Papers Explained 175: Cosmopedia

Cosmopedia aims to reproduce the training data used for Phi-1.5. It is a dataset of synthetic textbooks, blog posts, stories, posts, and WikiHow articles generated by Mixtral-8x7B-Instruct-v0.1. It contains over 30M files and 25B tokens
The model and dataset are available at HuggingFace and the code is available on GitHub.
Prompt Curation
Cosmopedia contains over 30 million prompts, spanning hundreds of topics and achieving less than 1% duplicate content.
Two approaches are combined to build Cosmopedia’s prompts: conditioning on curated sources and conditioning on web data. The source of data that is conditioned on is referred to as “Seed Data”.

Curated Sources

Educational resources from reputable sources like Stanford courses, Khan Academy, OpenStax, and WikiHow are used. Outlines are extracted from these resources and prompts are constructed that ask the model to generate textbooks for individual units within those courses.
However, this approach has limitations due to scalability issues. The number of unique units available in each source is limited. To overcome this limitation, specific instructions are provided on how the format and content should differ. By targeting four different audiences (young children, high school students, college students, researchers) and leveraging three generation styles (textbooks, blog posts, wikiHow articles),12 times more prompts can be generated
Web Data

The above approach still has limitations due to the small volume of resources available, hence web data is used to construct prompts, contributing to 80% of the cosmopedia data.
Millions of web samples are clustered into 145 clusters and each cluster’s topics are identified by analyzing 10 random samples from each cluster. The topics were then inspected and content deemed of low educational value was removed (e.g., explicit adult material, celebrity gossip, obituaries). A total of 112 topics were retained.
Prompts are then built by instructing the model to generate a textbook related to a web sample within the scope of its topic cluster. To enhance diversity and account for potential incompleteness in topic labeling, the prompts were conditioned on the topic only 50% of the time. Additionally, the audience and generation styles were changed as explained earlier. As a result, approximately 23 million prompts are built using this approach.
Instruction datasets and stories

In the initial assessments it is found that models trained using generated textbooks lacked common sense and fundamental knowledge typical of grade school education. To address this issue, stories are created that incorporate day-to-day knowledge and basic common sense by using texts from two instruction-tuning datasets as seed data for prompts: UltraChat and OpenHermes2.5. The UltraChat dataset includes a “Questions about the world” subset that covers 30 meta-concepts about the world, while the OpenHermes2.5 dataset is diverse and high-quality, but certain sources and categories that were not suitable for storytelling, such as glaive-code-assist for programming and camelai for advanced chemistry are omitted.
Technical Stack
Topics clustering

The text-clustering repository is used to implement the topic clustering for the web data used in Cosmopedia prompts. Additionally, Mixtral is asked to give the cluster an educational score out of 10 in the labeling step to help in the topics inspection step.
Textbooks generation at scale
The llm-swarm library is used to generate 25B tokens of synthetic content using Mixtral-8x7B-Instruct-v0.1. This is a scalable synthetic data generation tool using local LLMs or inference endpoints on the Hugging Face Hub. It supports TGI and vLLM inference libraries.
Benchmark decontamination
With synthetic data, there is a possibility of benchmark contamination within the seed samples or the model’s training data. To address this, potentially contaminated samples are identified using a 10-gram overlap. After retrieving the candidates,difflib.SequenceMatcher is used to compare the dataset sample against the benchmark sample. If the ratio of len(matched_substrings) to len(benchmark_sample) exceeds 0.5, the sample is discarded.
This decontamination process is applied across all benchmarks evaluated with the Cosmo-1B model, including MMLU, HellaSwag, PIQA, SIQA, Winogrande, OpenBookQA, ARC-Easy, and ARC-Challenge.
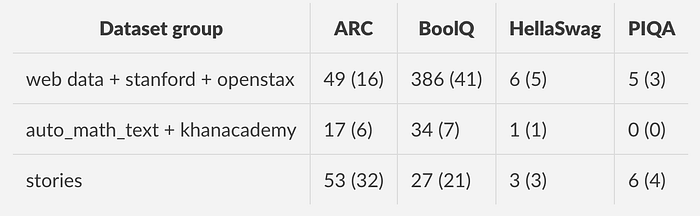
Training stack
A 1B LLM using Llama2 architecture is trained on Cosmopedia to assess its quality:
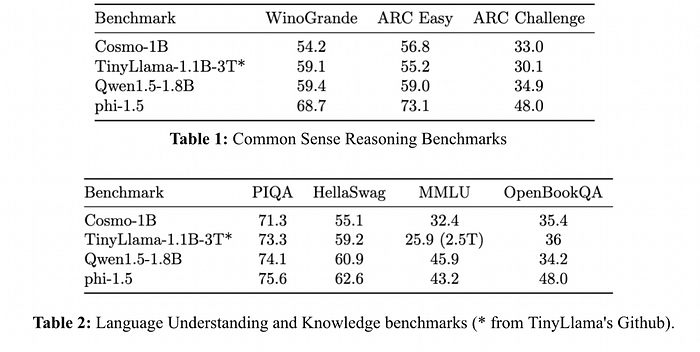
- The model performs better than TinyLlama 1.1B on ARC-easy, ARC-challenge, OpenBookQA, and MMLU and is comparable to Qwen-1.5–1B on ARC-challenge and OpenBookQA.
- However, we notice some performance gaps compared to Phi-1.5, suggesting a better synthetic generation quality, which can be related to the LLM used for generation, topic coverage, or prompts.
Cosmopedia V2
Cosmopedia v2 is an enhanced version of Cosmopedia, a synthetic dataset for pre-training, which consists of over 30 million textbooks, blog posts, and stories generated by Mixtral-8x7B-Instruct-v0.1.
To improve the prompts, two strategies were tried:
- Using more capable models with the same prompts, but no significant improvements were found.
- Optimizing the prompts themselves
For the first strategy, llama3–70B-Instruct, Mixtral-8x22B-Instruct-v0.1, and Qwen1.5–72B-Chat were tried but no significant improvements were found when models were trained on textbooks generated by these alternatives.
The search for better topics and seed samples
Instead of the unsupervised clustering approach used in v1, a predefined list of 34,000 topics from the BISAC book classification is used. BISAC is a standard used to categorize books by subject that is both comprehensive and educationally focused.
A search tool is implemented to retrieve the most relevant pages for each topic from the FineWeb CC-MAIN-2024–10 and CC-MAIN-2023–50 dumps. For each query 1000 pages are retrieved, resulting into 34 million web pages across 34,000 topics.
Generation Style
Textbooks with the same web textbook prompts but targeted two different audiences: middle school students and college students are generated. It is found that models trained on textbooks aimed primarily at middle school students gave the best score on all benchmarks except MMLU. This can be explained by the fact that most of these test basic common sense and elementary to intermediate science knowledge, while MMLU contains some questions that require advanced knowledge and expertise.
Therefore for v2 40% of the content is generated for middle school students, 30% for college students and 30% as a mix of other audiences and styles including subsets borrowed from Cosmopedia v1 such as stories and Stanford courses based textbooks. Additionally, 1B code textbooks are generated based on Python seed samples from AutoMathText dataset.
Ultimately 39M synthetic documents consisting of 28B tokens of textbooks, stories, articles, and code, with a diverse range of audiences and over 34,000 topics are generated.
Paper
Cosmopedia: how to create large-scale synthetic data for pre-training
Cosmopedia v2: SmolLM — blazingly fast and remarkably powerful
Recommended Reading [Datasets]
Hungry for more insights?
Don’t miss out on exploring other fascinating threads in this series. Simply click here and uncover the state-of-the-art research!
Do Subscribe for weekly updates!!
