h2, h3, h4, h5, h6, hgroup, html, legend, main, marquee, ol, p, section, summary, title, ul. The tags that define media elements are also preserved: audio, embed, figure, iframe, img, object, picture, video. Furthermore, the source tag is retained as it may contain an interesting attribute.
Modification of specific nodes Modification is performed on some <div> nodes that contain footer, header, navigation, nav, navbar, or menu as ID or date as attribute, as well as CSS rules that possess footer or site-info as class. These nodes typically contain website navigation content or article dates and are therefore removed. The presence of a CSS rule with the class “more-link” is detected to indicate a new topic within the webpage, and these nodes are replaced with an end-of-sentence (EOS) token during training.
Extracting Multimodal Web Documents
Preservation of the original structure of the web pages The texts and image links are extracted while maintaining their order of appearance in the DOM tree.
Filtering Multimodal Web Documents
The filtering process consists of two steps. In the first step, filtering occurs at the node level for images and at the paragraph level for text. The second step is conducted at the document level.
Node-level image filtering Images are discarded if they have formats other than jpg, png, or webp; side lengths outside the range 150–20,000 pixels; or aspect ratios greater than 2 or less than ½. Additionally, images with URLs containing specific sub-strings (logo, button, icon, plugin or widget) are removed.
Paragraph-level text filtering Discarding paragraphs if they have fewer than 4 words. Removing paragraphs with high repetition ratio (indicating potential spam content). Filtering out paragraphs with excessive special characters. Excluding paragraphs with low stop word ratio (indicating machine-generated or nonsensical content). Removing paragraphs with low punctuation ratio (indicating poor-quality text). Filtering out paragraphs with high flagged word ratio (associated with adult or inappropriate content). Using KenLM models (trained on Wikipedia) to filter out paragraphs with excessively high perplexity scores. Creating a list of frequently used words and filtering out paragraphs with excessive proportions of these words
Document-level filtering Documents are removed if they have no images or more than 30 images. Text filters at the paragraph level are also applied.
After these filtering steps, 365M web documents and 1.4B images are obtained.
Additional Filtering and Deduplication Steps
Exclusion of opted-out images To respect the preferences of content creators, Images for which creators explicitly opted out of AI model training are removed, with the help of Spawning API.
Image deduplication based on URL Images that appear more than 10 times across the entire dataset are removed.
NSFW image removal NSFW (Not Safe For Work) images and documents containing such images are removed, as well as URLs with sub-strings like “porn”, “sex”, or “xxx”.
Document deduplication based on URL Documents with the same URL are reduced to a single most recent document.
Document deduplication based on the set of images Documents with identical sets of images, regardless of URL or domain name (for instance, news articles copied and pasted multiple times across various sources), are reduced to a single most recent document.
Paragraph deduplication across documents of the same domain names Generic spam phrases (e.g., “Share on Facebook”, “Post a comment,” or “Accept the cookies,”) are removed from documents sharing the same domain name by identifying repetitive paragraphs and removing them.
After all these steps, the final dataset contains 141M documents and 353M images, of which 298M are unique.
Idefics
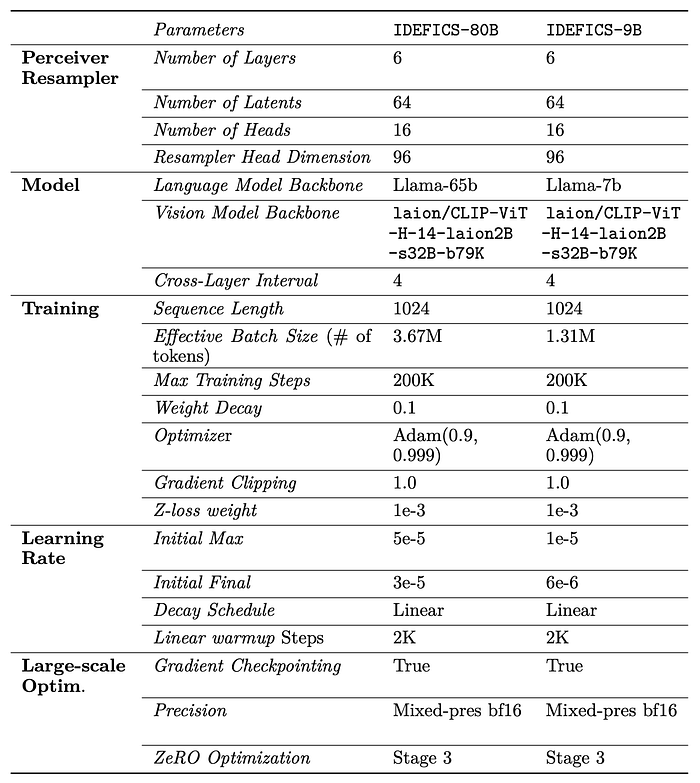
The model closely follows Flamingo architecture and is formed by combining a pre-trained image encoder, a pre-trained language model, and newly initialized parameters in the form of Perceiver blocks and Transformer-based cross-attentions blocks inserted within the language model every 4 layers.

LLaMA and OpenCLIP are used for the language backbone and the vision backbone respectively. The pre-trained backbones are frozen during the training, and only the new parameters are updated along with the embeddings of additional tokens.
A layer normalization is applied on the projected queries and keys of both the Perceiver and cross-attention blocks, which improved training stability in the early experiments. The RMSNorm implementation for the layer normalization is used.
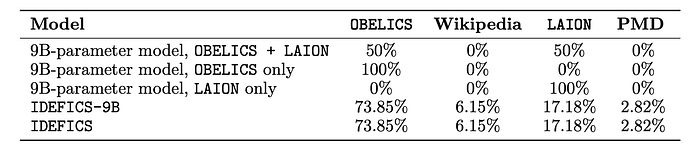
The four runs conducted have distinct data mixtures as follows
Evaluation
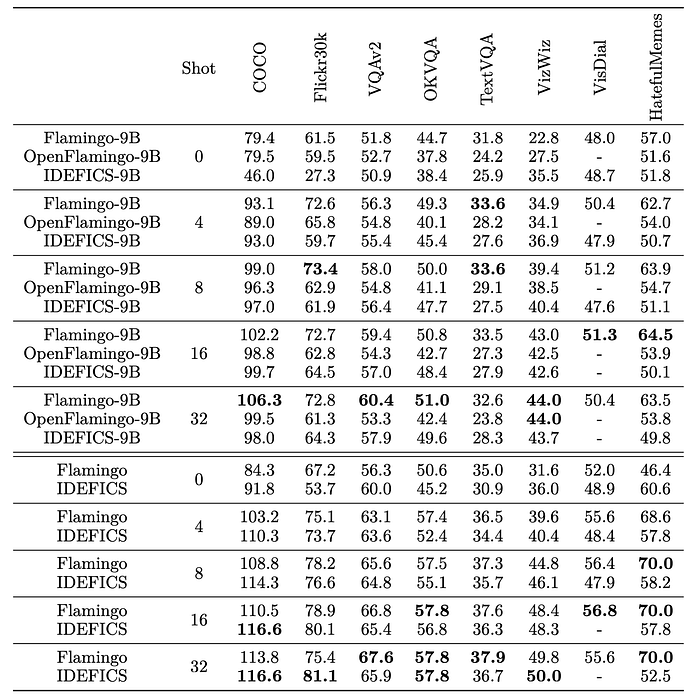
- Idefics is often on par with Flamingo on various multimodal benchmarks.
- Out of the 8 evaluation tasks, with 32 in-context examples, it either performs better or obtain the same result as Flamingo on 4 of them. At the 9 billion parameter scale, we are still behind Flamingo-9B.
- It outperforms OpenFlamingo-9B, which was trained on mmc4, in terms of aggregated performance.
Paper
OBELICS: An Open Web-Scale Filtered Dataset of Interleaved Image-Text Documents 2306.16527
Recommended Reading [Datasets] [Multi Modal Transformers]
Hungry for more insights?
Don’t miss out on exploring other fascinating threads in this series. Simply click here and uncover the state-of-the-art research!
Do Subscribe for weekly updates!!
