Papers Explained 178: Docmatix

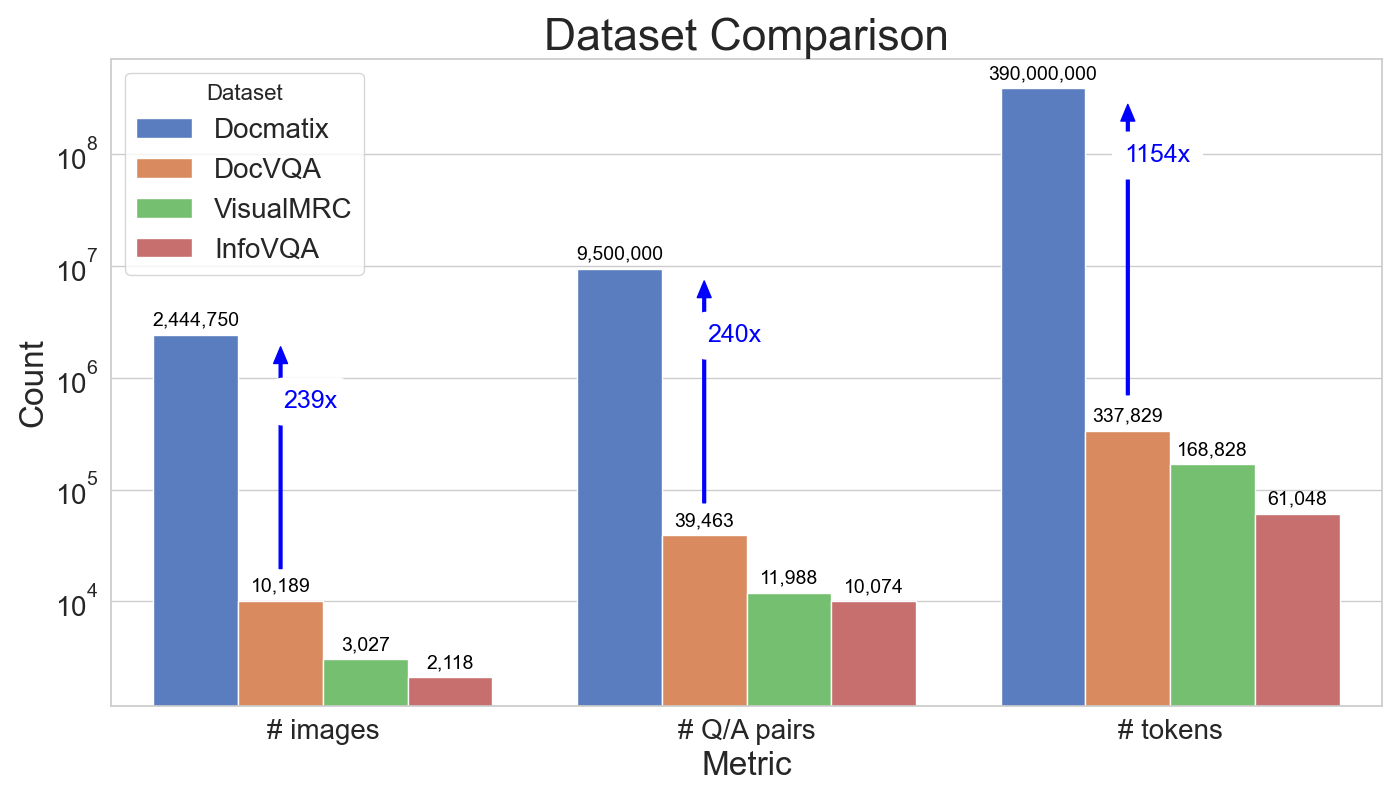
Docmatix is a large-scale dataset for Document Visual Question Answering (DocVQA) that is hundreds of times larger than previously available datasets. The dataset contains 2.4 million images and 9.5 million question-answer pairs derived from 1.3 million PDF documents, which is a 240X increase in scale compared to previous datasets.
The dataset is available at HuggingFace.
The dataset was generated by taking transcriptions from the PDFA OCR, an extensive OCR dataset containing 2.1M PDFs. The Phi-3-small model is used to generate Q/A pairs based on the transcripts. The generations were filtered to remove 15% of the Q/A pairs identified as hallucinations, ensuring the dataset’s quality. The dataset contains a row for each PDF document, which was converted to an image at a resolution of 150 dpi.

Ablation studies were performed to optimize the prompts, aiming to generate around four pairs of Q/A per page, with answers that are human-like and questions that prioritize diversity and minimal repetition. When the Phi-3 model was guided to ask questions based on the specific information in the document, the questions showed very few repetitions. The following plot presents some key statistics from the analysis:

To evaluate Docmatix’s performance, ablation studies were conducted using the Florence-2 model. Two versions of the model were trained: one on the DocVQA dataset and another on a small portion of Docmatix (20% of images and 4% of Q/A pairs) followed by training on DocVQA to ensure correct format for evaluation.

The results show a relative improvement of almost 20% when training on this small portion of Docmatix.
Additionally, the 0.7B Florence-2 model performed only 5% worse than the 8B Idefics2 model trained on a mixture of datasets and is significantly larger.
Paper
Docmatix — A huge dataset for Document Visual Question Answering
Recommended Reading [Datasets] [Document Information Processing]
Hungry for more insights?
Don’t miss out on exploring other fascinating threads in this series. Simply click here and uncover the state-of-the-art research!
Do Subscribe for weekly updates!!
