Papers Explained 176: Smol LM

SmolLM is a series of state-of-the-art small language models available in three sizes: 135M, 360M, and 1.7B parameters. These models are built on a meticulously curated high-quality training corpus, which we are releasing as SmolLM-Corpus. Smollm Corpus includes:
- FineWeb-Edu (deduplicated): educational web samples from FineWeb (220B tokens)
- Cosmopedia v2: A collection of synthetic textbooks and stories generated by Mixtral (28B tokens)
- Python-Edu: educational Python samples from The Stack (4B tokens)
The models and dataset are available at HuggingFace.
Recommended Reading [Cosmopedia] [FineWeb]
Data Curation
FineWeb-Edu

FineWeb-Edu is a dataset released along with FineWeb. It consists of 1.3T tokens of educational web pages filtered from the FineWeb dataset. An educational quality classifier is developed using annotations generated by Llama3–70B-Instruct, which is then used to retain only the most educational web pages from FineWeb.
In Smollm-Corpus 220B deduplicated tokens from FineWeb are used.
Cosmopedia v2
Cosmopedia v2 is an enhanced version of Cosmopedia, a synthetic dataset for pre-training, which consists of over 30 million textbooks, blog posts, and stories generated by Mixtral-8x7B-Instruct-v0.1.
To improve the prompts, two strategies were tried:
- Using more capable models with the same prompts, but no significant improvements were found.
- Optimizing the prompts themselves
The final dataset consisted of 39 million synthetic documents consisting of 28B tokens of textbooks, stories, articles, and code, with a diverse range of audiences and over 34,000 topics.
Python-Edu

The idea of FineWeb-Edu was applied to Code. The Stack dataset’s 500,000 Python samples were annotated using Llama3, and they were used to train an educational classifier. This classifier was trained on the StarCoder models training corpus’ Python subset. A refined dataset of 4 billion tokens was obtained by retaining only the samples with a score of 4 or higher from the available 40 billion Python tokens.
Training

SmolLM models are trained on the data mixture below:
- 135M and 360M models, each trained on 600B tokens from Smollm-Corpus
- 1.7B model, trained on 1T tokens from Smollm-Corpus

For the architecture of the 135M and 360M parameter models,a design similar to MobileLLM is adopted, incorporating Grouped-Query Attention (GQA) and prioritizing depth over width.
The 1.7B parameter model uses a more traditional architecture.
For all three models, embedding tying is used and have a context length of 2048 tokens. A tokenizer trained on the Smollm Corpus with a vocab size of 49152 is used.
The models were instruction tuned using publicly available permissive instruction datasets.
- All three models were trained for one epoch on the permissive subset of the WebInstructSub dataset, combined with StarCoder2-Self-OSS-Instruct.
- Direct Preference Optimization (DPO) was performed for one epoch.
- HelpSteer was used for the 135M and 1.7B models
- argilla/dpo-mix-7k was used for the 360M model.
Evaluation


- SmolLM-135M outperforms the current best model with less than 200M parameters, MobileLM-125M, despite being trained on only 600B tokens compared to MobileLM’s 1T tokens.
- SmolLM 360M outperforms all models with less than 500M parameters, despite having fewer parameters and being trained on less than a trillion tokens (600B) as opposed to MobileLM-350M and Qwen2–500M.
- SmolLM-1.7B outperforms all other models with less than 2B parameters, including Phi1.5 from Microsoft, MobileLM-1.5B, and Qwen2–1.5B.
- SmolLM-1.7B shows strong Python coding performance with 24 pass@1. Note that the evaluation score for Qwen2–1.5B is different from the 31.1 pass@1 reported by the Qwen team.
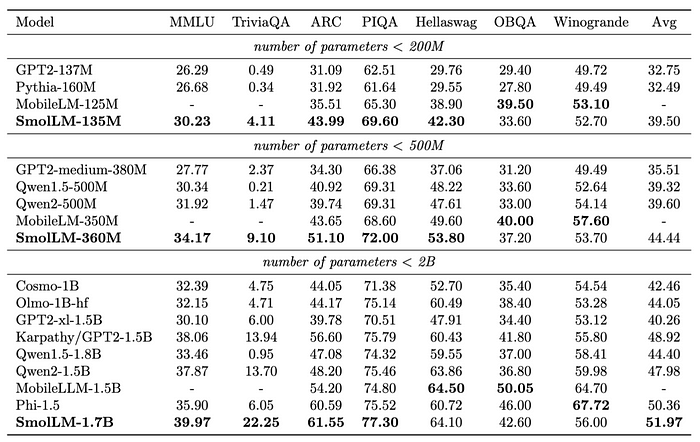
- SmolLM models outperform other models in their size categories across a diverse set of benchmarks, testing common sense reasoning and world knowledge.
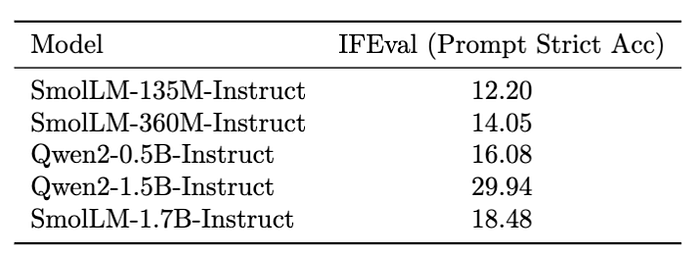
- Qwen2–1.5B-Instruct model scores the highest with 29.94, SmolLM-Instruct models provide a good balance between model size and performance, using only publicly available permissive datasets.
SmolLM v0.2
v0.2 models are better at staying on topic and responding appropriately to standard prompts, such as greetings and questions about their role as AI assistants. SmolLM-360M-Instruct (v0.2) has a 63.3% win rate over SmolLM-360M-Instruct (v0.1) on AlpacaEval.
V0.1 models were fine-tuned on the permissive subset of the WebInstructSub dataset, combined with StarCoder2-Self-OSS-Instruct. Then, DPO was performed for one epoch on HelpSteer for the 135M and 1.7B models, and argilla/dpo-mix-7k for the 360M model.
V0.2 models are trained on everyday-conversations-llama3.1–2k, Magpie-Pro-300K-Filtered, StarCoder2-Self-OSS-Instruct, and a small subset of OpenHermes-2.5.
SmolLM v2
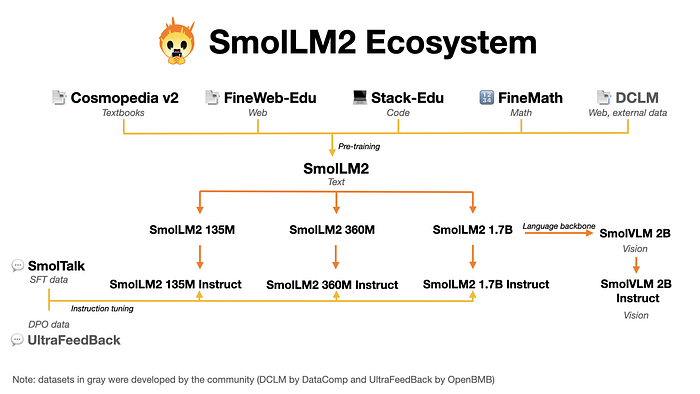
SmolLM2 is a family of compact language models and the updated versions of SmolLM offered in three sizes: 135M, 360M, and 1.7B parameters.
The models are available at HuggingFace.
The model is initially pre-trained on this massive dataset (11 trillion tokens for the 1.7B parameter model, 4 trillion for the 360M model, and 2 trillion for the 135M model) using a next-word prediction objective. The pre-training corpus for SmolLM, including Cosmopedia v0.2, FineWeb-Edu, Stack-Edu, FineMath and DCLM.
Following pre-training, the model undergoes SFT using a combination of public and curated datasets called Smol Talk. DPO is applied using UltraFeedback dataset


Smol Talk
The Smol Talk mix consists of:
- Smol-Magpie-Ultra: the core component of the mix, consisting of 400K samples generated using the Magpie pipeline with /Llama-3.1–405B-Instruct. This dataset is heavily curated and filtered compared to the original Magpie-Pro pipeline. SmolLM models trained on this dataset alone outperform those trained on popular public datasets like OpenHermes and Magpie Pro across key benchmarks including IFEval and MT-Bench.
- Smol-contraints: a 36K-sample dataset that trains models to follow specific constraints, such as generating responses with a fixed number of sentences or words, or incorporating specified words in the output. The dataset has been decontaminated against IFEval to prevent overlap.
- Smol-rewrite: an 50k-sample collection focused on text rewriting tasks, such as adjusting tone to be more friendly or professional. Note that Smol-Magpie-Ultra also includes some rewriting, editing, and summarization examples.
- Smol-summarize: an 100k-sample dataset specialized in email and news summarization.
- OpenHermes2.5: 100k samples from OpenHermes2.5 were added since it helps preserve and boost benchmarks such as MMLU and WinoGrande, and BBH.
- MetaMathQA: 50k random samples were added to improve the model on mathematics and reasoning.
- NuminaMath-CoT: this dataset helps on mathematics, especially hard problems found in benchmarks such as MATH.
- Self-Oss-Starcoder2-Instruct: this dataset is used to improve coding capabilities.
- SystemChats2.0: 30k samples from the SystemChat-2.0 dataset were added to make the model support a variety of system prompt formats.
- LongAlign: English samples (with less than 16k tokens) from the LongAlign-10k dataset were added to train with a 8192 sequence to prevent the model from losing long context abilities beyond 2048 tokens when finetuned on only short samples.
Everyday-conversations: this dataset includes multi-turn everyday conversations such as greeting and was used in SmolLM v1 post-training. - APIGen-Function-Calling: 80k samples from apigen-function-calling which is a mix of Synth-APIGen-v0.1 and xlam-function-calling-60k datasets were used.
- Explore-Instruct-Rewriting: 30k samples from this rewriting dataset were added.
The dataset is available at HuggingFace.
SmolVLM
SmolVLM is a family of 2B parameter vision-language models designed for efficiency and ease of deployment. It builds upon the architecture and training techniques of Idefics3, but with key modifications.
The models are available at HuggingFace.
- Llama 3.1 8B is replaced with SmolLM2 1.7B as the language backbone.
- The patched visual information is more aggressively compressed by reducing the information 9x using the pixel shuffle strategy, compared to 4x with Idefics3.
- Patches of 384x384 are used, instead of 364x364, because 384 is divisible by 3, which is necessary for the pixel shuffle strategy to work.
- The vision backbone is changed to use shape-optimized SigLIP with patches of 384x384 pixels and inner patches of 14x14.

SmolLM2’s pre-training context window is insufficient for VLMs. Images are encoded into many tokens, and multiple images were desired to be supported. To address this, the context is extended to 16k tokens by increasing the RoPE base value from 10k to 273k. The model is fine-tuned on a mixture of long- and short-context datasets. For long-context datasets, the “books” subset of Dolma (primarily Project Gutenberg) and code documents with 8k+ tokens from The Stack are used, each contributing 20% to the final mixture. For short-context datasets, the original SmolLM2 pre-training mix is streamlined to include 20% FineWeb-Edu, 20% DCLM, and 20% from a math dataset (to be released soon). The math dataset is upsampled to mitigate a performance drop observed on GSM8k during the context extension process.

Jan 2025:
SmolVLM-256M and SmolVLM-500M, two new smaller VLMs are released. Despite their size, these models achieve impressive performance on various tasks, including captioning, document Q&A, and basic visual reasoning. The 500M model offers a performance boost over the 256M version and increased robustness to prompting. Both outperform the Idefics 80B model from 17 months prior.
These models are available at HuggingFace.
Vision Encoder: Uses a smaller SigLIP base patch-16/512 (93M parameters) instead of the larger SigLIP 400M SO, offering comparable performance with a smaller footprint and enabling higher image resolution processing.
Larger Image Resolution: Inspired by Apple MM1 and Google Pali Gemma2, the vision encoder processes images at a larger resolution, improving visual understanding.
Data mixture: Similarly to a previous release, The Cauldron and Docmatixare used , with the addition of MathWriting to the mix. The proportions of the datasets is adjusted to place a stronger emphasis on document understanding (41%) and image captioning (14%), while still maintaining a balanced focus on other essential areas such as visual reasoning, chart comprehension, and general instruction following.
Tokenization Optimizations: Pixel shuffle is increased, with new models encoding images at a rate of 4096 pixels per token, compared to 1820 pixels per token in the 2B model.
To optimize tokenization further, special tokens are added to represent sub-image separators in a more efficient way. This means that now instead of a string like <row_1_col_1> being mapped to 7 tokens, it is mapped to a single token. As any strings up to <row_6_col_6>. This led to a sizeable improvement in the model’s stability during training and quality of the results.

Paper
SmolLM — blazingly fast and remarkably powerful
SmolVLM — small yet mighty Vision Language Model
SmolVLM Grows Smaller — Introducing the 250M & 500M Models!
Recommended Reading [Small LLMs]
Hungry for more insights?
Don’t miss out on exploring other fascinating threads in this series. Simply click here and uncover the state-of-the-art research!
Do Subscribe for weekly updates!!
